Discord が Go から Rust に移行した背景を覗く
- Authors
- Name
- ごとれん
- X
- @ren510dev


目次
- 目次
- はじめに
- 移行の背景
- なぜ Go の性能が低下したのか
- なぜ Rust を採用するのか
- Async Rust の導入
- 移行前後のパフォーマンス比較
- キャッシュのチューニング
- Rust のメリット
- まとめ
- 参考・引用

はじめに

ゲーマー向けのテキストチャットサービスとして有名な Discord は、内部コンポーネントの一つである「Read States」を Go から Rust に再実装し、パフォーマンスが大幅に向上したことを発表しました。
Discord のホットパスである「Read States」は、特に膨大なリクエストを捌く必要があり、システム自体に高いパフォーマンスが要求されるコンポーネントだそうです。 これまで、Discord の大部分は Go で実装されていましたが、2020 年初頭に Rust へ移行したことが明らかになりました。
最近、Rust のキャッチアップをしていることもあり、なぜ、Discord は Go から撤退して Rust を採用したのか気になったので、公式ブログ を参考にまとめてみたいと思います。

移行の背景
Discord の「Read States」サービスは、ユーザがどのチャネルのどのメッセージを読んだのかを追跡するコンポーネントです。 主に、ユーザが Discord に接続する際、メッセージを送信する際、メッセージを読む際に呼び出されます。 つまり、Read States はアクセス頻度が非常に高いホットパスとなっており、ユーザ体験に直接影響するため、Discord 内のシステムにおいても特にパフォーマンスが要求されることになります。
一方で、Go で実装された Read States は、平均すれば高速に動作しているものの、数分毎にレイテンシスパイクが発生し、高速性が必要だという要件には十分に対応できないという課題がありました。
調査の結果、レイテンシスパイクの原因は Go のコア機能であるメモリモデルとガベージコレクタに起因するものであることが明らかになりました。
ここで、ガベージコレクタとは、プログラムが動的に確保したメモリ領域のうち、断片化したメモリ領域や不要になったメモリ領域を自動的に解放する機能です。 一般に、断片化したメモリ領域や不要になったメモリ領域を自動的に解放することを GC(Garbage Collection) と呼びます。
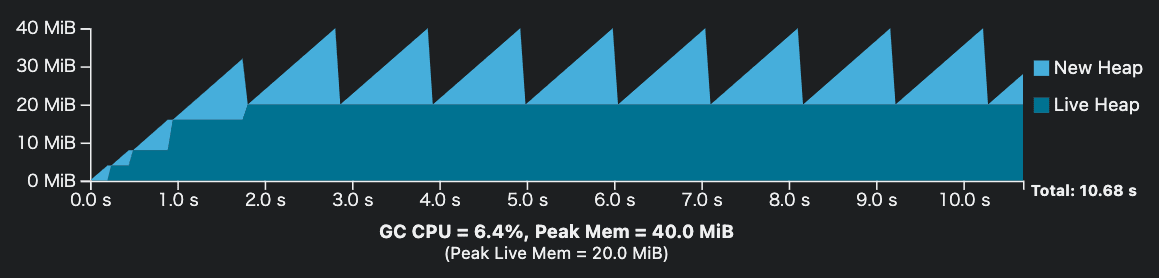
なぜ Go の性能が低下したのか

Go で実装されたサービスがパフォーマンス目標を達成できなかった理由を理解するには、まずサービスのデータ構造やスケール、アクセスパターン、アーキテクチャを知る必要があります。
Discord で読み取り状態情報を保存するのに使うデータ構造は、便宜的に「Read States」と呼ばれます。
Discord には数十億個に及ぶ Read States があり、ユーザとチャネルの組み合わせ毎に 1 つの Read States が必要になります。 各 Read States はいくつかのカウンタを保持しており、例えば、カウンタの一つは、ユーザがチャネル内に持つメンション(@mentions)数を表します。
これらのカウンタをバラバラに更新すると整合性が取れなくなるため、アトミックに更新する必要がある上、頻繁に 0 にリセットしなければなりません。
そこで、アトミックカウンタを高速に更新するために、各 Read States サーバに LRU(Least Recently Used) キャッシュを設け、数百万人のユーザ、数千万個の Read States を管理しており、更新頻度は毎秒数十万回に及びます。
このキャッシュは、データの永続性を確保するために Apache Cassandra で管理されており、イビクション時や、Read States の更新時に必ず 30 秒間のコミットが発生します。 従って、毎秒数万回の書き込み処理が発生することになります。
ここで、イビクション(Eviction) とはキャッシュメモリの容量がいっぱいになった際に、古いデータや不要なデータを削除する操作を指します。
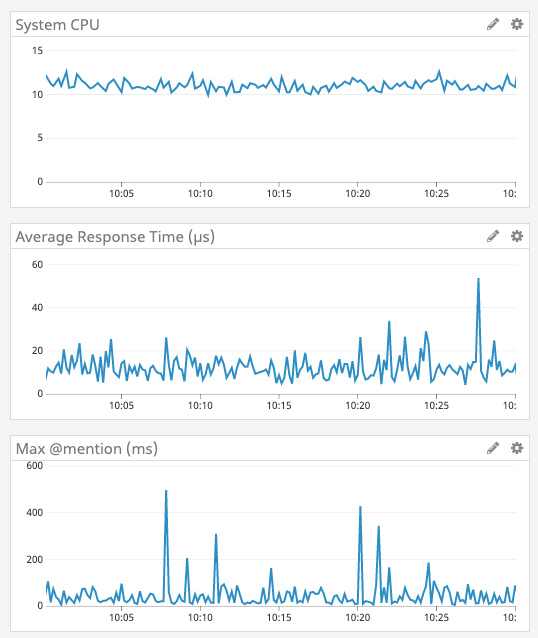
Go で実装した Read States サービスのパフォーマンスは以下の通り、最大メンション数(右下)が不規則に変動しているにも関わらず、CPU 使用率(左上)や平均レスポンスタイム(右上)には、規則的な挙動が現れており、約 2 分毎に CPU 使用率と平均レスポンスタイムがスパイクしている ことが分かります。
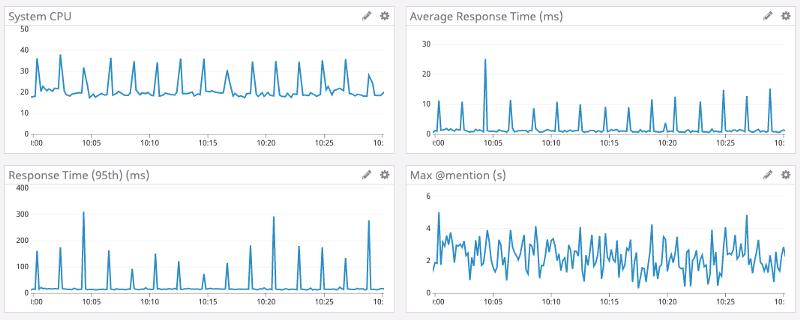
Go のランタイムはガベージコレクタを頻繁に実行し、参照されなくなったメモリ領域を見つけると、解放します。 つまり、キャッシュのイビクションを実行してもすぐにメモリが解放されるわけではなく、ガベージコレクタがメモリ領域が使用されていないかを判断するまで待機する必要があります。
また、ガベージコレクションの実行中は、空きメモリ領域を判断するために様々な計算処理を進める必要があるため、プログラムの速度が一時的に低下する可能性もあります。
一方で、Discord の Go コードは非常に効率的に記述されており、メモリの割り当て回数も十分に少なくなっているため、ガベージコレクションが頻繁に発生するのはおかしいと開発チームは考えました。
調査の結果、Discord 側の実装ではなく、Go のランタイムが少なくとも 2 分毎にガベージコレクションを強制的に実行している ことだと判明しました。
Go ランタイムのガベージコレクタは以下のような実装となっています。
// forcegcperiod is the maximum time in nanoseconds between garbage
// collections. If we go this long without a garbage collection, one
// is forced to run.
//
// This is a variable for testing purposes. It normally doesn't change.
var forcegcperiod int64 = 2 * 60 * 1e9
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
// (省略)
// check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
var list gList
list.push(forcegc.g)
injectglist(&list)
unlock(&forcegc.lock)
}
if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now {
lasttrace = now
schedtrace(debug.scheddetail > 0)
}
}
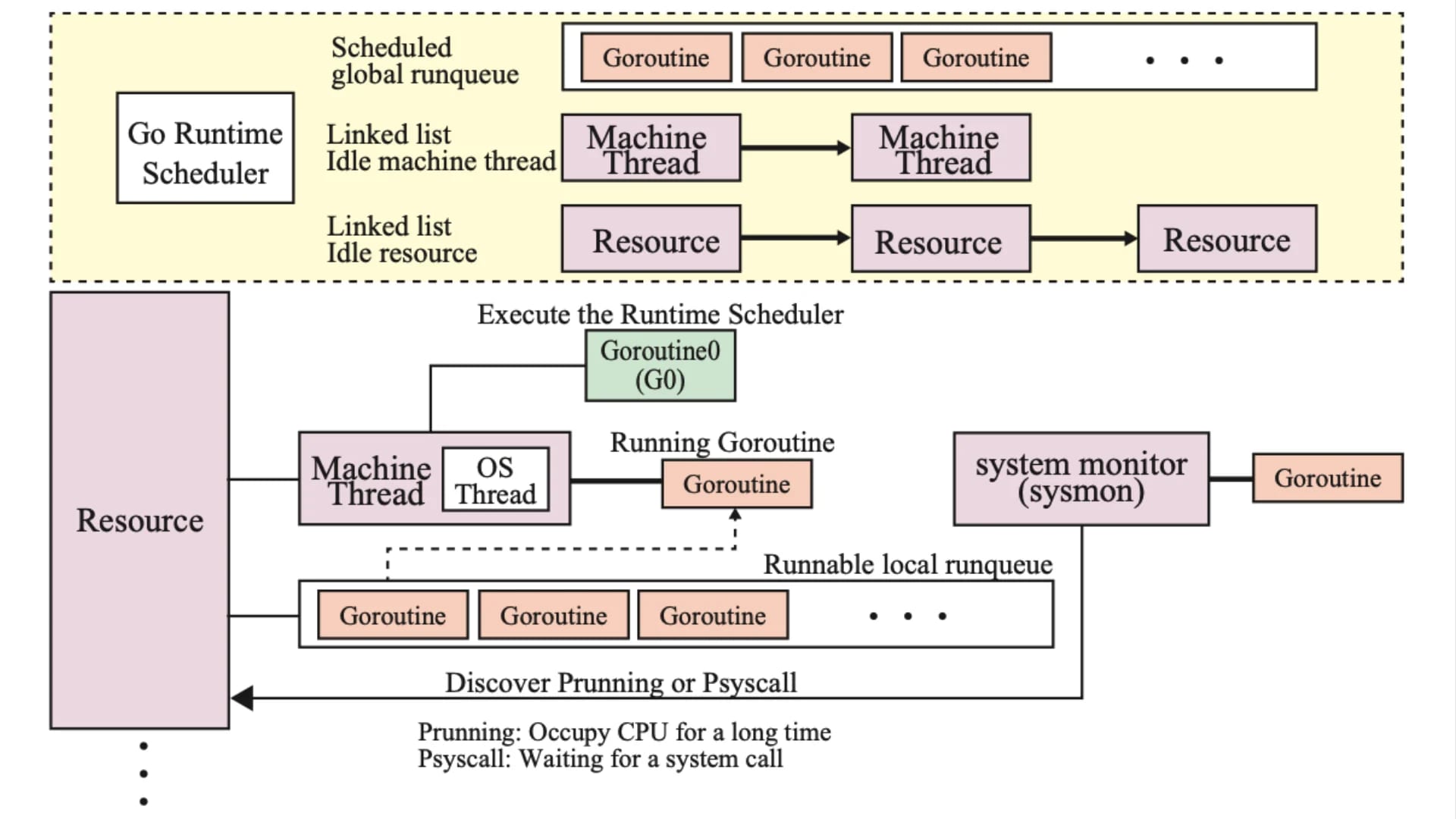
ここで、sysmon とは、ランタイムコンポーネントの一つで、主にガベージコレクションのコントローラとしての機能を担います。 sysmon は他のスケジューラによって中断されないよう、特定の OS スケジューラから切り離して実行されます。
(gcTrigger{kind: gcTriggerTime, now: now}); t.test()に基づき GC をトリガすべきか判定atomic.Load(&forcegc.idle) != 0においてforcegc.idleが 1 の場合、システムがアイドル状態と判断して強制的に GC を実行
forcegc.g は GC を実行する Goroutine(runtime.forcegchelper)で、injectglist(&list) によってスケジューラに投入することで GC を強制的に開始します。
また、forcegc.idle は システム(M と P)がアイドル状態であるかを表すフラグで、一定時間(2 分)アイドル状態が続いた場合、sysmon() 関数によって強制的に GC がトリガされます。 つまり、プログラムが長期間アイドル状態になっていても、2 分毎に GC を実行してメモリを回収し、メモリ使用量を制御する仕組みとなっています。
forcegcperiod は「It normally doesn't change」となっており、基本的に変更されないようです。
Go ランタイムの仕組みについては こちら のブログでも紹介しています。
Go の仕様を受け、開発チームはランタイム自体のガベージコレクタの挙動を変えるべく、オンザフライで GC Percent の値を変えてみたところ、どのような値を設定しても挙動は変わりませんでした。 この理由は、Discord 側の処理でガベージコレクションが頻繁に発生するようにメモリを迅速に割り当てることができなかったためです。
さらに調査を進めた結果、2 秒毎に発生する巨大なスパイクには、別の原因があることが明らかになりました。 それは、ガベージコレクタがメモリ領域が本当に参照されなくなったかを判断する際に、LRU キャッシュ全体をスキャンする必要があったためです。
つまり、システムの動作を高速化するためには、LRU キャッシュのサイズを小さくする 必要がありました。 そのため、LRU キャッシュのサイズを変更できるようにサービスに新たな設定を追加し、サーバ毎に多数のパーティション化された LRU キャッシュを持つようにアーキテクチャを変更しました。 これにより、ガベージコレクションによるスパイクの発生が実際に小さくなったことが確認されました。
しかし、この解決策には副作用があり、LRU キャッシュのサイズを小さくすると、キャッシュ内にユーザの読み取り状態が存在する確率(キャッシュヒット率)が低下するため、今度はデータベースへのアクセスが増えて遅延が発生するようになりました。
Rust を導入する以前は、この LRU キャッシュのサイズと遅延のバランスを調整しながら、可能な限り 2 秒毎のスパイクを小さく抑えるような運用が必要になっていました。
なぜ Rust を採用するのか

Discord はなぜ、Go の移行先として Rust を選定したのか。
端的に述べると、パフォーマンス低下の最も大きな原因となっている、ガベージコレクタのオーバーヘッドと運用負荷を無くすため です。
Rust には、そもそもガベージコレクションという概念が存在しません。 つまり、Rust で実装すれば Go で生じた平均レスポンスタイムの急増は改善されるだろうという試みです。
Rust は 所有権(Ownership) という仕組みによりメモリセーフティな設計となっています。 メモリの所有権とは、どの変数・値がメモリ上のデータを管理(所有)し、それをどのように解放するかを決定する仕組みです。
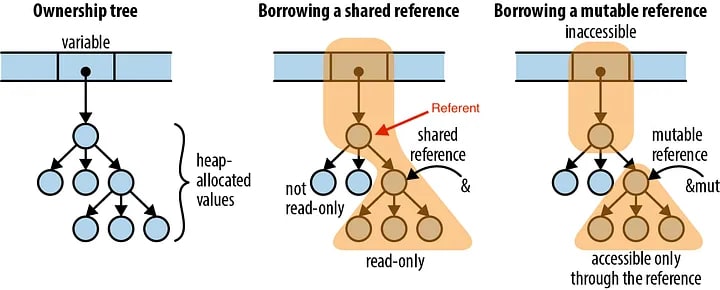
C や C++ では、手動で malloc() や free() を使ってメモリを管理する必要がありました。
また、Go では、メモリの確保と解放の機能が自動化され、不要なメモリリソースはガベージコレクションによって 解放(free) される仕組みとなっていました。
一方で、Rust の場合は、ある変数がメモリの所有者である場合、その変数がスコープから外れた際は、即座にメモリが 解放(drop) されます。 これによりメモリリークや二重解放といったバグを防ぐことができます。
/* src/main.rs */
fn main() {
let s1 = String::from("Hello, World!"); // s1 がメモリの所有者
let s2 = s1; // 所有権が s1 から s2 に移動(Move)
println!("{}", s1); // s1 は所有権を失っているためコンパイルエラーとなる
}
$ cargo run
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:20
|
2 | let s1 = String::from("Hello, World!");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{}", s1);
| ^^ value borrowed here after move
|
このように、Rust では変数が所有権を持ち、所有権が移ると元の変数は使えなくなるというルールがあります。
また、所有権の移動を防ぐには、借用(Borrowing)や 参照(References) という仕組みを使います。
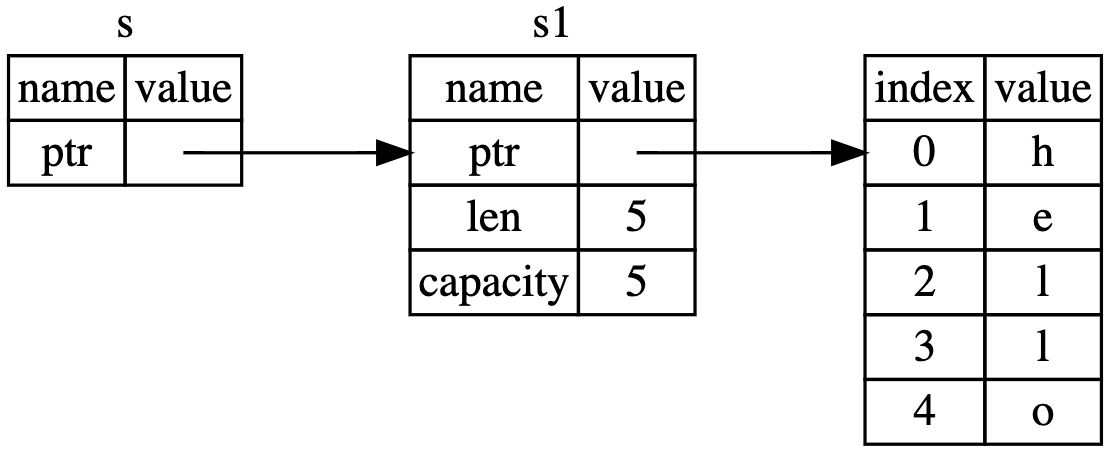
/* src/main.rs */
fn main() {
let s1 = String::from("Hello, World!");
let s2 = &s1; // 借用(s1 の参照を s2 に渡す)
println!("{}", s1); // s1 は有効なまま
println!("{}", s2); // s2 も参照を通じて利用可能
}
$ cargo run
Compiling hello_world v0.1.0 (/Users/ren510dev/tmp/hello_world)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/hello_world`
Hello, World!
Hello, World!
つまり、Rust はデータ競合やメモリリークを、ランタイムではなく、コンパイラが取り仕切るため、実装上のメモリ管理のバグやリークは基本的に発生しないということです。
これらのことから、Read States サービスの Rust 版では、LRU キャッシュからの Read States のイビクションが実行されると、Read States が使っていたメモリ領域は直ちに解放できます。 加えて、Rust にはメモリを解放すべきかどうかを判断するランタイムプロセスも存在しないため、Go のようなガベージコレクタの制御を気にする必要はありません。
Async Rust の導入
Rust のリリースチャネルは次の 3 種類 となっています。
- Stable(安定版)
- 一般ユーザ向けに提供される正式なリリース版
- 安定した API・機能のみが含まれる
- 約 6 週間毎にアップデートされる
- Beta(ベータ版)
- 次回の安定版リリース候補
- 新しい変更点を含むが、ある程度のテストが実施済み
- Nightly(開発版)
- Rust 特有のリリースチャネル
- 毎晩自動的にコンパイルされる最新開発版
- 未安定な新機能や改善が含まれる
Read States サービスを再実装した当時、Rust の安定版では Async Rust のサポートが不十分でしたが、ネットワークサービスでは非同期プログラミングが必須となります。 Async Rust を有効にしたコミュニティ版のライブラリがいくつか存在したものの、利用に際して複雑な手順が必要であり、不具合が生じた場合のエラーメッセージも非常に分かりにくいという課題がありました。
丁度この頃、Rust の開発チームは、非同期プログラミングが容易になるよう精力的に取り組んでおり、Rust の Nightly チャネルで、非同期プログラミング機能が強化された不安定版が入手できるようになりました。 そこで、Discord は Nightly リリースを導入し、問題が発生した際には Rust の開発チームと協力して対処していきました。
Discord の積極的な介入もあり、現時点での安定版は Async Rust もサポートしているようです。
移行前後のパフォーマンス比較
Read States サービスのコードリプレイスは非常にスムーズに行われ、Go から Rust に大まかに変換した後、スリム化(最適化)されました。
Discord の開発チームが、リプレイス作業をスムーズに進められた理由としては Generics のサポートがあったからだとしています。
Rust は、どのような型でも受け付けることができる Generics をサポートしており、これは当時の Go にはなかった画期的な仕組みでした。(Go も 1.18 から Generics に対応しています。)
Generics の導入により、冗長なコードの削減と、所有権によるメモリモデルを活かすことで、メモリ保護に関する Go の一部のコードも廃止することができました。
また、負荷試験の結果、直ぐに良好な結果が確認され、Rust 版の Read States サービスの平均レンスポンスタイムは Go 版の時と同等で、スパイクも生じないことが明らかになりました。
注目すべきは、Rust 版では当初、基本的な最適化しか行っていないにも関わらず、手動で徹底的にチューニングされていた Go 版のパフォーマンスを上回った点です。 これは、Rust で効率的なプログラムを書くのがいかに簡単かを示す良い実例 だとされています。
Discord は、さらに Rust 版の Read States サービスを最適化するべく、以下のパフォーマンスチューニングを実施しました。
- LRU キャッシュの HashMap を BTreeMap に変更
- 初期のメトリクスライブラリを、モダンな Rust の並行性を使用したものに変更
- メモリコピーの回数を削減
LRU キャッシュの HashMap から BTreeMap への変更は、メモリ使用量の最適化のためとされています。
LRU キャッシュ は最近使われたデータを保持し、古いデータを削除するキャッシュアルゴリズムです。
HashMap とは、キーと値のペアでデータを管理するためのデータ構造 で、Rust の標準ライブラリ(std::collections)に組み込まれています。 HashMap は、内部でハッシュテーブルを使用し、キーから値への素早い検索を で実現します。
ただし、ハッシュを使用するため、中のデータの順序は保証されません。
一方の、BTreeMap は、キーと値のペアをキーの順序を保持したまま管理するデータ構造 です。 内部では B 木(B-Tree)という構造でデータを管理しており、データをキーの昇順で格納します。 データ探索に要する計算量は であるため、定数時間で処理できる HashMap と比較してやや遅くなります。
キャッシュの局所性(Cache Locality)の観点では、HashMap がハッシュテーブルを使用することで、データがランダムなメモリアドレスに分散されやすいのに対し、BTreeMap は要素を B 木のノードにまとめて保存するため、一度に複数の要素をメモリアクセスできる確率(ヒット率)が高くなります。
また、BTreeMap はバランスの取れた木構造を維持するため、データ分布が偏らずメモリの使用効率が良くなるというメリットがあります。
Rust 版は、シングルカナリアノードに展開され、その後サービスの本格稼働が開始されました。 現在では、ほぼ全てのコンポーネントが Rust に移行されているようです。
最終的に Read States サービスの Go 版と Rust 版で、CPU 使用率と平均レスポンスタイムを比較すると、以下の通り改善されました。
ここで、紫が Go 版、青が Rust 版を示しています。
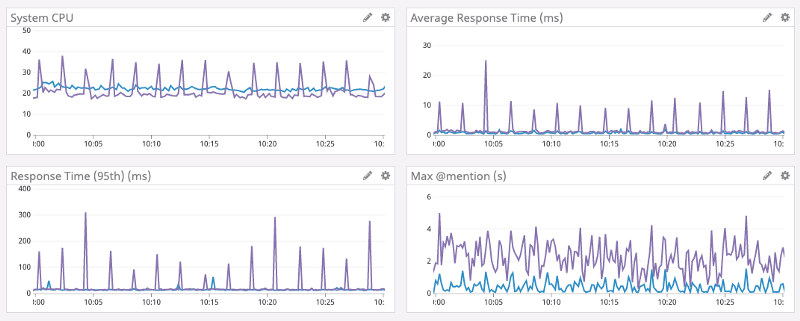
Rust 版は CPU 使用率の変動がほぼなく、平均レスポンスタイムのスパイクも発生していないことが分かります。
キャッシュのチューニング
Rust への移行でパフォーマンスの改善を確認した後、Discord は LRU キャッシュのキャパシティを元に戻す作業を実施しました。 前述の通り、Go 版ではガベージコレクションのオーバーヘッドを小さくするため、メモリ領域のスキャン範囲を最小限に抑える目的で LRU キャッシュを縮小していました。
一方で、Rust にはガベージコレクションが存在せず、LRU キャッシュサイズの上限を引き上げることで、ユーザデータのヒット率が向上すると考えました。
実際に、ボックス部分(おそらくヒープ領域を指す Box<T> ?のことかと思われる)のメモリ容量を増やし、より少ないメモリで済むようにデータ構造を最適化し、Read States が 800 万個入るサイズに LRU キャッシュのキャパシティを増やしました。
その結果、CPU 使用率は 10 ポイント程度減少し、平均レスポンスタイムは 10 分の 1 程度にまで下がり、期待通りパフォーマンスの改善が見受けられました。
Rust のメリット
最後に、Rust の優れた点は、エコシステムを備えていることだと述べられています。
Rust の エコシステムは急速に発展しており、活発なコミュニティ活動によって様々なライブラリやフレームワークの改善が頻繁に行われています。
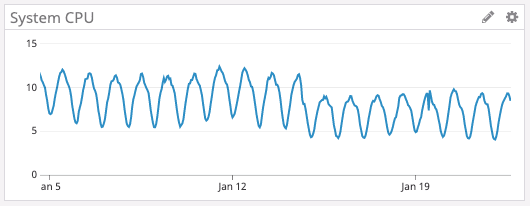
また、tokio(Discord が採用している Rust の非同期ランタイム)は、version 0.2.0 にアップグレードするだけで、追加の最適化作業をしずとも CPU 使用率を下げることができたと報告されています。
下記のグラフから、16 日以降 CPU 使用率が低下していることが分かります。
Discord は、ゲーム SDK や Go Live のビデオキャプチャとエンコード、Elixir NIF、その他バックエンドサービス等、ソフトウェアスタックの大部分を Rust で実装しています。
また、メモリ安全性、型安全性が保証されており、シンプルな実装で安全な実行が可能であることから、今後も様々なコンポーネントで積極的に Rust を採用していくと述べています。
まとめ
今回のブログでは、Discord が Go から Rust に移行した背景について、公式ブログを参考にまとめてみました。 Discord の事例は非常に興味深く、Go の副作用や課題、それに対する Rust の優位性を知ることができました。
最近、Rust を勉強しはじめたばかりですが、所有権の概念はこれまでの言語にはない独特な考え方で、メモリ管理の実装ミスに起因するバグやリークの問題を根本的に解決することができます。
まだまだ、Go に比べるとコミュニティの大きさやエコシステムは発展途上だと思いますが、フレームワークが充実すれば、特にシステムプログラミングの分野では非常に重宝する言語になることが予想されます。
今後も、Rust のキャッチアップに励んでいきたいと思います。
参考・引用
- Why Discord is switching from Go to Rust
- Using Rust to Scale Elixir for 11 Million Concurrent Users
- Why Discord is Moving many Services from Go to Rust
- How Discord Moved from Go to Rust
- Go GC
- Understanding Ownership in Rust with Examples
- B-Tree Indexing vs. Hash Indexing vs. Graph Indexing: Which is Right for Your Database
- HashMap and BTreeMap in Rust Collections
- Measuring the overhead of HashMaps in Rust
- BTreeMap vs HashMap
- 実装言語を「Go」から「Rust」に変更、ゲーマー向けチャットアプリ「Discord」の課題とは