C10K 問題とソフトウェアアーキテクチャの変遷
- Authors
- Name
- ごとれん
- X
- @ren510dev


目次
- 目次
- はじめに
- ソフトウェアアーキテクチャ
- C10K 問題
- プロセスとスレッド
- プロセス
- スレッド
- 並行処理と並列処理
- マルチプロセス
- マルチスレッド
- MPM:Multi Processing Module
- Pre-fork モデル
- Worker モデル
- 課題
- スレッド駆動型アーキテクチャ
- イベント駆動型アーキテクチャ
- Nginx のリクエスト処理モデル
- プロセス管理
- I/O 処理
- 特徴比較
- I/O 多重化
- 開発体制
- まとめ
- 参考・引用

はじめに
Web サーバやミドルウェアには、同時に多数の接続を効率的に処理することが求められます。 特に、インターネットの普及に伴い Web サービスの利用者が増加し、膨大なクライアントからのリクエストを処理する必要性が高まっています。
Apache に代表される、スレッド(プロセス)駆動ベースのソフトウェアアーキテクチャは、増大するクライアントに対するリソースの消費傾向やコンテキストスイッチのオーバーヘッドが増大することで、スケーラビリティの課題があります。
このような課題は、一般に C10K(同時に 10,000 接続を処理する)問題 と称され、2000 年初頭から、従来のソフトウェアの潜在的な課題を解決する効率的なアーキテクチャの必要性が議論されるようになりました。
近年では、ソフトウェアにおけるイベント駆動ベースのアーキテクチャが注目され、Nginx のような新世代の Web サーバも登場しました。
今回のブログでは、スレッド駆動ベースの Apache と イベント駆動ベース Nginx を例に、スレッド駆動アーキテクチャとイベント駆動アーキテクチャの特徴や、それぞれの技術的な問題点・利点について紹介したいと思います。
ソフトウェアアーキテクチャ
様々なサービスを提供するミドルウェアは、主に 2 つのアーキテクチャのいずれかで設計されます。
1 つ目は、Apache で利用されている スレッド駆動型アーキテクチャ です。 スレッド駆動型アーキテクチャは、マルチスレッド方式のソフトウェアアーキテクチャであり、受信した通信リクエスト一つに対して専用のスレッドを生成して処理を行います。
2 つ目は、Nginx で利用されている イベント駆動型アーキテクチャ です。 イベント駆動型アーキテクチャは、受信した通信リクエストをイベントキューに格納し、事前に生成された複数のワーカースレッドに引き渡すことで、ワーカースレッドが処理を行います。
以下に、『スレッド駆動型アーキテクチャ』と『イベント駆動型アーキテクチャ』の特徴について、C10K 問題を踏まえながら紹介します。
C10K 問題
C10K:Concurrently handling 10,000 connections
C10K 問題(クライアント 1 万台問題)とは、「同時 10,000 接続のクライアントを効率よく処理するにはどうすればよいか」という課題を指します。 C10K は「シー・テン・ケー」と読みます。
C10K 問題の難しい所は、ハードウェアやネットワークの性能が十分でも、クライアントの同時接続が一定数を超えるとリソース不足により、システムが処理しきれなくなる、あるいはパフォーマンスが劣化するという点です。
1990 年代後半までの一般的なソフトウェアアーキテクチャでは、1 つのクライアント接続に対して 1 つのスレッドやプロセスを割り当てる方式(スレッド駆動型)が主流でした。
しかし、同時接続数が増加すると、主に以下のような問題が発生しました。
スレッド / プロセスのオーバーヘッド
スレッド駆動ベースでは、1 接続毎にスレッドやプロセスを作成することで、メモリ消費が増大し、システムのリソースを圧迫する。
コンテキストスイッチの増大
大量のスレッドやプロセスを管理する際、OS が頻繁にコンテキストスイッチを行うことで計算コストが高くなり、CPU 負荷が増加する。
スケーラビリティの限界
ネットワークソケットや入出力操作の非効率的な管理が、システムのスケーラビリティに制約をかけることで、高負荷環境下で限界がある。
プロセスとスレッド
ソフトウェアアーキテクチャを理解する上で、プロセスとスレッドの仕組みを理解する必要があります。
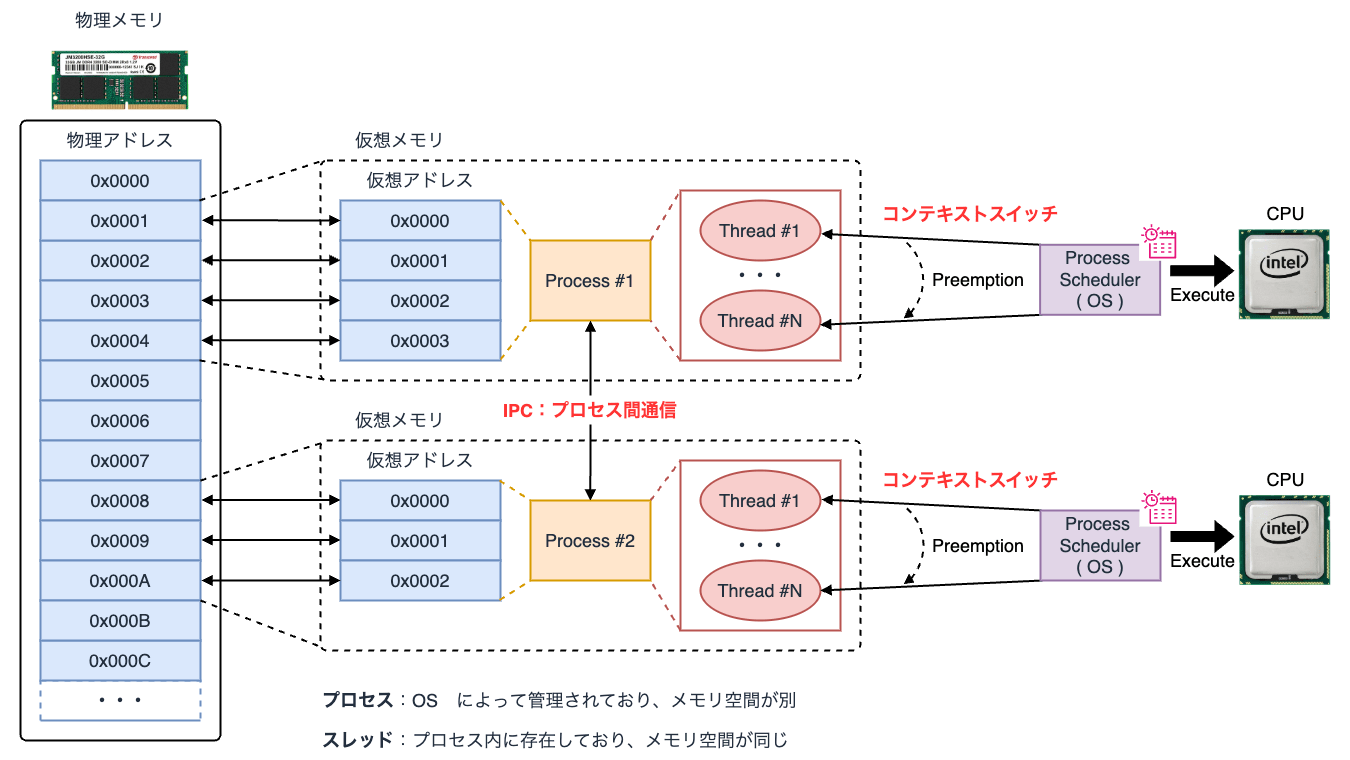
プロセスとスレッドの概念については、こちら のブログでも触れています。
プロセス
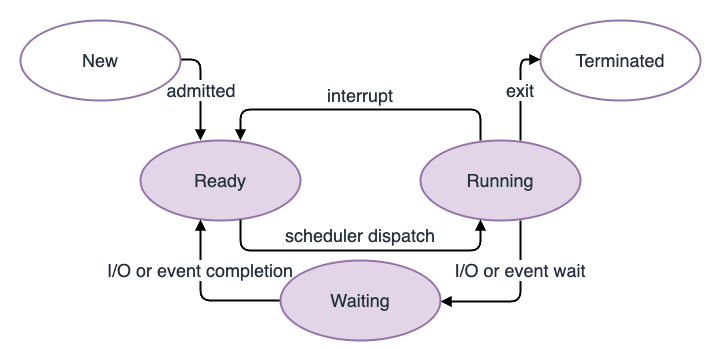
プロセス(Process)とは、プログラムの実行単位であり、CPU の時間単位で割り振られます。 プロセスには現在処理中の Running(実行中)や実行可能状態である Ready(待機中)等、ステータスの概念があります。
CPU がプロセスを実行する際には、そのプロセスが持つメモリに対して演算処理を行います。
プロセスはメモリ上で テキストセグメント と データセグメント からなる構造データを保持しています。 前者にはプログラムの命令列が格納され、後者にはプロセス管理データ領域である PDA(Processor Data Area)や、変数等の動的なデータが格納されるヒープ領域が含まれます。
また、その他、定数や環境変数等のライフサイクルが決まった静的領域を管理するスタックセグメントがあります。
実行中のプログラムおよびプロセスの中を複数の セグメント 単位(Memory Segmentation)で管理する方式を セグメント方式 と呼びます。
プロセスが生成されると、物理メモリ上に仮想メモリがマッピングされます。 これをメモリのページネーションと言い、仮想アドレスと物理アドレスの対応を ページ 単位(Memory Paging)で管理する方式を ページング方式 と呼びます。
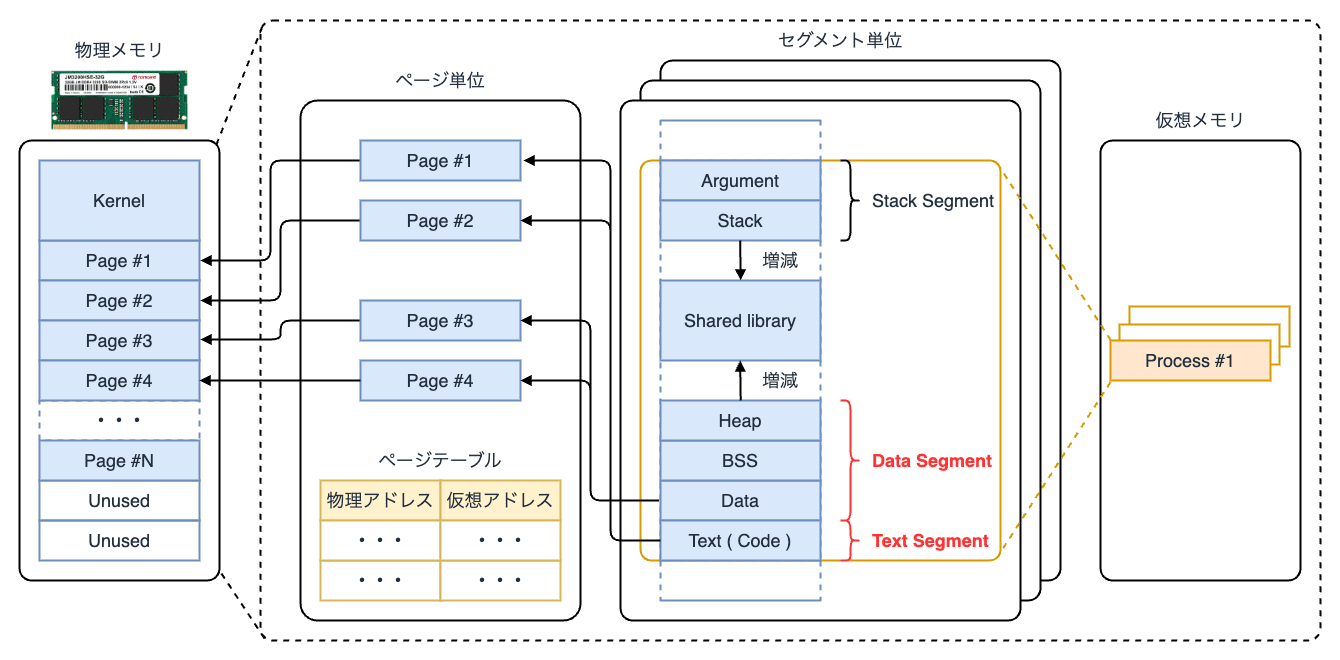
セグメントとページを組み合わせた方式は、一般に ページ化セグメンテーション(Paged Segmentation) と呼ばれ、今日 Linux をはじめとする Unix 系の OS で採用されています。
現在実行中のプロセスは、ps コマンドで確認することができます。
$ ps
PID TTY TIME CMD
16595 ttys012 0:00.32 -bash
10170 ttys015 0:00.14 npm run dev
この出力例では bash や Node.js のプロセスが実行中であることが分かります。
また、プロセスの仮想メモリは /prcoc/[PID]/maps で確認できます。
$ sudo cat /proc/1/maps
5aa5e12a3000-5aa5e12d3000 r--p 00000000 08:01 653258 /usr/bin/bash
5aa5e12d3000-5aa5e13c2000 r-xp 00030000 08:01 653258 /usr/bin/bash
5aa5e13c2000-5aa5e13f7000 r--p 0011f000 08:01 653258 /usr/bin/bash
5aa5e13f7000-5aa5e13fb000 r--p 00154000 08:01 653258 /usr/bin/bash
5aa5e13fb000-5aa5e1404000 rw-p 00158000 08:01 653258 /usr/bin/bash
5aa5e1404000-5aa5e140f000 rw-p 00000000 00:00 0
5aa61f8f7000-5aa61fa83000 rw-p 00000000 00:00 0 [heap]
7c35715fe000-7c35718e9000 r--p 00000000 08:01 1439188 /usr/lib/locale/locale-archive
7c35718e9000-7c35718ec000 rw-p 00000000 00:00 0
7c35718ec000-7c3571914000 r--p 00000000 08:01 661589 /usr/lib/x86_64-linux-gnu/libc.so.6
7c3571914000-7c3571a9c000 r-xp 00028000 08:01 661589 /usr/lib/x86_64-linux-gnu/libc.so.6
7c3571a9c000-7c3571aeb000 r--p 001b0000 08:01 661589 /usr/lib/x86_64-linux-gnu/libc.so.6
7c3571aeb000-7c3571aef000 r--p 001fe000 08:01 661589 /usr/lib/x86_64-linux-gnu/libc.so.6
7c3571aef000-7c3571af1000 rw-p 00202000 08:01 661589 /usr/lib/x86_64-linux-gnu/libc.so.6
7c3571af1000-7c3571afe000 rw-p 00000000 00:00 0
7c3571afe000-7c3571b0c000 r--p 00000000 08:01 654777 /usr/lib/x86_64-linux-gnu/libtinfo.so.6.4
7c3571b0c000-7c3571b1f000 r-xp 0000e000 08:01 654777 /usr/lib/x86_64-linux-gnu/libtinfo.so.6.4
7c3571b1f000-7c3571b2d000 r--p 00021000 08:01 654777 /usr/lib/x86_64-linux-gnu/libtinfo.so.6.4
7c3571b2d000-7c3571b31000 r--p 0002e000 08:01 654777 /usr/lib/x86_64-linux-gnu/libtinfo.so.6.4
7c3571b31000-7c3571b32000 rw-p 00032000 08:01 654777 /usr/lib/x86_64-linux-gnu/libtinfo.so.6.4
7c3571b34000-7c3571b3b000 r--s 00000000 08:01 661444 /usr/lib/x86_64-linux-gnu/gconv/gconv-modules.cache
7c3571b3b000-7c3571b3d000 rw-p 00000000 00:00 0
7c3571b3d000-7c3571b3e000 r--p 00000000 08:01 661517 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7c3571b3e000-7c3571b69000 r-xp 00001000 08:01 661517 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7c3571b69000-7c3571b73000 r--p 0002c000 08:01 661517 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7c3571b73000-7c3571b75000 r--p 00036000 08:01 661517 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7c3571b75000-7c3571b77000 rw-p 00038000 08:01 661517 /usr/lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
7ffda1624000-7ffda1645000 rw-p 00000000 00:00 0 [stack]
7ffda16fa000-7ffda16fe000 r--p 00000000 00:00 0 [vvar]
7ffda16fe000-7ffda1700000 r-xp 00000000 00:00 0 [vdso]
ffffffffff600000-ffffffffff601000 --xp 00000000 00:00 0 [vsyscall]
スレッド
スレッド(Thread)とは、CPU を利用するための最小実行単位であり、プログラムの処理を細かく分割して 並行実行できる仕組み です。 従来の子プロセスは、独自の仮想メモリを割り当てられるため、プロセス毎のメモリ管理の負担が大きくなるという課題がありました。
この問題を解決し、より軽量な実行単位としてスレッドの概念が導入され、Linux kernel 2.4 から本格的に導入されました。
スレッドを活用することで、メモリ使用量を節約しながら、高速な並行処理が可能となります。
例えば、C 言語の場合はスレッドの管理に pThread(POSIX Thread) を使用します。
#include <stdio.h>
#include <pthread.h>
// スレッドで実行する関数
void *func_hoge(void *arg)
{
for (int i = 0; i < 10000; i++)
{
putchar('hoge');
}
return NULL;
}
void *func_fuga(void *arg)
{
for (int i = 0; i < 10000; i++)
{
putchar('fuga');
}
return NULL;
}
int main()
{
pthread_t threadHOGE, threadFUGA;
// スレッドの作成
pthread_create(&threadHOGE, NULL, func_hoge, NULL);
pthread_create(&threadFUGA, NULL, func_fuga, NULL);
// スレッドの終了待ち
pthread_join(threadHOGE, NULL);
pthread_join(threadFUGA, NULL);
return 0;
}
pThread は pthread_create() サブルーチンをコールして新規スレッドを作成します。 C 言語では標準の pThread ライブラリをインクルードするため、コンパイル時に -pthread を付けます。
$ gcc -o thread_example thread_example.c -pthread
並行処理と並列処理
並行処理と並列処理は言葉が似ているものの異なる概念です。
並行処理(Concurrency) は、ある任意の時点では 1 つの処理しか実行していないものの、複数の処理を高速に切り替えることで、あたかも同時に実行されているかのように見せる方式です。
並列処理(Parallelism) は、複数の処理を物理的に同時に実行することを意味し、並列処理は並行処理を包含する方式となります。
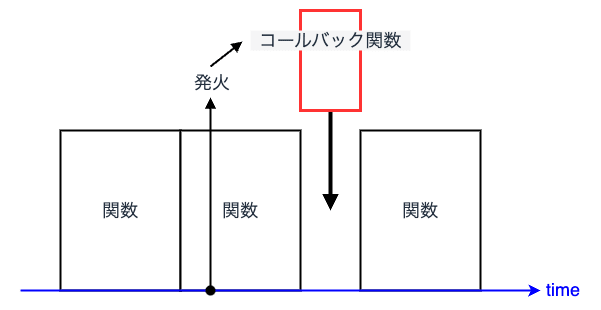
例えば、JavaScript における非同期処理は直感的には並列処理のように思えますが、実際には 並行処理 をしています。 JavaScript はシングルスレッドのプログラミング言語であるため、setTimeout 等の非同期処理も別スレッドで実行されるわけではなく、同じスレッド上で処理されます。
その仕組みとして、イベントループが実行待ちのキューを管理し、コールバック関数を適切なタイミングで実行することで、非同期動作を実現しています。 これにより、JavaScript の実行環境では 1 つのスレッドでありながら、並行的な処理が可能となっています。
マルチプロセス
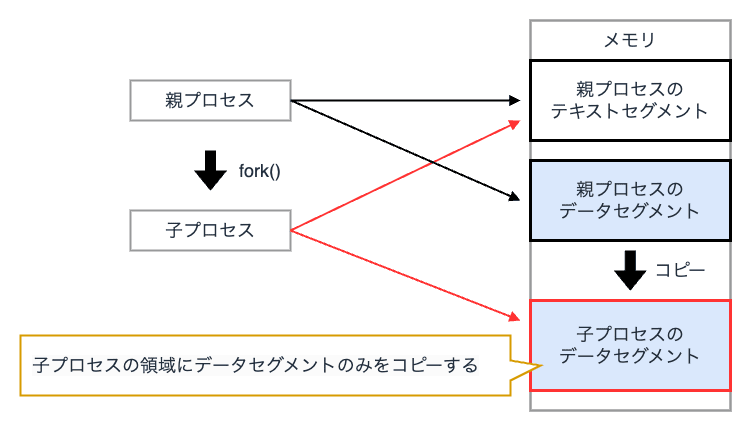
マルチプロセス(マルチタスク) とは、複数のプロセスを並列に実行する仕組み です。 クライアントからの接続毎に フォーク(fork) を実行し、新たな子プロセスを生成することで、同じプログラムを並列に実行します。
マルチプロセスでは、各子プロセスが独立したメモリ空間を持つため、スクリプト言語などの組み込みが容易になるというメリットがあります。
一方で、プロセス間はメモリ空間を共有できないため、直接的なメモリ参照ができず、データのやりとりには通常 プロセス間通信(IPC:Inter-Process Communication) が必要となります。
シングルプロセスの場合は、1 つのプロセスのみでプログラムを実行する方式であり、並行処理によってリソースを効率的に活用します。
マルチスレッド
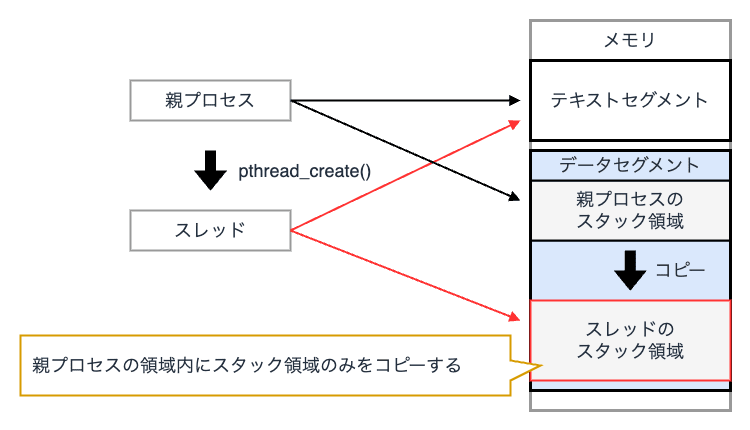
マルチスレッドとは、1 つのプロセス内で複数のスレッドを生成し、それらを並列に処理する仕組み です。 クライアントの接続毎に新しいスレッドを作成して処理を行います。
マルチスレッドでは、各スレッドがメモリ空間を共有できるため、マルチプロセスモデルに比べてメモリ消費量が少なく、コンテキストスイッチのオーバーヘッドが小さいというメリットがあります。
一方で、メモリ空間を共有した場合、スレッド間の依存により、スクリプト言語の組み込みが複雑化するという課題があります。
シングルスレッドの場合は、1 つのプロセスが 1 つの処理の流れのみを持ち、逐次的に処理を実行します。 シングルスレッドは、並列処理ではなく、単一の命令の流れを切り替えながら実行する並行処理の形態となります。
例えば、Node.js のシングルスレッドモデルでは、ファイル I/O の非同期処理とイベントループを活用することで、効率よく並行処理を実現しています。
また、Go 言語の Goroutine もシングルスレッドの概念に基づいています。
MPM:Multi Processing Module
MPM(Multi Processing Module) とは、Web ブラウザからのリクエストを処理する部分をモジュール化したもので、Apache で使用されるアーキテクチャの 1 つです。 MPM には、主に Pre-fork モデル と Worker モデル の 2 種類が存在します。
Pre-fork モデル
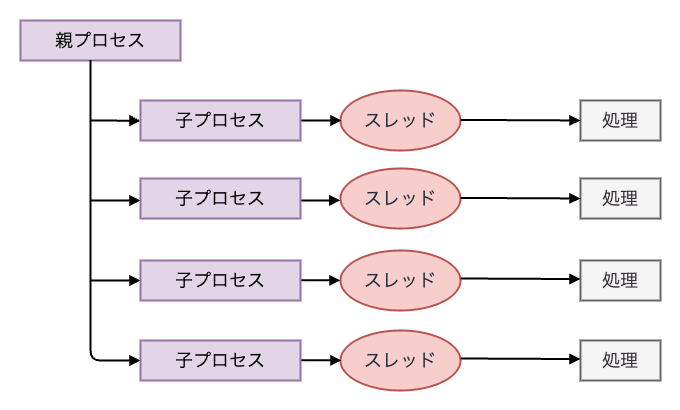
Pre-fork モデル は、マルチプロセスモデルに基づいた方式で、1 リクエストに対して 1 子プロセスが対応する仕組みとなっています。 Pre-fork モデルでは、事前に fork した子プロセス(単一スレッド)でリクエストを処理します。
Pre-fork モデルは、各プロセスが独立したメモリ空間を持っているため、安定性が高く、1 つの子プロセスがクラッシュしても他のプロセスには影響を与えません。 これにより、比較的堅牢な通信を維持しやすい構造となっています。
一方で、クライアントの同時接続数が増えると、それに比例して子プロセスの数も増加し、大量のメモリ消費や CPU 負荷が発生します。 そのため、C10K 問題に直面しやすいという欠点があります。
Pre-fork モデルは、Apache のデフォルトのモードとなっています。 Pre-fork モデルは、スレッドセーフな設計であるため、LAMP スタック 等において、Apache 上で PHP を実行する場合は基本的にこちらのモードを使用します。
Pre-fork モデルは単純明快で、Apache の設定項目も少なくて済むため、比較的アクセス数が少ない Web サイトや、納期が短い案件等では、今後も十分に利用する価値があると思います。
Worker モデル
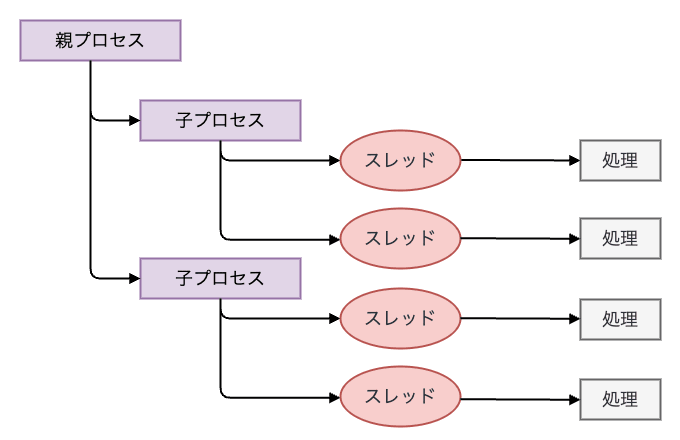
Worker モデル は、マルチプロセスとマルチスレッドのハイブリッドモデルを採用しており、1 つの子プロセス内で複数のスレッドを並列実行します。 Worker モデルでは、リクエスト毎にスレッドを割り当てるため、より少ないメモリ使用量で多数のリクエストを処理できます。
Worker モデルは、マルチプロセスモデルと比較すると、プロセスの生成オーバーヘッドが削減され、使用メモリ量も少なくて済むため、効率的なスケーラビリティを実現します。
一方で、スレッド数が増加すると CPU 負荷が大きくなり、C10K 問題を引き起こす懸念があります。
また、メモリ空間を共有するため、スレッドの安定動作に配慮する必要があり、プログラムの実装によっては安定性が損なわれる可能性があります。
Worker モデルはスレッドセーフではないため PHP は利用できません。 Worker モデルは、例えば Event モデル が利用できない(Apache 2.0 以下)場面において、Pre-fork モデルよりも性能を出したい場合に利用すると良いでしょう。
課題
MPM の Pre-fork と Worker にはそれぞれ課題があり、どちらも C10K 問題に直面する可能性があります。
| MPM | 特徴 | メリット | デメリット |
|---|---|---|---|
| Pre-fork | マルチプロセスモデル (1 リクエスト = 1 子プロセス) | 安定した通信が可能 (プロセスごとに独立) | 大量のメモリ消費と C10K 問題発生の可能性 |
| Worker | マルチプロセス + マルチスレッドのハイブリッドモデル (1 リクエスト = 1 スレッド) | メモリ使用量を削減し、大量のリクエストを効率的に処理可能 | スレッド数が増加すると C10K 問題が発生しやすい |
スレッド駆動型アーキテクチャ
スレッド駆動型アーキテクチャを採用している代表的な Web サーバに Apache(Apache HTTP Server) があります。

Apache は マルチスレッド方式のソフトウェアアーキテクチャ となっており、リクエスト一つに対して専用のスレッドを生成して処理を行います。
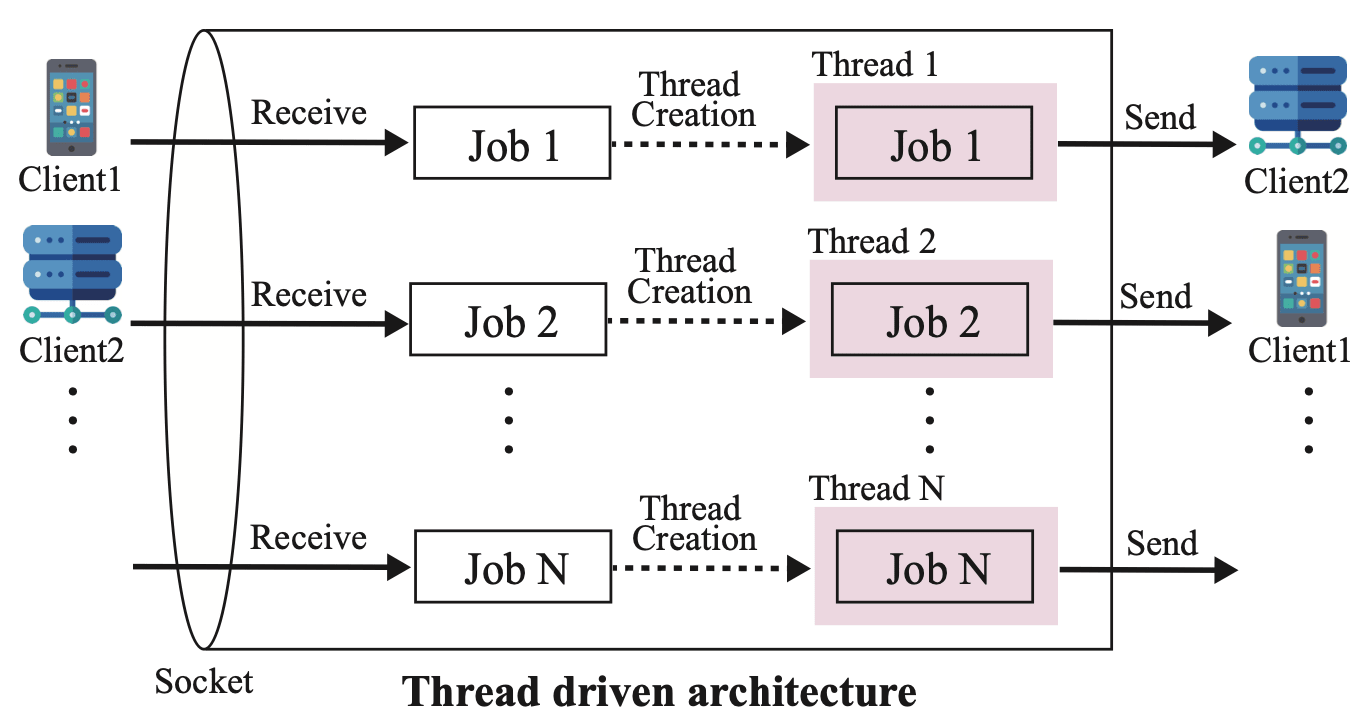
スレッド駆動型アーキテクチャでは、まずクライアントからのリクエストジョブを受け取ると、ジョブを処理する専用のスレッドを生成します。 その後、生成されたスレッドにジョブを引き渡して処理し、レスポンスをクライアントに返送します。
スレッド駆動型アーキテクチャは、ジョブ毎に処理用スレッドを生成するため、単一のリクエストの計算量が多い場合でも、他の処理に影響を与えにくい という特徴があります。
一方で、高負荷時には大量のスレッドやプロセスが生成されるため、メモリリソースを圧迫し、コンテキストスイッチのオーバーヘッドが発生することで、処理遅延や C10K 問題の懸念が生じます。
イベント駆動型アーキテクチャ
イベント駆動型アーキテクチャを採用している代表的な Web サーバに Nginx があります。

Nginx はシングルスレッド方式のアーキテクチャとなっており、リクエストは事前に生成したワーカースレッドによって処理されます。 そのため、スレッドの生成や待機による処理遅延が発生しにくく、同時発生する多数のリクエスト処理を得意 とします。
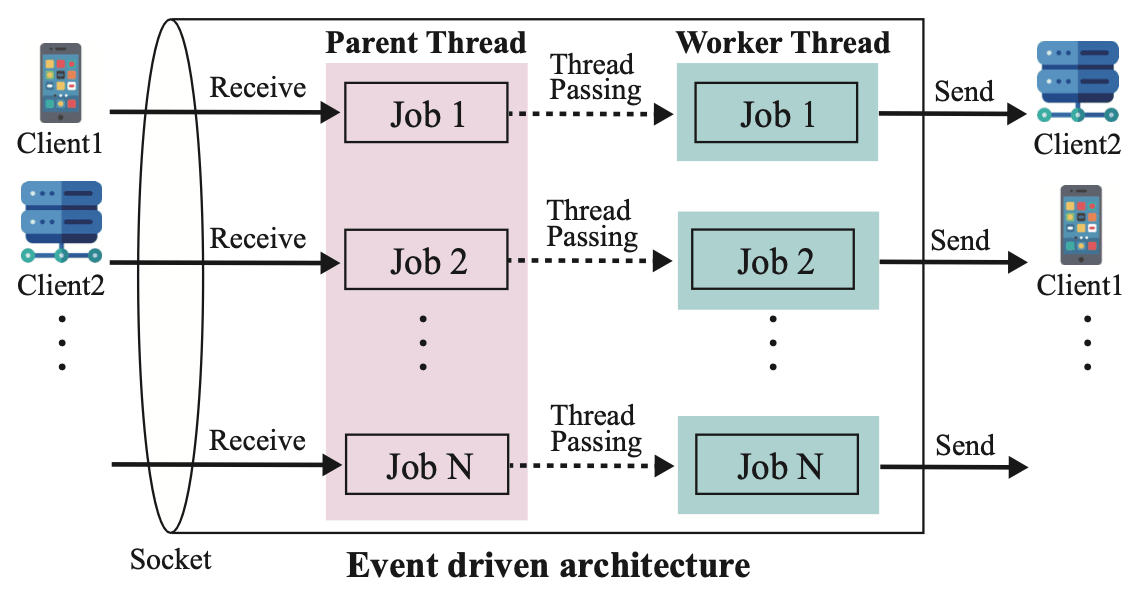
イベント駆動型アーキテクチャでは、クライアントからのリクエストジョブを受け取ると、ジョブを親スレッドに格納します。 次に、親スレッドはジョブ処理用のワーカースレッドの状態を確認し、ワーカースレッドが処理可能な状態であれば、ジョブをワーカースレッドに引き渡します。 その後、ジョブを引き渡されたワーカースレッドが処理を行い、レスポンスをクライアントに返送します。
マルチスレッド方式を採用するスレッド駆動型アーキテクチャに対し、イベント駆動型アーキテクチャでは コンテキストスイッチを避けるためにシングルスレッドで処理 を行います。 一つのスレッドは一つの CPU しか使用できないため、実際には CPU のコア(論理スレッド)数に合わせてイベント駆動処理を行うワーカースレッドを複数準備します。
また、非同期なイベント駆動と I/O の多重化により、ワーカースレッドは、リクエストが完全に処理されるのを待たずに次の処理を実行できます。 そのため、同時発生した多数のリクエストの並行処理が可能であり、C10K 問題を根本的に解決できます。
Nginx や Node.js はイベント駆動で動作することで、高負荷なウェブシステムにおいてもパフォーマンスを損ないにくい仕組みになっています。
Nginx のリクエスト処理モデル
Nginx は、イベント駆動型アーキテクチャを採用しており、シングルスレッドでリクエストを処理します。 これにより、クライアント接続毎にプロセスやスレッドを生成する必要がなく、コンテキストスイッチのオーバーヘッドも生じません。
プロセス管理
Nginx のプロセス管理は マスタープロセス と ワーカープロセス に分かれています。
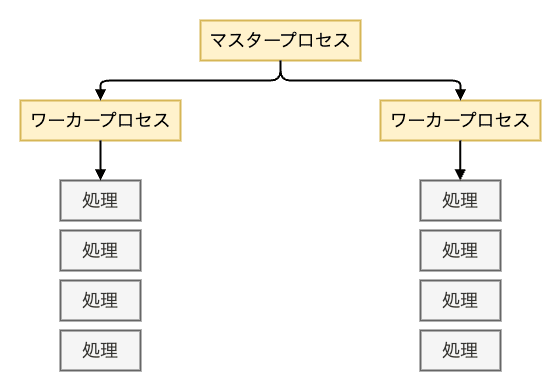
マスタープロセスは、ワーカープロセスの立ち上げや管理を担当し、Nginx 全体のプロセスを制御する役割を担っています。
また、ワーカープロセスは、各クライアントからのリクエストを処理するシングルスレッドのプロセスであり、それぞれが複数のリクエストを同時に処理することが可能です。 ワーカープロセス自体はマルチプロセスとして扱うこともでき、マスタープロセスが受信したシグナルの種類に応じて、各ワーカープロセスにも適切なシグナルを送る仕組みになっています。
Nginx は、シングルスレッド 1 プロセスで多数のクライアント接続を処理するため、非同期 I/O と I/O 多重化 を取り入れています。
I/O 処理
I/O 処理の種類は大きく 4 つに分けることができます。
- ブロッキング I/O(Blocking I/O)
- ノンブロッキング I/O(Non-Blocking I/O)
- 同期 I/O(Syncronous I/O)
- 非同期 I/O(Asynchronous I/O)
| 処理方式 | 概要 |
|---|---|
| ブロッキング | タスクが完了するまで 待つ |
| ノンブロッキング | タスクの完了を 待たない |
| 同期 | タスクを投げた後 I/O の 準備ができた時点で 通知をもらう |
| 非同期 | タスクを投げた後 I/O が 完了してから 通知をもらう |
組み合わせは次のようになります。
| ブロッキング | ノンブロッキング | |
|---|---|---|
| 同期 | Read / Write | Read / Write(O_NONBLOCK) |
| 非同期 | I/O 多重化 (select / poll / epoll / kqueue) | 非同期 I/O |
ブロッキング I/O
ブロッキング I/O は、プログラムが I/O 操作を実行すると、その 操作が完了するまで待機し、他の処理を進めることができない 方式です。
ブロッキング I/O は、実装がシンプルですが、I/O の完了待ちで CPU リソースを浪費する可能性があります。
また、マルチスレッド環境と組み合わせることで並行処理が可能となる一方で、スレッド管理のオーバーヘッドが発生します。
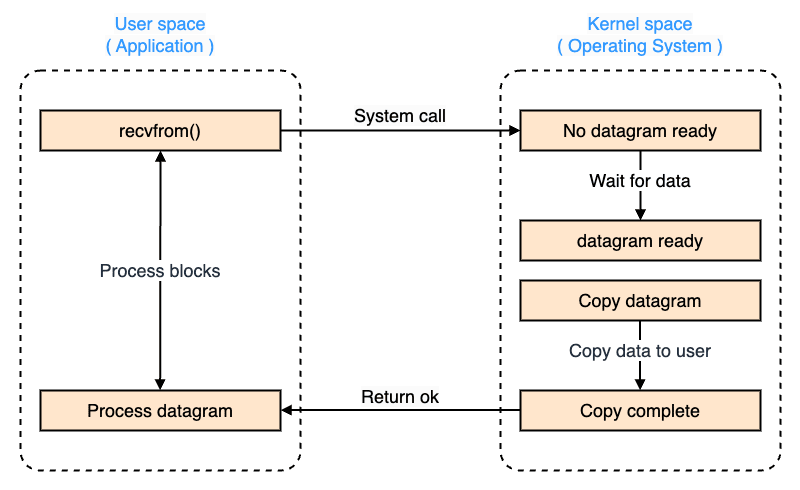
- システムコール
- カーネルモードにコンテキストスイッチ
- 処理が完了
- ユーザモードにコンテキストスイッチ
- ブロック状態から解放
ノンブロッキング I/O
ノンブロッキング I/O は、プログラムが I/O 操作を実行する際に、その 操作が完了していなくても他の処理を進められる 方式です。
ノンブロッキング I/O は、I/O 操作を試みても、すぐに制御が戻るため、データが準備できていなければエラーや特定の値を返します。 そのため、プログラム側では I/O の準備ができたかどうかを繰り返し確認する ポーリング が必要になります。
ノンブロッキング I/O は、CPU リソースを効率的に活用しようとしますが、ポーリングの負荷が問題となることがあります。
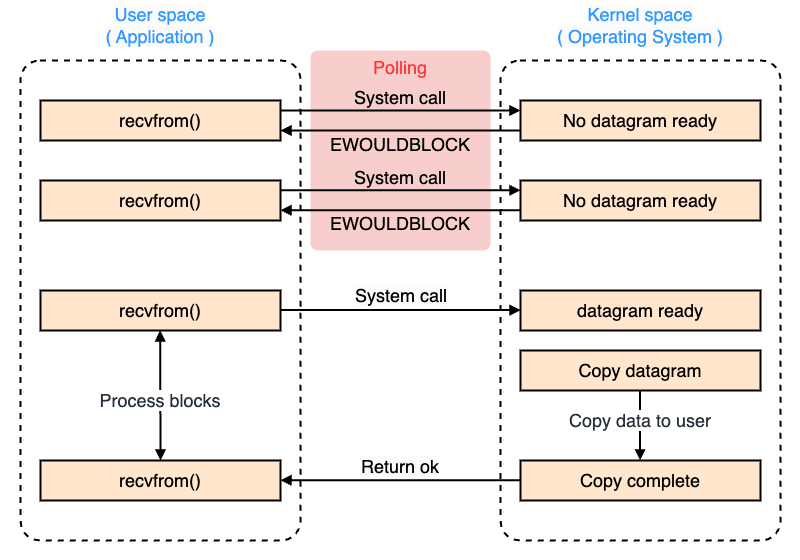
- ファイルディスクリプタに
O_NONBLOCKをセットしてノンブロッキングモードに移行 - そのファイルディスクリプタを使ってシステムコール
- カーネルモードにコンテキストスイッチ
- すぐに
EWOULDBLOCK(EAGAIN)を返す(ユーザモードにコンテキストスイッチ) - ファイルディスクリプタの準備が完了するまで何度もポーリング(都度コンテキストスイッチが走る)
- ファイルディスクリプタの準備完了
- 準備ができたデータグラムに対するシステムコール
- 処理が完了
- ユーザモードにコンテキストスイッチ
- ブロック状態から解放
同期 I/O
同期 I/O は、プログラム内で I/O 操作を呼び出したスレッドが、処理完了までブロックされる 方式です。
同期 I/O はブロッキング I/O と同義で使われることが多いため、同期ブロッキング I/O と呼ばれることもあります。
非同期 I/O
非同期 I/O は、プログラムが I/O 操作を開始した後、その 完了を待たずに他の処理を進めることができる 方式です。
非同期 I/O は、操作を開始するとすぐに制御が戻るため、別の処理を実行することが可能です。 I/O の完了は、コールバック関数やイベント通知(ハンドラ)、または OS のシグナルを通じて受け取ります。 非同期 I/O を活用することで、シングルスレッドによる効率的な並行処理が可能です。
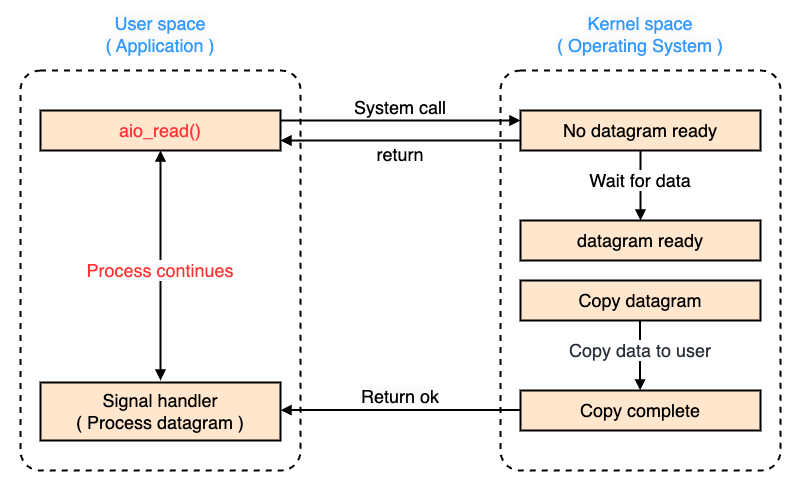
aio_read()でシステムコール- リクエストがキューされた時点ですぐ返る(ユーザモードにコンテキストスイッチ)
- 他の処理を実行可能
- I/O 処理が完了
- カーネルが I/O 処理の完了を通知(
callbackやsignal)
特徴比較
| 処理方式 | 概要 | メリット | デメリット |
|---|---|---|---|
| ブロッキング I/O | I/O 完了まで待機する | 実装が簡単 | 処理が止まるため非効率 |
| ノンブロッキング I/O | I/O 処理の結果がすぐ返る | 並行処理が可能 | ポーリングが必要 |
| 同期 I/O | 処理が完了するまで制御を戻さない | 挙動が直感的で分かりやすい | 実行スレッドが停止する |
| 非同期 I/O | I/O を待たずに他の処理が可能 | 効率的な処理が可能 | コールバックやイベント管理が複雑 |
I/O 多重化
I/O 多重化(I/O Multiplexing) は、単一のスレッドで複数の I/O チャネル(例:複数のソケットやファイル)を監視し、いずれかが準備できた時点で処理を進める 方式です。 一般に、select、poll、epoll、kqueue 等のシステムコールを使用して複数のファイルディスクリプタを監視します。
I/O 多重化は、効率的に複数の I/O を処理可能です。 非同期 I/O をノンブロッキング I/O と組み合わせることで、CPU の無駄なポーリングを抑えつつ、シングルスレッドで複数の I/O 処理を可能にします。
つまり、ノンブロッキング I/O と非同期 I/O のいい所取りをしているわけです。
I/O 多重化は、高パケットレートを捌く必要があるネットワークミドルウェアやサーバソケットの処理において利用されます。
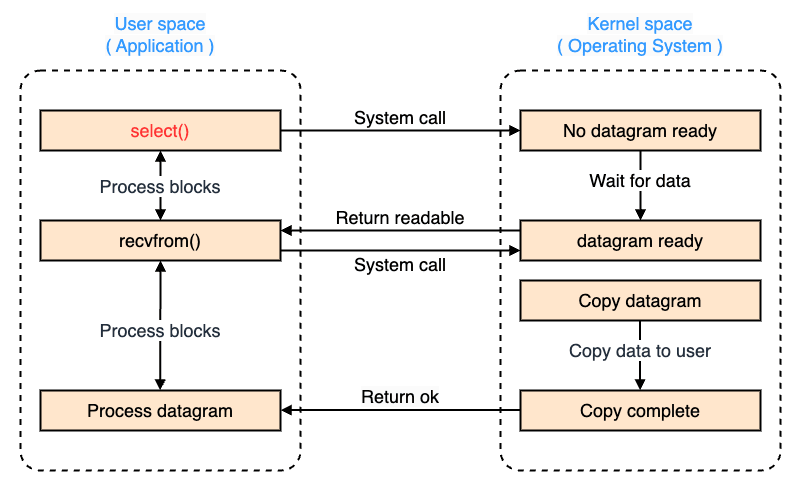
- システムコール
- カーネルモードにコンテキストスイッチ
- ファイルディスクリプタの準備ができたらユーザモードにコンテキストスイッチ
- 準備ができたデータグラムに対するシステムコール
- 処理が完了
- ユーザモードにコンテキストスイッチ
- ブロック状態から解放
Nginx はイベントループによる非同期なイベント駆動と I/O 多重化により、ワーカープロセスがリクエストの完全な処理を待たずに次のリクエストを処理していきます。 この仕組みにより、高い並行処理能力を持ち、大量の同時接続を効率的に捌くことができます。
開発体制
Apache と Nginx はいずれもオープンソースの Web サーバですが、両者は開発体制が異なります。
- Apache HTTP Server:https://github.com/apache/httpd
- Nginx:https://github.com/nginx/nginx
Apache の開発元は Apache Software Foundation(ASF) となっており、営利企業ではなくコミュニティにおいて意欲のあるエンジニアが、その人の意思で開発に参加しています。 コミッターやメンバー(特に貢献度の高いコミッター)になる方法も明記されています。

他方の Nginx は、Nginx, Inc. となっており、営利企業によって開発されています。 つまり、一般の開発者にはコミット権限が付与されず、全て Nginx 社のエンジニアによって開発されています。
ただし、メーリングリストやバグ管理システムについては公開されており、パッチも受け付けているようです。
アーキテクチャを見比べても一目瞭然ですが、個人的には Nginx の方がワーカースレッドベースの非同期処理を制御する必要があったり、実装が複雑だったりと、開発にはより高度な知識と技術力が要求されると思われます。
まとめ
| Apache(Pre-fork / Worker) | Nginx(イベント駆動) | |
|---|---|---|
| アーキテクチャ | スレッド(プロセス)駆動型 | イベント駆動型 |
| スレッド管理 | マルチスレッド | シングルスレッド |
| 接続管理 | 1 接続 = 1 スレッド(プロセス) | ワーカースレッドで多数の接続を同時に処理 |
| 並行性 | 高負荷時にスレッド数が増大しメモリ圧迫 | イベント駆動と非同期処理により効率的に拡張 |
| メモリ消費 | スレッドごとにメモリを消費 | 単一のスレッドを使用するため軽量 |
| 処理速度 | スレッド数が多いと遅くなる | スケールしやすく高速処理可能 |
| 用途 | 単一ジョブの計算量が多い高負荷リクエストの処理 | 同時発生する多数リクエストの処理(C10K 問題への対応) |
| 開発元 | コミュニティ(Apache Software Foundation) | Nginx, Inc. |
C10K 問題の提唱により、アプリケーションやミドルウェアにおけるスケーラブルなソフトウェアアーキテクチャの必要性が高まりました。 Apache はリクエストに対してプロセスやスレッドを割り当てるスレッド駆動モデルを採用しています。 そのため、単一ジョブの計算量が多い高負荷リクエストの処理には有用ですが、高負荷環境や同時発生するリクエストの処理には適応しにくいという課題があります。
一方、Nginx は単一のスレッドからワーカースレッドを生成して、待ちが発生する処理をイベント駆動で捌きます。 イベント駆動型アーキテクチャは、非同期 I/O や I/O 多重化を駆使することで、高度な並行処理が可能なため、C10K 問題の潜在的な課題を解決します。
これまで、「何か最近 Nginx を使う場面が増えたな」ぐらいでいましたが、昨今のエンド端末の爆発的な増加や、C10K 問題の背景を知ることで、ようやく理解が追いついてきました。
ムーアの法則に基づき、今後も CPU の性能は向上していくと思われますが、ハードウェアやマシンの性能に頼るだけでなく、ソフトウェアアーキテクチャ自体のリビルドもパフォーマンスを最大化する上で必要不可欠だと再認識しました。
参考・引用
- Nginx vs Apache: 6 Main Differences
- apache と nginx の性能比較
- Apache コミッターが見た Apache vs nginx
- はじめての OS コードリーディング - UNIX V6 で学ぶカーネルのしくみ
- Operating System - Memory Management
- プロセスって何?
- プロセスとスレッドの違いとは?
- #10 主記憶管理: セグメンテーション, ページ化セグメンテーション
- 【Linux カーネル: OS 入門 3】メモリ管理
- java Selector is asynchronous or non-blocking architecture
- Non-Blocking I/O, I/O Multiplexing, Asynchronous I/O の区別
- 非同期 I/O やノンブロッキング I/O 及び I/O の多重化について
- Nginx のアーキテクチャを理解する
- Apache と Nginx について比較
- JavaScript の非同期処理を並列処理と勘違いしていませんか?