Goroutine はなぜ軽量スレッドと称されるのか
- Authors

- Name
- ごとれん
- X
- @ren510dev
目次
- 目次
- はじめに
- 「並行」と「並列」は違う
- 時間軸
- 構成と実行
- リソースの割り当てと切り替え
- プロセス
- スレッド
- コンテキストスイッチ
- 処理方式
- Iterative Server
- Concurrent Server
- マルチスレッド
- Goroutine
- 概要
- 特徴
- Goroutine の位置付け
- Go ランタイムは "ミニ OS"
- Goroutine の適切な数
- runtime/proc.go
- まとめ
- 参考・引用

はじめに
Go を書いたことがある人なら、Goroutine というワードを耳にしたことがあるかと思います。 Goroutine とは、Go で並行処理を実現するための軽量なスレッドのことです。 Goroutine は一般的なカーネルスレッドと比較して、非常に軽量かつ効率的なスケジューリングが可能です。
今回のブログでは、Go ランタイムの仕組みを覗き Goroutine が 軽量スレッド と呼ばれる理由についてまとめてみたいと思います。
「並行」と「並列」は違う
前提としてコンピュータの世界における「並行」と「並列」は違う、という点について述べておきたいと思います。
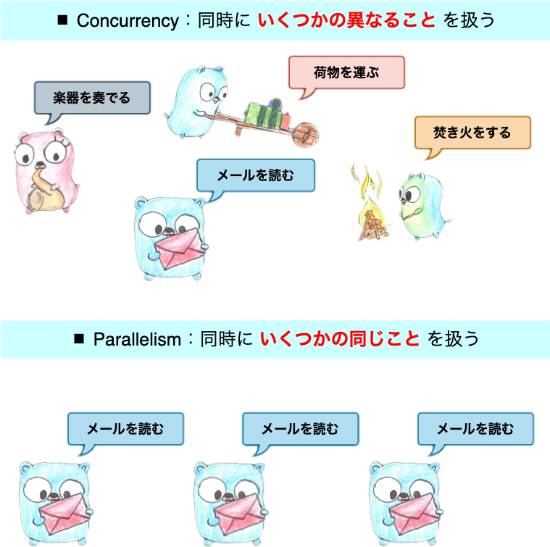
並行(Concurrency) と 並列(Parallelism) はコンピューティングにおける概念で、どちらも複数のタスクを同時に処理することを指していますが、具体的なアプローチと動作は異なります。
両者は異なる概念であり、一緒にされるべきではありません。
並行処理 は、複数のタスクを同時進行のように実行する処理形態で、タスクは交互に実行されます。 他方の 並列処理 は、実際に複数のタスクが物理的に同時に実行される処理形態で、複数の CPU コアやプロセッサを利用します。
Goroutine は並行処理(Concurrency)を実現する 仕組みになります。
| 特徴 | 並行処理(Concurrency) | 並列処理(Parallelism) |
|---|---|---|
| 実行方法例 | 一つの CPU がタスクリストを迅速に切り替える | 複数の CPU コアが同時に異なるタスクを実行 |
| 目的 | 複数のタスクを同時進行して見せる | 複数のタスクを同時に実行する |
| リソース | 単一リソースを共有 | 複数のリソースを使用 |
| 適用例 | マルチタスキング、I/O 待ちの最適化 | 科学計算、ビッグデータ解析 |
時間軸
- 並行処理:ある時間の 『範囲』 において、複数のタスクを扱うこと
- 並列処理:ある時間の 『点』 において、複数のタスクを扱うこと
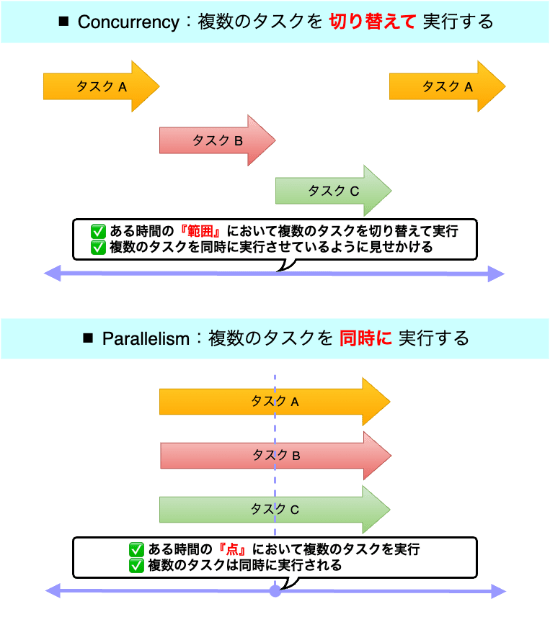
書籍:Linux System Programming, 2nd Edition Chap.7 でも "時間" という観点での違いが言及されています。
Concurrency is the ability of two or more threads to execute in overlapping time periods.
Parallelism is the ability to execute two or more threads simultaneously.
並行処理は、複数個のスレッドを共通の期間内で実行する能力のことです。
並列処理は、複数個のスレッドを同時に実行する能力のことです。
構成と実行
- 並行処理:複数の処理を独立に実行できる 構成 のこと
- 並列処理:複数の処理を同時に 実行 すること
Go 公式ブログの The Go Blog - Concurrency is not parallelism の記事の中でも、並行と並列は異なる概念であることが述べられています。
In programming, concurrency is the composition of independently executing processes, while parallelism is the simultaneous execution of (possibly related) computations. Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
プログラミングにおいて、並列処理は(関連する可能性のある)処理を同時に実行することであるのに対し、並行処理はプロセスをそれぞれ独立に実行できるような構成のことを指します。 並行処理は一度に多くのことを「扱う」ことであり、並列処理は一度に多くのことを「行う」ことです。
リソースの割り当てと切り替え
プロセス
プロセスとは、OS とユーザインターフェースにおける処理実行の基本単位のことです。
例えば、UNIX 系なら、ps コマンドや top コマンドで現在実行されているプロセスを確認することができます。
通常、プロセス間のメモリ空間は分離されています。 プログラムは、プロセスを介して OS にリソースを要求することで、空きがある場合にメモリを追加取得することができます。 いわゆる、malloc というやつです。
malloc は OS のメモリ管理サブシステムに対して、ユーザ空間からシステムコール(OS に対するリソース要求)をかけてヒープメモリを確保・開放します。
ヒープメモリ
- プログラムが実行時に動的にメモリを割り当てるための領域で、OS から提供される
- 任意のサイズで追加や解放ができる柔軟性がある
スレッド
スレッドとは、プロセスのコンテキスト内で実行されるひとまとまりの命令のことです。
特定のプロセス内のスレッドは ps コマンドに PID(プロセスの ID)を渡して確認することができます。
単一プロセス内で動作するスレッドはメモリ空間、処理に必要なリソースを共有します。 スレッドはプログラムを実行する際のコンテキスト情報が最小で済むため、コンテキストスイッチはプロセスの切り替えと比較して速くなります。
スレッドは、プログラム内のコードにより管理することが可能な ユーザレベルスレッド(ULT:User-Lebel Thread) と、OS カーネルが管理する カーネルレベルスレッド(KLT:Kernel-Level Thread) が存在し、いずれも CPU コアに対してマッピングされます。
ユーザスレッドは、1990 年代、Java の初期バージョン(特に Java 1.1 以前)において、JVM(Java Virtual Machine)のスレッド管理に採用されました。 当初の開発担当チームが Green Team(米 Sun Microsystems, Inc. の Java 開発チーム)であったことから、ユーザスレッドは、グリーンスレッド(Green Thread) と呼ばれることもあります。参考
ちなみに、Sun Microsystems, Inc. は現在の Oracle, Inc. にあたります。
コンテキストスイッチ
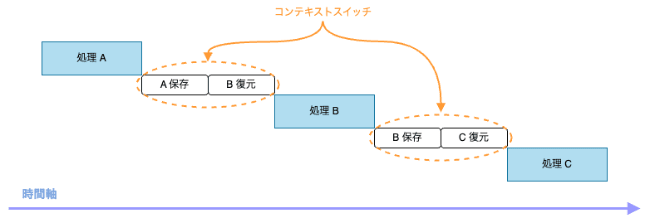
コンテキストスイッチとは、CPU が現在実行しているプロセスやスレッドを一時停止し、他のプロセスやスレッドに切り替えて実行を再開することです。
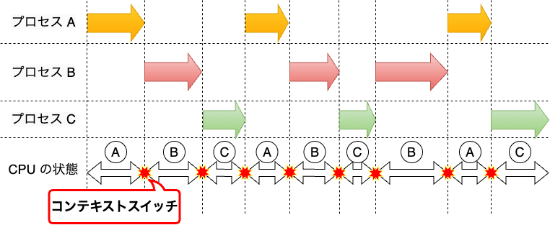
例えるなら、プロセスの切り替えは、数学と近代史の勉強を交互に行うようなもので、スレッド間の切り替えは、数学において特定の分野を切り替えるようなものです。 異なる科目・分野を交互に勉強する際に発生する、切り替えの労力がコンテキストスイッチにあたります。
処理方式
Goroutine の前に、最も単純なクライアントとサーバ間のやり取りを例に挙げ、Iterative Server と Concurrent Server の 2 つの処理方式を紹介します。
Iterative Server
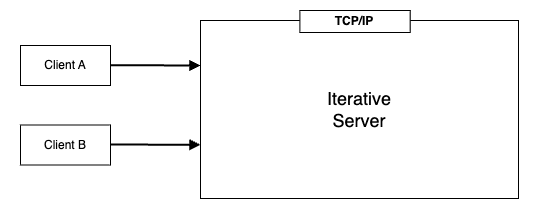
Iterative Server(反復サーバ)とは、サーバプログラムがクライアントからのリクエストを一度に一つずつ処理する方式のことを指します。 この方式では、サーバは一つのリクエストを完全に処理し終えるまで次のリクエストを受け付けないため、各リクエストは順次(シーケンシャルに)処理されます。

Iterative Server は各クライアントからのリクエストが小さく、サーバの処理が限られるアプリケーションでは効率的に機能します。
一方で、一つのクライアントの処理に負荷がかかりすぎると、他のすべてのクライアントが接続するまでに掛かる時間が許容限度を超えるため、同時に複数のリクエストを裁く局面でボトルネックが発生します。
Concurrent Server
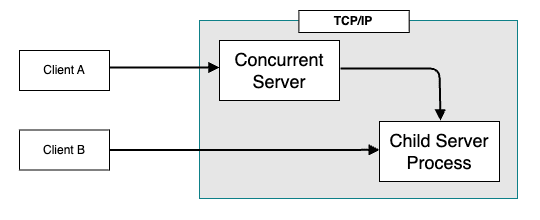
Concurrent Server(同時実行サーバ)は、複数のクライアントからのリクエストを同時に受け付けて処理するサーバを指します。 複数の処理を "タスク" という単位で並行実行することで、サーバ全体のスループットを向上させることが可能です。
近年の OS(UNIX 系、Windows 等)では、Iterative Server の課題を解決するための方法が用意されており、マルチタスク OS と呼ばれます。 マルチタスク OS は、プロセスやスレッドを利用することで一つのクライアントの処理を、独立して動作するサーバのコピーを使用して同時に処理します。
一般に、現在のプロセス(親プロセス)をコピーして新しいプロセス(子プロセス)を作成することを fork と言います。
マルチタスクでは、OS が複数のタスク(プログラムやプロセス)を同時に実行するように 見せかけて 実行します。 つまり、実際には一つの CPU が高速にタスクを切り替え、あたかも複数のタスクを同時に実行しているかのように見せかけているのです。
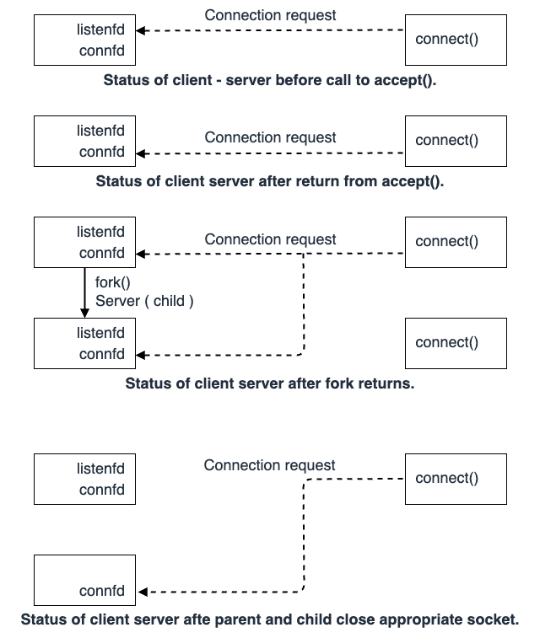
Concurrent Server は複数のプロセス(fork した子プロセス)を使用することで並行処理を実現し、多数のクライアントからの接続を効率的に捌くことが可能です。
一方で、プロセスの切り替えに伴うコンテキストスイッチは、オーバーヘッドとなるためパフォーマンスが極端に劣化する可能性があります。
マルチスレッド
マルチスレッドとは、一つのプロセスを複数のスレッドに分けて処理する ことで、処理速度の向上を実現する並行処理方式です。
各プロセスは最低一つのスレッドを保持しており、複数のプロセスを使用するプログラムを実行した場合は、複数のスレッドを使用します。 複数のプロセスに存在するスレッドを切り替える場合、メモリ空間の切り替えが必要となるため、コンテキストスイッチが発生し、処理に掛かる時間が増加します。 さらに、一つのプロセスは一つのアドレス空間でもあるため、プロセスを生成するためには、新たなアドレス空間を確保する必要があり、メモリ消費量が増大します。
一方で、スレッドの生成は、現在のプロセスのアドレス空間を使用するため、システムへの負荷が小さくなります。 プロセスの切り替えにはアドレス空間の切り替えが伴いますが、単一プロセス上で動作するスレッドの場合、アドレス空間の切り替えは発生しません。 従って、スレッドの切り替えに要する時間は、プロセスの切り替えに要する時間に比べて短くなります。
通常、シングルコアの場合、CPU は一度に一つの処理しか実行できないため、マルチスレッドを実装した場合でも、シングルスレッドに比べて処理時間が長くなることがあります。

こちらは、シングルコア CPU とマルチコア CPU におけるマルチスレッドの処理時間の比較を示しています。
マルチスレッドは、実行コアが複数存在する場合において、スレッドを用いることで多数の処理を並行して進められるため、結果として処理速度が速くなります。
現代の CPU のほとんどはマルチコアを実装しており、複数のコアで一度に並行処理を実現することが可能です。 プロセスの作成は OS によって行われ、メモリ、スタック、ファイルディスクリプタ等を割り当てることで特定の処理を実行します。
一方で、接続されるクライアント毎にプロセスを割り当てる場合、親プロセスのすべての状態をコピー(fork)する必要があるため、オーバーヘッドが高くなるという問題があります。
これに対し、スレッドは同一プロセスの中で複数のタスクを処理できるため、計算コストを削減することが可能です。 また、新しく生成されたスレッドは親スレッドと同じアドレス空間を共有するため、親プロセスの状態をコピーする必要はありません。
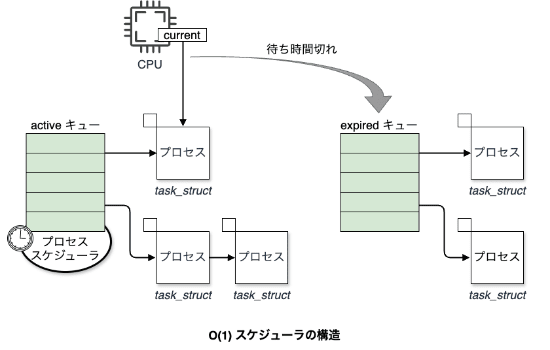
カーネルスケジューラ(OS のスレッドスケジューラ)は、一つのプロセス上で動作するプログラムにおいて、各スレッドを順番に短時間ずつ処理を再開していきます。 その際、順番やタイムスライスはスレッド毎に設定されている優先度によって決定され、ランキューと呼ばれるリストに入っている実行予定のスレッドに対して、公平に処理が回るようにスケジューリングされます。
タイムスライス
- スレッドが一回に実行する実行時間
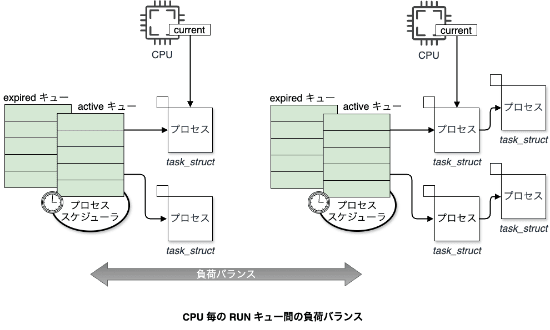
スレッドを使用したマルチスレッド処理は効率的ですが、スレッド自体の生産、破棄の際に、OS に対して都度、システムコールを行う必要があります。 さらに、スレッド間のコンテキストスイッチはプログラムカウンタやメモリ参照場所の切り替えが必要となるためオーバーヘッドとなります。
近年では、増加し続けるクライアントに対して、マルチスレッドによる並行処理が必要となりますが、カーネルスレッドは、生成するほどオーバーヘッドも増大するため処理負荷が高くなります。
当然、サーバ側の物理的なリソースを増やせば対処できるでしょうが、本質的な解決にはなっておらず、OS の内部処理に絡む厄介な問題として浮き彫りになっています。 いわゆる C10K 問題 がその代表的な例として挙げられます。
C10K 問題
- 「Concurrently handling 10,000 connections(同時に 10,000 の接続を処理する)」の略
- 1999 年に Dan Kegel によって提唱された(かなり前)
- 高トラフィックのネットワークサーバ、特に 10,000 以上のクライアント接続を同時に扱う際に発生するサーバのパフォーマンス問題
C10K 問題の背景
- リソース使用量
- 各接続に対して独立したスレッドやプロセスを割り当てる従来のモデルでは、膨大なメモリと CPU リソースが消費される
- スレッド / プロセスのオーバーヘッド
- 多数のスレッドやプロセスの生成にはオーバーヘッドが伴い、スケジューリングやコンテキストスイッチの頻度が増加する
- スケーラビリティの限界
- ネットワークソケットや入出力操作の非効率的な管理が、システムのスケーラビリティに制約をかける
平たく言えば、従来のスレッドを用いた並列な処理技術は、限界を迎えているということです。
では、Goroutine は従来のマルチスレッド処理とどう違うのでしょうか?
Goroutine
概要
Goroutine とは、Go ランタイムの最も基本的な構成単位です。 つまり、Go ランタイムは複数の Goroutine から成り立っている と言えます。
Go のユーザは go というディレクティブを用いて、メソッドを呼び出すことによって、その関数コンテキストをメインプロセスと並行実行させることができます。 このことから、Goroutine は 並行処理の基本単位 としても扱われます。
↓ こんな書き方
特徴
Go の開発者の一人である Rob Pike 氏による定義 と How Goroutines Work に詳しい記述があります。
要約すると Goroutine には以下の特徴があるとされています。
- カーネルスレッドではなくユーザスレッド
- メモリ使用量がカーネルスレッドに対して 500 分の 1
- コンテキストスイッチに要する時間はカーネルスレッドより短い
- 生成と破棄にかかる時間はカーネルスレッドより短い
- Goroutine は一つのカーネルスレッドに対して複数配置され、必要に応じて動的に利用するカーネルスレッドを増やす
Goroutine のデフォルトのスタックサイズは 2KB 程で、一般的なスレッド(約 1MB)と比較して 500 分の 1 程度しかありません。
ホストマシンのスタックサイズは $ ulimit -s で確認できます。
スタックメモリ
- コンパイラや OS が割り当て、アプリケーション側では自由に操作できない領域
- 関数呼び出し時の情報保存、ローカル環境変数(const で定義したもの)の管理、関数の戻りアドレスの保存に使用される
Q:Goroutine はなぜここまで軽量なのでしょうか。Go におけるスタックの扱い
- エスケープ解析によってポインタのスコープを特定し、ライフタイムが明確なオブジェクトはスタック領域を使用する
- Go のスタック領域は数キロバイト(2KB)から始まり、必要に応じて動的に拡張される
- Goroutine 毎に独立したスタック領域を持つ
Goroutine の位置付け
A:Goroutine はスレッドよりもさらに下に位置するから。まず、Go が実行されると、Main Goroutine と呼ばれる Goroutine が最低一つ起動します。
Main Goroutine は runtime パッケージの proc.go の中で書かれています。(proc.go 自体は 7000 行弱)
ここに、func main() で定義したメインソースが渡されて、Main Goroutine が起動します。
Main Goroutine は、プロセスが開始する際に自動的に生成、起動され、ランタイムの文脈ではメインプロセスに相当します。 生成された Goroutine 間の処理に優先度はなく、排他制御を実装しない限り、すべての Goroutine は非同期で実行 されます。
よく、M(Machine thread), G(Goroutine), P(Processor) という記号で説明されていますが、簡単に図に起こすと Goroutine の位置付けは以下のようになります。

ポイントは、スレッドの場合は、CPU コアに対してマッピングされ、OS によって管理されるが、Goroutine は OS のスレッドに対してマッピングされ、Go ランタイムによって管理される ということです。 Go ランタイムおよび Goroutine はユーザ空間プロセスとして実行されるため、カーネルスレッドではなくユーザスレッドということになります。
Goroutine は通常のカーネルスレッドの ID と異なり、指定しない限りどのスレッドにマッピングされるかは決まっていません。 Go ランタイムが決定します。
Go ランタイムは生成された Goroutine に対して以下の責務を持ちます。
- カーネルから割り当てられたメモリを分割し、必要に応じて割り当てる
- ガベージコレクタを動かす
- Goroutine のスケジューリングを行う
カーネルに詳しい人ならこの挙動にピンとくるかもしれませんが、OS のスケジューラがやっていることに近い機能を Go ランタイム自体が行なっています。
まさに、こちら にある通り、 Go ランタイムは "ミニ OS" です。
「Go のランタイムはミニ OS」 Go 言語のランタイムは、goroutine をスレッドとみなせば、OS と同じ構造であると考えることができます。
Go ランタイムは "ミニ OS"
Go の runtime パッケージを元に、図に起こすと以下のようになるかと思います。

Go ランタイムの内部は、主にマシンスレッド、Goroutine、Go ランタイムスケジューラから構成されています。
ここで、マシンスレッドはカーネルにおける物理 CPU コア(論理スレッド)に対応します。 Goroutine はプロセスに相当し、Go ランタイムスケジューラは、OS が提供するスレッドスケジューラと同等の機能を提供します。
Go ランタイムスケジューラは、全ての Goroutine のリスト、マシンスレッド(カーネルスレッド)、アイドル状態のリソース(スケジューリングのコンテキスト) を管理しています。 後者 2 つは連結リストで管理されています。
現代のカーネルは CPU 個のコアに対し、同時に 個の複数の処理が可能な スケジューラを実装しています。 いわゆる、ハイブリッドスレッディングというやつです。
Go ランタイムスケジューラも同様に、 個のカーネルスレッドに、 個のユーザスレッドを対応させたものにスケジューリングされるため、複数の CPU コアを扱うことが可能であり、 スケジューラを実現しています。
Go ランタイムは sysmon と呼ばれる特殊なマシンスレッドが、プログラムの実行においてボトルネックとなる処理を常に監視しています。 その際、sysmon はスケジューラによって実行が止められることがないよう、sysmon が稼働しているマシンスレッドは、特定の OS スケジューラとは別で実行されます。
Go ランタイムスケジューラはランキュー等のスレッドが行う作業を束ね、マシンスレッド毎にタスクとして Goroutine のリストを保持します。 各スケジューラはマシンスレッドを保持しており、実行可能な Goroutine をグローバルキューから取り出して、ローカルキューに保持します。 タスクは Goroutine が実行される際、ローカルキューから Go ランタイムスケジューラによって取り出され、マシンスレッド上で実行されます。
また、G0(ジーゼロ)はマシンスレッドに割り当てて実行する Goroutine とは別に割り当てた、特別な Goroutine で、実行中の Goroutine が待ち状態、もしくはブロック状態になると起動します。 さらに、Go ランタイムスケジューラを動かすことの他に、Goroutine によって割り当てられたスタックの増減処理や、ガベージコレクタを独自に実行します。
ガベージコレクタ(Garbage Collector)
- プログラムが動的に確保したメモリ領域のうち、断片化したメモリ領域や不要になったメモリ領域を自動的に解放する機能
Go ランタイムは常に一つの Goroutine を実行させることはなく、適度に実行する Goroutine を取り替えることにより、プログラム実行の効率化を図ります。 実行中の Goroutine を一旦中断する処理は、プリエンプション(Preemption)と呼ばれ、sysmon がボトルネックとなっている Goroutine を見つけると実行されます。
ここで、実行のボトルネックになっている Goroutine とは、CPU を長時間占有している Goroutine や、システムコール待ち状態の Goroutine を指します。
以上より、Go は内部で Go ランタイムスケジューラを動作させることにより、OS が提供するスレッドスケジューラとは分離して管理され、異なる Goroutine を実行する際もカーネルスレッドの切り替えを伴わない仕組みを持ちます。 つまり、マシンスレッド上で実行されている Goroutine が Go ランタイムスケジューラによって切り替えられたとしても、OS はコンテキストスイッチを認識しないということです。
その結果、Goroutine の切り替えは、スレッドの切り替えのように、プログラムカウンタやメモリ参照場所の切り替え処理が発生しません。 また、Goroutine は生成と破棄に関する操作が非常に低コストであるため、生成、破棄のたびに OS にシステムコールを行うスレッドに比べると、実行時間が極めて短縮されており、軽量に動作することが可能なのです。
Goroutine の適切な数
Goroutine は go ディレクティブによって容易に生成することができ、スレッドと比較して、非常に軽量かつ効率的なスケジューリングが可能です。
一般に、数百から数百万の Goroutine を単一のプロセス内で生成できるとされていますが、当然上限があります。
例えば、以下のようなコードは短時間に非常に多くの Goroutine が生成されるため、リソース(CPU、メモリ)を大量に消費し、最悪の場合クラッシュや著しいパフォーマンス低下を引き起こす可能性のある危険なコードです。
Goroutine を増やすと、処理を割り当てるための Resource(P)が増えることになります。 しかし、P はマシンスレッドに紐付くため、当然、M も増加することになります。 M が増加するということは、CPU は複数のカーネルスレッドに跨って、コンテキストスイッチを実行する必要があります。
本来、Goroutine はカーネルスレッドによるコンテキストスイッチを減らすことで軽量化を実現していたのにこれでは本末転倒です。 そのため、一般に、Goroutine の数(GOMAXPROCS)は CPU 数程度(論理スレッド数分)が良い とされています。
ムーアの法則 によれば、集積回路の密集度は年々向上しており、CPU のコア数も増加傾向にあります。
集積回路上のトランジスタ数が約 18 ヶ月毎に倍増する。
同じサイズのチップで利用できる計算能力が抜本的に増大し、コンピュータの性能と電力効率が向上する。
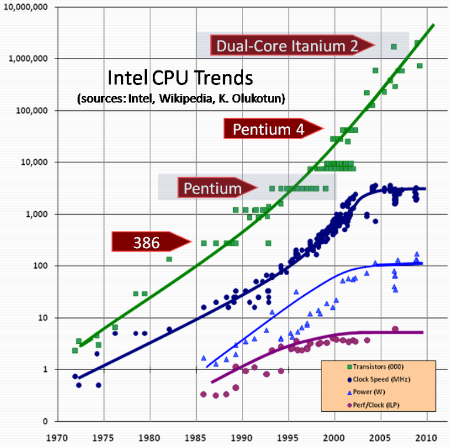
Goroutine はマルチコアプロセッサの能力を最大限に活用するための手段として機能し、ハードウェアアーキテクチャの進化に対して効果的に利用することが可能です。
runtime/proc.go
proc.go の func main() を軽くコードリードしてみた 🐹
ソースコードを展開
まとめ
今回のブログでは、Goroutine が 軽量スレッド と呼ばれる理由についてまとめました。
元来、プロセスに対して複数のスレッドを使用したマルチスレッドプログラミングが主流でしたが、増え続けるクライアントに対して、カーネルスレッドをベースとしたマルチスレッド処理モデルは OS の内部処理に起因する課題から限界を迎えていました。 一般的なスレッドの場合は、CPU コアに対してマッピングされ、OS によって管理されるため、スレッドの切り替えに伴うコンテキストスイッチによってオーバーヘッドが発生します。
一方で、Goroutine はカーネルスレッドに対してマッピングされ Go ランタイムによって管理されます。 Goroutine の切り替えは、OS から見ればスレッド内部の処理に留まるため、オーバーヘッドが極めて小さくなります。 また、Goroutine のスタックサイズは 2KB 程度しかありません。
Goroutine は、Go ランタイムが提供する スケジューラを利用することで、単一プロセス内で数百から数百万程度生成が可能とされています。
以上のような処理モデルを備えていることから、Goroutine は 軽量スレッド と称されています。
Go は賢い! これに尽きます。