高パケットレート環境下におけるネットワークスタック最適化
- Authors

- Name
- ごとれん
- X
- @ren510dev
目次
- 目次
- はじめに
- ネットワークスタックの基本概念
- ハードウェア割り込み
- ソフトウェア割り込み
- Linux NAPI
- NAPI によるパケット受信処理
- NAPI の落とし穴
- CPU の負荷集中
- マルチコアスケーリング
- RSS:Receive Side Scaling
- RPS:Receive Packet Steering
- RFS:Receive Flow Steering
- パケットの分割処理と再結合処理
- MTU:Maximum Transmission Unit
- NIC オフロード機能
- TSO:TCP Segmentation Offload
- UFO:UDP Fragmentation Offload
- GSO:Generic Segmentation Offload
- GRO:Generic Receive Offload
- まとめ
- 参考・引用
はじめに
ネットワーク経路上のルータ(ソフトウェアルータ)をはじめとし、ロードバランサやキャッシュサーバ等のミドルウェアは、特に高いパケットレートを処理する必要があります。 これらのシステムは、膨大なパケットを迅速かつ効率的に処理するために、物理および論理の両方で高いパフォーマンスが要求されます。
ネットワークトラフィックの処理は、コンピュータシステムにとって非常にリソース集約的な作業であり、高パケットレート環境下では CPU に掛かる負荷が非常に大きくなってきます。 ネットワークミドルウェアでは、多数のクライアントからの要求を捌くために、マシン内の処理に起因する負荷を効率的に分散・軽減させる必要があります。
アプリケーションをマルチコア環境でスケールさせる際、CPU 負荷が特定のコアに集中することでシステム全体のパフォーマンスが低下する場合があります。 この問題を解決するため、Linux ネットワークスタックの NAPI や NIC のオフロード機能が、CPU の割り込み処理を効率化し、パフォーマンスを最適化する上で重要な役割を果たします。
また、マルチコアスケーリングを効果的に実現するためには、NIC の RSS やカーネルの RPS/RFS といった機構も活用する必要があります。 これらの技術により、パケット処理を複数の CPU コアに分散させ、システム全体のパフォーマンスを最適化することが可能です。
今回のブログでは、高パケットレート環境下において膨大なリクエストデータを捌くために Linux カーネルが取った対策について紹介したいと思います。
ネットワークスタックの基本概念
以下の図は、Linux ネットワークスタックの全体概要を大まかに示しています。
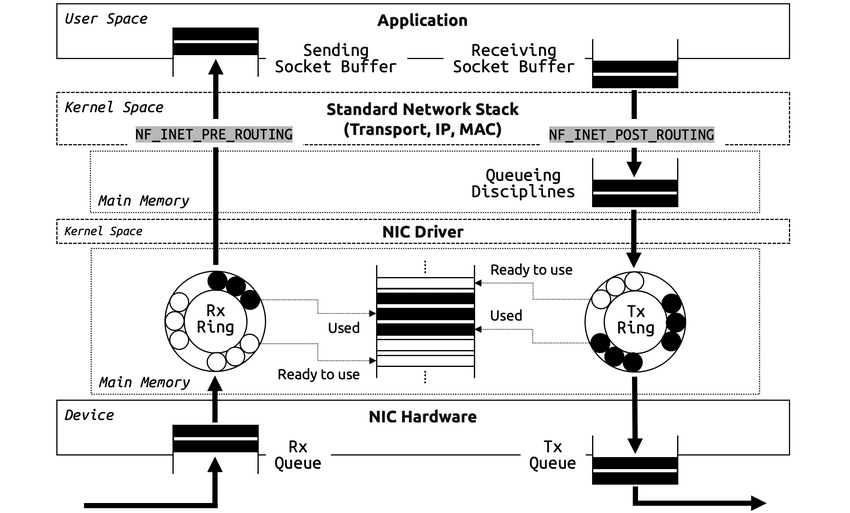
ネットワークスタックにおけるパケット処理は、まず、NIC(Network Interface Card)がパケットを受信することから始まります。 NIC とは、コンピュータをネットワークに接続し、データの送受信を行うためのハードウェア装置です。

ハードウェア割り込み
ホストマシンが NIC を介してパケットを受信すると、CPU に通知するための ハードウェア割り込み(hardirq:Hardware Interrupt Request) が発生します。 ハードウェア割り込みは、ハードウェアデバイス(NIC)が特定のイベント(パケット受信等)を CPU に知らせるための手段です。 割り込みが発生すると、CPU は現在のタスクを一時中断し、割り込みハンドラ(ISR:Interrupt Service Routine) と呼ばれる特定のコードを実行します。
割り込みハンドラ(割り込みサービスルーチン)とは、割り込み受け付けによって起動される OS やデバイスドライバのコールバックルーチンです。 前述のようなハードウェアによる割り込みか、ソフトウェアの割り込み命令で起動され、ハードウェア機器のための処理をしたり、システムコール等の CPU モードの移行を行ったりします。 割り込みハンドラは、イベントの内容によりタスクを完了するまでに要する時間も様々です。
高パケットレート環境下では、NIC が非常に多くのパケットを受信し、それに伴って頻繁にハードウェア割り込みが発生することになります。 この連続的な割り込み発生により、CPU の負荷が急増し、他の重要な処理が遅延する原因となります。 ハードウェア割り込みは、優先度の高いタスクであるため、CPU は通常のスケジューリングを中断して割り込み処理にリソースを注ぎ込みます。 結論、ハードウェアレベルの割り込みだけでは柔軟さに欠けると言えます。
ソフトウェア割り込み
このボトルネックを解消するために登場するのが、ソフトウェア割り込み(softirq:Software Interrupt Request) です。 ソフトウェア割り込みは、ハードウェア割り込みの後に実行されるソフトウェアレベルの割り込み処理です。
ソフトウェア割り込みでは、詳細なパケット処理はキューイングされ、主にプロトコルスタック内で実行されます。 これにより、ハードウェア割り込みによるリアルタイム性を確保しつつ、詳細な処理は後回しにできるため、CPU の負荷を軽減することが可能です。
また、ソフトウェアによる制御が可能なことから、システムによって適切なタイミングで実行することができ、他のタスクとのバランスを取りながら柔軟に調整することが可能です。
Linux NAPI
Linux における割り込み処理を用いたパケットの受信フローを確認してみます。 実際に、Linux kernel 2.6 からは割り込み処理に加え、ポーリング(Polling) を組み合わせた NAPI(New API)という機構でパケットを受信します。
ポーリングとは、先ほどの NIC から CPU に向けた割り込み処理とは反対に、CPU 側から定期的に NIC の受信バッファを確認し、新しいパケットが届いていた場合に処理を開始する方式です。
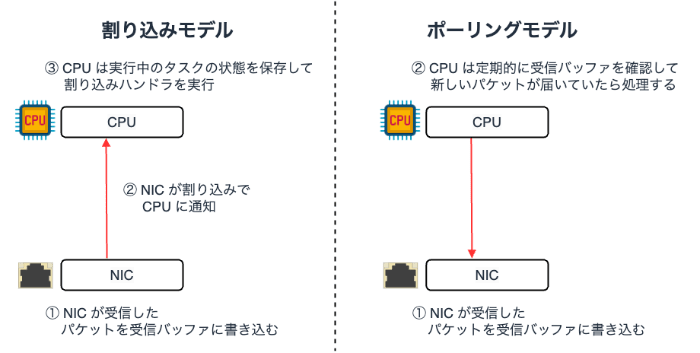
割り込みモデルとポーリングモデルのメリット・デメリットは次の通りです。
| モデル | メリット | デメリット |
|---|---|---|
| 割り込みモデル | • パケットの受信を CPU が即座に検知できるため遅延が小さい | • 割り込みによって生じるコンテキストスイッチが非常に重い • 頻繁なパケット I/O が発生する環境下では性能劣化を招く(※1 Receive Livelock) |
| ポーリングモデル | • コンテキストスイッチによる処理コストが発生しない | • ポーリングのタイミングによっては遅延が発生する • タイミングが遅れることで全体の処理にも影響が及ぶ |
※1)Receive Livelock 参考
- デッドロックしているわけでもないのに、割り込みが溢れてしまうことで割り込みハンドラしか実行していないかのような状態に陥ること
- 割り込み処理はかなり高い優先度を割り当てられているため、パケット受信の際に何も考えず割り込みを発生させると、他の処理に一切手を着けられなくなる
以上のメリット・デメリットを踏まえ、NAPI では、両者の良い所取りをしたパケット受信機構となっています。
NAPI は、基本的には割り込みモデルで動作しますが、パケットを受信した際は、割り込みを無効化し、処理が完了するまではポーリングモードで動作します。 その後、パケットの処理が完了したら、再度割り込みを有効化し、これを繰り返します。
具体的には、一旦パケットを受信したらハードウェア割り込みを禁止して、CPU が NIC の受信バッファ上のパケットをフェッチします。 パケットレートが高ければ、禁止からフェッチまでの間に NIC の受信バッファに複数のパケットが積まれるため、1 回のポーリングでそれらをまとめてバルクフェッチできます。
NAPI は、2002 年 11 月にリリースされた Linux kernel 2.4.20 の tg3 ドライバにおいて実装され、順次その他の NIC ドライバでも採用されるようになりました。
現在では、e1000 や igb 等の主要な NIC ドライバは、大抵 NAPI をサポートしているため、典型的な Linux 環境であれば、NAPI で動作していると考えられます。
NAPI によるパケット受信処理
NAPI は主に次の流れでパケットの受信処理を行います。
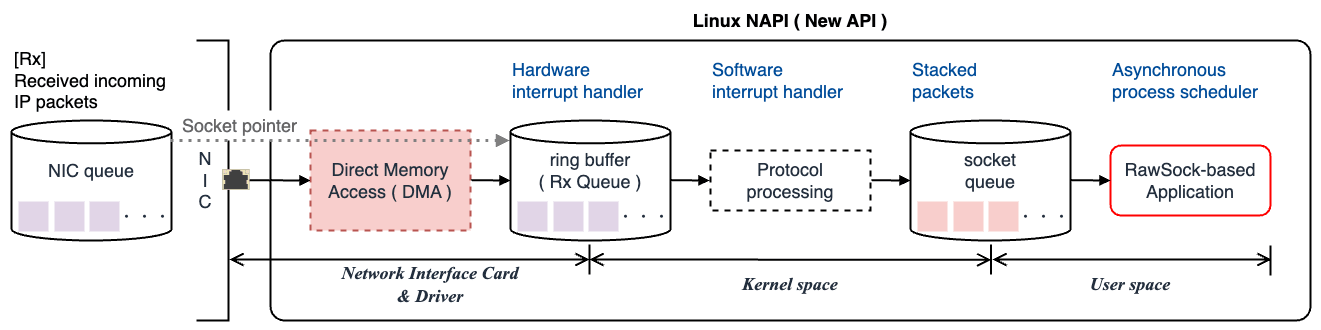
NIC ハードウェア受信
NIC は受信したパケットを内部メモリバッファに格納する。 メモリバッファは FIFO(First-In First-Out)リング構造となっており、NIC に入ってきた順番に処理される。
同時に、NIC は CPU に向けてハードウェア割り込みをかける。 この時、NIC と CPU の間に排他制御は無く、データのやり取りは常に非同期で行われる。
ハードウェア割り込み
ハードウェア割り込みが発生すると、受信パケットをカーネル内部のリングバッファに置く。(厳密には、リングバッファにソケットポインタを渡す)
具体的には、CPU は直接データ転送に関与せず、NIC が受信したパケットを DMA(Direct Memory Access)を介してホストのメインメモリ(RAM)に転送する。 この時、ハードウェア割り込みがかけられた CPU は現在のタスクを一時中断し、割り込みハンドラに移行する。
DMA によってカーネル内部のリングバッファにパケットを転送すると、以後はハードウェア割り込みを無効化し、ポーリングとソフトウェア割り込みをスケジュールしてそちらに任せる。
ソフトウェア割り込み
ポーリングによってリングバッファから一度に複数のパケットを取り出し、ソフトウェア割り込みをスケジュールする。 その後、ソフトウェア割り込みハンドラによって受信パケットを適切なカーネルのプロトコルスタックに渡して処理した後、ソケットキューに積む。
ポーリングが進行する中で、受信バッファ内のパケットが少なくなり、一定の閾値を下回るとポーリング処理が終了し、ハードウェア割り込みを再度有効化する。
アプリケーション受信
システムコールで
read,recv,recvfrom等のソケット関数が呼ばれると、ソケットキューからユーザ空間へ受信データがコピーされる。ここで初めてパケットキャプチャツール(Wireshark, tcpdump 等)や Raw Socket の概念が登場し、受信したパケットをユーザ空間アプリケーションから観測できるようになる。
具体的には、パケットキャプチャツールや Raw Socket はユーザ空間とカーネル空間の間に位置しており、カーネルのプロトコルスタックからユーザ空間へのデータ転送過程で動作する。 ソケットキューにデータが積まれる段階でパケットをキャプチャすることで、ユーザ空間のアプリケーションにデータが渡される前にインターセプトする仕組みになっている。
ソフトウェア割り込みや、Socket API によるユーザ空間でのパケット処理に関しては こちら のブログでも紹介しています。
NAPI は、ハードウェア割り込みとポーリングを組み合わせることで非常に効率的なパケット受信を実現します。
NAPI の落とし穴
一回一回のハードウェア割り込みやソフトウェア割り込みの負荷は当然大したことはありません。 しかし、例えば 64 バイトフレームで 1Gbps のワイヤーレートでパケットを受信したとすると、約 1,500,000 回/sec もの割り込みが発生することになります。 ちなみに、近年の Linux タイマ割り込み回数は 250 回/sec 程度とされています。
先でも述べた通り、割り込み処理は優先度の高いタスクなので、割り込みを受けている CPU は割り込みハンドラの処理以外何もできなくなります。 その結果、CPU のクロック周波数が頭打ちになり、10Gbps イーサネット等のワイヤーレートが向上すると、CPU 処理のうち割り込み処理の割合は次第に大きくなり、パフォーマンスの悪化を招くことになります。 これでは、高性能なネットワーク伝送路を整備しても、ホストマシンの限界が先に訪れてしまいます。
例えば、以下の 16 コアマシンの例では、他のコアが空いているにも関わらず、CPU0 の ソフトウェア割り込み %soft に負荷が集中した結果、CPU0 のみアイドル状態 %idle が著しく低い状態にあります。
CPU の負荷集中
なぜ、単一コアに負荷が集中してしまうのでしょうか。
まず、マルチキュー対応(MSI-X 対応や RSS 対応)NIC でない場合、NIC からのハードウェア割り込み先は特定の CPU に固定されます。 もしランダムに複数の CPU に割り込みをかけたとすると、パケットを並列処理することになり、TCP のような一つのフローに順序制約があるプロトコルの場合、パケットの並べ直しが必要になります。 これは、一般に Reordering(パケットの並べ直し)問題 として知られています。 NIC は、Reordering によるパフォーマンス低下を回避するために、常に同じ CPU にハードウェア割り込みをかけようとします。
さらに、ハードウェア割り込みハンドラでソフトウェア割り込みをスケジュールします。 この時、Linux ではハードウェア割り込みを受けた CPU と同じ CPU にソフトウェア割り込みを割り当てるようになっています。 これは、ハードウェア割り込みハンドラでメモリアクセスした構造体をソフトウェア割り込みハンドラにも引き継ぐことで、CPU コアローカルな L1、L2 キャッシュを効率よく利用するためです。
ここで、L1 キャッシュ、L2 キャッシュとは、主記憶装置(RAM)と CPU コアの間に位置する階層型キャッシュ構造のレベルを指します。
L1 キャッシュ
- 頻繁に繰り返し使用されるデータや命令を格納することで CPU の動作を高速化する
- CPU は高頻度でアクセスするデータを L1 キャッシュに配置して直接アクセスすることで、主記憶装置へのアクセスを最小限に抑えようとする
L2 キャッシュ
- L1 キャッシュの次に位置するキャッシュメモリ
- L1 キャッシュと比較して、大容量であるが速度は劣る
- 一般に L2 キャッシュは、L1 から溢れたデータをキャッシュするために利用される
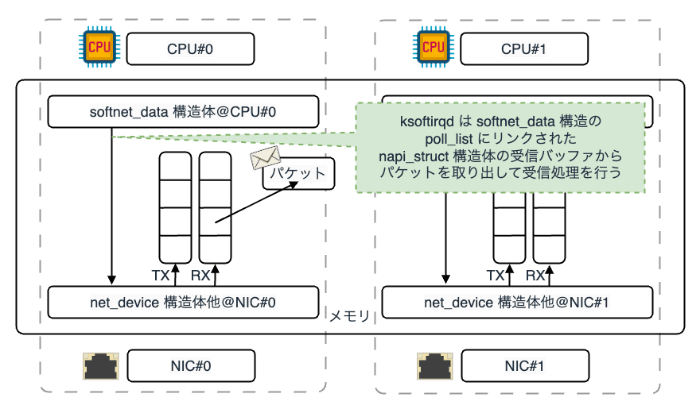
これらが要因となり、特定の CPU にハードウェア割り込みとソフトウェア割り込みが集中することになります。
実際には、割り込み負荷に加えて、アプリケーション(ユーザ空間プロセス)の CPU 負荷 %usr も割り込みがかかっている CPU に偏る傾向があります。 これも、accept() で待ち状態のアプリケーションプロセスが、データ到着時にプロセススケジューラにより、プロトコル処理した CPU と同じ CPU に優先して割り当てるからだと考えられます。
マルチコアスケーリング
CPU コアの負荷集中を解消するための策として、マルチコアスケーリングによるパフォーマンスチューニングがあります。
ネットワークスタックをマルチコアスケールさせるための技術は、大きく
- NIC(ハードウェア)の機能によるもの
- カーネル(ソフトウェア)の機能によるもの
- その両方の機能によるもの
に分類できます。
今回紹介するのは、NIC の機能、つまりハードウェアレベルで実現する RSS(Receive Side Scaling) と、カーネルの機能を使用してソフトウェアレベルで実現する RPS(Receive Packet Steering)/ RFS(Receive Flow Steering) です。 また、RPS の発展した実装が RFS であるため、実質 RSS と RFS ということになります。
RSS/RPS/RFS については、Scaling in the Linux Networking Stack で詳しく説明されています。 RPS/RFS は Linux kernel 2.6.35 以降で実装されています。(RHLE 系は 5.9 ぐらい以降でバックポートされていたみたいです。)
他にも、論文ベースでは、
をはじめとし、ネットワークスタックを高速化させるための様々な手法が提案されています。
RSS:Receive Side Scaling
マルチコアスケールしないそもそもの原因は、特定の CPU にのみハードウェア割り込みが集中することです。 そこで、RSS では、NIC に複数のパケットキューを持たせて、キューと CPU のマッピングを作り、キュー毎にハードウェア割り込み先 CPU を変更します。
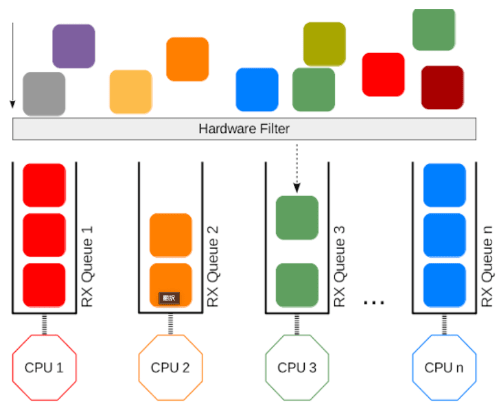
また、Reordering を回避するために、フィルタ により同じフローのパケットは同じキューに接続するようにします。 フィルタの実装は、IP ヘッダとトランスポートヘッダ、例えば src/dst IP アドレスと src/dst ポート番号の 4 タプルをキーとして、キュー番号をバリューとしたハッシュテーブルになります。
ハッシュテーブルのエントリ数は 128 個で、フィルタで計算したハッシュ値の下位 7 bit をキーとしているハードウェア実装が多いようです。
なお、RSS は NIC の機能であるため、ユーザ側で特別な設定をすることはありません。
RPS:Receive Packet Steering
RSS は NIC の機能であるため、そもそも NIC が対応していなければ使えません。 そこで、RPS は NIC 依存を取り除き、RSS 相当の機能をソフトウェア(カーネル)で実現します。
RPS はソフトウェア割り込みハンドラで NIC のバッファからパケットをフェッチした後、プロトコル処理する前に、他の CPU へ コア間割り込み(IPI:Inter-Processor Interrupt)を実行します。 そして、コア間割り込み先の CPU がプロトコル処理してアプリケーション受信処理をします。
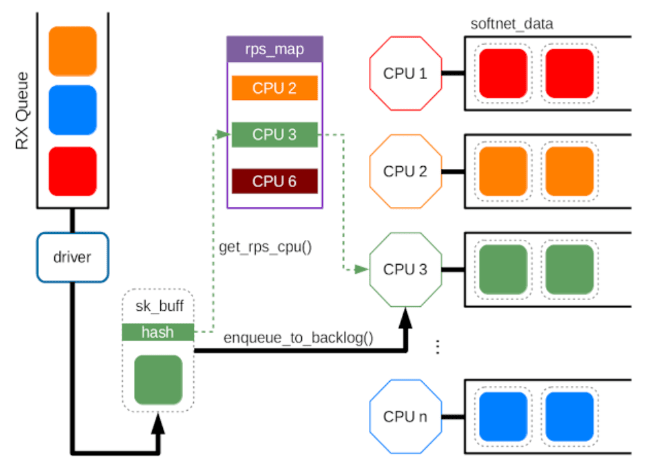
他の CPU の選択方法は RSS とよく似ており、src/dst IP アドレスと src/dst ポート番号の 4 タプルをキーとして、コンシステントハッシュ(Consistent-Hashing)により分散先の CPU が選択されます。
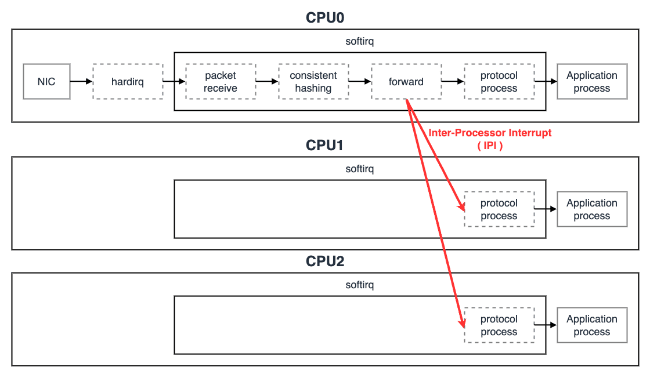
【RPS のメリット】
- ソフトウェア実装なので、NIC に依存しない
- フィルタの実装がソフトウェアなので、新しいプロトコル用のフィルタも簡単に追加できる
- ハードウェア割り込み数を増やさない
RPS を有効化する場合は以下のコマンドを実行します。 ここで、シングルキュー NIC の場合 rx-0 のみで、マルチキュー NIC ならキューの数だけ rx-N が存在します。参考
rps_cpus は分散先の CPU の候補をビットマップで表しています。 "f" の 2 進数表現は 1111 となり、各ビットが下位から順番に CPU0 ~ CPU3 まで対応しています。 ビットが 1 ならば、対応する CPU は分散先の候補になるということです。 つまり、"f" なら CPU0, 1, 2, 3 が分散先の候補となります。 通常は全てのコアを分散先に選択すればよいと思います。
RPS を有効にしても、ハードウェア割り込みを受けている CPU に分散させたくない場合は、その CPU の対応ビットが 0 になるような 16 進数表現に直します。
RFS:Receive Flow Steering
RPS はアプリケーションプロセスまで含めた L1, L2 キャッシュの Locality(局所性)の観点で課題が残ります。 RPS では、パケットフローと CPU のマッピングがランダムに決定されるため、アプリケーションが accept(2) や read(2) を呼んでスリープから復帰する際、スリープ前とは異なる CPU に割り当てられる可能性が高くなります。 これにより、L1 および L2 キャッシュの恩恵を受けにくくなり、パフォーマンスが低下する懸念があります。
このような課題を受け、RFS は RPS を拡張して、アプリケーションプロセスをトレースする機能を追加することでキャッシュ効率を高めます。 具体的には、フローに対するハッシュ値からそのまま Consistent-Hashing で分散先 CPU を決めるのではなく、フローに対するハッシュ値をキーとしたフローテーブルを別に用意して、テーブルエントリには分散先の CPU 番号を書いておきます。 該当フローを最後に処理した CPU が宛先 CPU になるように、recv_message 等のシステムコールが呼ばれたときに、フローテーブルの宛先 CPU を更新します。
パケットフローが同じ CPU で処理されることで、L1, L2 キャッシュのヒット率が向上し、全体的なパフォーマンスの最適化が見込めます。
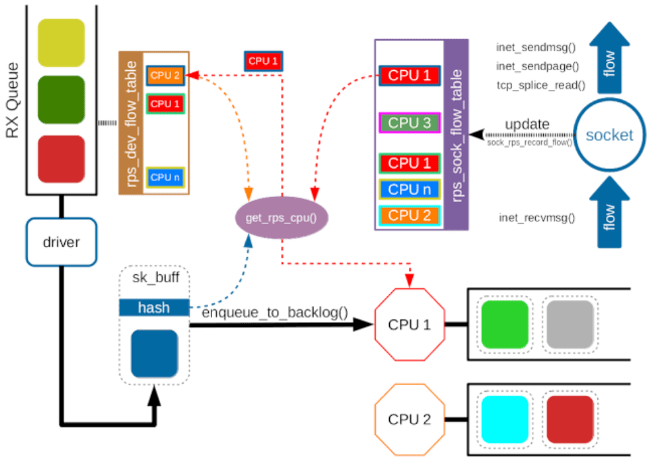
RFS の設定は、RPS の設定の rps_cpus に加えて、rps_flow_cnt と rps_sock_flow_entries を設定します。
rps_sock_flow_entries はシステムグローバルなフローテーブルのエントリ数を設定します。 ローカルポート数(最大接続数)以上を設定しても意味はないので、65536 以下の数値を設定します。 一般に、最大ポート数の半分にあたる 32768 が設定されることが多いようです。
フローテーブルのエントリ数を増やし過ぎるとメモリ使用量が非常に高くなり他のシステムリソースを圧迫する可能性があります。 rps_sock_flow_entries を 32768 に設定するのは、メモリ使用量を大幅に増やさない範囲で、一般的なトラフィックパターンを効率的にハンドリングするのに適当な数だからだと考えられます。
rps_flow_cnt は NIC キュー毎のフロー数を設定できます。 例えば、16 個のキューをもつ NIC において、rps_sock_flow_entries を 32768 に設定した場合、rps_flow_cnt は 2048(32768 / 16)に設定するのが望ましいです。 また、シングルキュー NIC であれば、rps_flow_cnt は rps_sock_flow_entries と同じ値に設定します。
これらの設定は /etc/udev/rules.d や /etc/sysctl.conf に書いておくことで永続化できます。参考
RFS は、HAProxy や pgpool、Varnish 等のインフラミドルウェアで適用した場合にも副作用なく動作することが報告されています。 また、memcached や LVS、その他 Linux ベースのソフトウェアルータにも適用されているようです。
※注意:RFS は Redis や Node.js 等、1 プロセス 1 スレッド(シングルスレッド)で動作するアプリケーションに対しては適用できません。
パケットの分割処理と再結合処理
NAPI は、割り込み処理とポーリングを組み合わせることで、効率的なパケット受信を実現します。 また、RSS や RPS/RFS といった技術でマルチコアスケールさせることで、単一コアへの負荷を分散させ、パフォーマンスを最適化することが可能です。
一方で、高パケットレートな環境においては、これらの技術だけでは不十分な場合があります。
MTU:Maximum Transmission Unit
一般に、インターネット経路には MTU(Maximum Transmission Unit)と呼ばれる一度に送信できる最大転送サイズの制約があります。
イーサネットではデフォルトで MTU は 1500 byte に設定されており、これを超えるパケットを送信する場合は、ネットワーク経路上(正確には経路上に存在するデバイス)でデータを分割します。
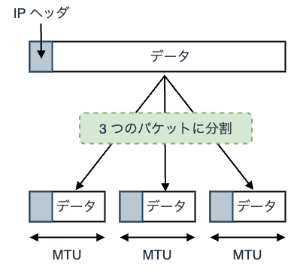
MTU はデバイスによって異なる場合があり、経路に存在するホスト NIC の MTU に基づいて分割処理が行われます。 多くの場合、単一ストリームにおけるアプリケーションデータは、1500 byte を優に超えるため、送信側ではデータを分割(フラグメント)し、受信側では分割されたパケットを再結合(デフラグメント)することで通信が行われます。
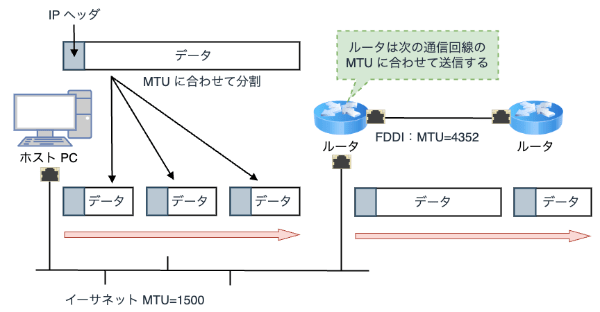
フラグメントにより、単一ストリームのデータ量はさらに増加することになり、CPU はそれらの分割されたパケットを個別に処理することで大きな負荷に繋がります。 そのため、例えマルチコアスケールさせたとしても、ネットワークスタックパフォーマンスの最適化には限界があります。
この問題を解決するためにはパケット送受信において、より低レベルなレイヤで別の効率的な処理方法が必要になります。
NIC オフロード機能
現在では、大抵の Linux ホストマシンが NIC を介してパケットを送受信する際に、通常 CPU が行うパケットの分割・再結合処理を NIC が肩代わり(オフロード)する機能が搭載されています。 これにより、NAPI の一部の処理を NIC が直接実行するため、CPU の負荷を軽減できます。

以下に、主要な NIC のオフロード機能について紹介します。
TSO:TCP Segmentation Offload
TSO(TCP Segmentation Offload)は、MTU を超える TCP ストリームを小さなセグメントに分割する処理を NIC で行う機能です。 TSO は、通常であれば CPU が行う TCP パケットのセグメンテーション処理を NIC にオフロードすることで、CPU の負荷を軽減します。 TSO 機能を有効化しておくと、ジャンボサイズなデータを一括で送信した場合でも、NIC で自動的に分割されるため、CPU のオーバーヘッドが減少し、全体のシステムパフォーマンスが向上します。
TSO の操作コマンドは以下の通りです。
UFO:UDP Fragmentation Offload
TSO の UDP 版です。
UFO(UDP Fragmentation Offload)は、MTU を超える UDP データグラムを小さなフラグメントに分割する処理を NIC で行う機能です。 UFO は、通常であれば CPU が行う UDP パケットのフラグメント処理を NIC にオフロードすることで、CPU の負荷を軽減します。 UFO を有効化しておくと、大規模なデータ転送(例えばビデオストリーミング等)が発生した場合にも、CPU のオーバーヘッドが減少し、全体のシステムパフォーマンスが向上します。
UFO の操作コマンドは以下の通りです。
GSO:Generic Segmentation Offload
GSO(Generic Segmentation Offload)は、Linux カーネルがソフトウェアレベルでジャンボサイズパケットを分割する機能です。 通常、GSO は TSO や UFO がハードウェア(NIC)でサポートされていない場合にソフトウェア的にオフロードをエミュレートするために使用されます。 Linux カーネルで GSO を有効化しておくと、そちらでジャンボサイズパケットを分割してくれるため、CPU の負荷が軽減します。
GSO の操作コマンドは以下の通りです。
GRO:Generic Receive Offload
GRO(Generic Receive Offload)は、カーネルで分割された受信パケットを再結合してソケットキューに引き渡す機能です。 高パケットレート環境下では、フラグメントパケットを頻繁に処理することは CPU にとって大きな負担となります。 GRO を使用することで、受信したパケットをカーネルで再結合し、パケット処理(NAPI による割り込み)の回数を減らすことで CPU のパケット受信処理に伴うオーバーヘッドが減少し、全体のパフォーマンスが最適化されます。
GRO の操作コマンドは以下の通りです。
GRO が実行されるタイミング
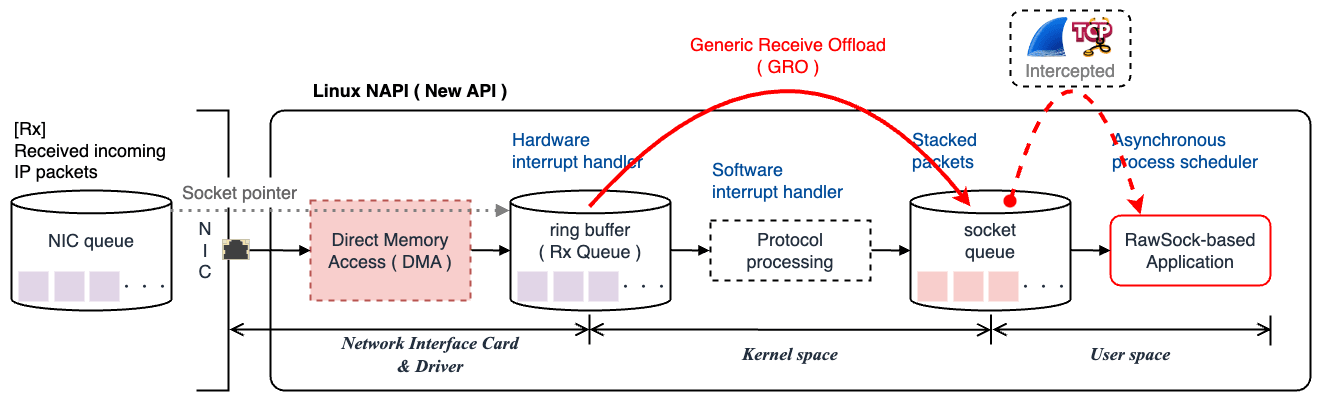
NAPI の場合、NIC がパケットを受信すると、ハードウェア割り込みが発生し、その後ポーリングとソフトウェア割り込みがスケジュールされます。 ハードウェア割り込みによってカーネルのリングバッファに渡されたパケットは、次にソフトウェア割り込みによってフェッチされます。 このタイミングで GRO が実行され、同一フローに属する複数のフラグメントパケットを再結合します。 その後、GRO が再結合したパケットはカーネルの TCP/IP プロトコルスタックに渡り、プロトコル処理された後、ソケットキューに積まれます。
そのため、パケットがユーザ空間に渡った後は、再結合後のデータが観測されます。 実際に、GRO が有効化されたホストマシンで Wireshark を使って確認してみると、MTU(= 1500)を超えるパケットが観測されていることが分かります。

まとめ
高パケットレート環境下でのネットワークスタックの最適化は、システムパフォーマンス延いてはサービス品質向上のために不可欠です。 今回のブログでは、Linux カーネルが提供する主要技術を活用し、ホストマシンの処理を効率化する仕組みについて紹介しました。
Linux カーネルの機能である NAPI は割り込みとポーリングを組み合わせることで、非常に効率的なパケット受信を実現します。 また、RSS や RPS/RFS を利用することで、パケット処理を複数の CPU コアに分散し、負荷の集中を防ぎます。 さらに、NIC のオフロード機能を活用することで、CPU の負荷を軽減し、全体のパフォーマンスを最適化することが可能です。
これらの技術を効果的に組み合わせることで、システム効率とパフォーマンスを最大限に引き出し、高負荷なネットワークミドルウェアでも安定した運用が見込めます。
Linux におけるパフォーマンス最適化の仕組みは数え切れない程ありますが、今回の内容は特に主要な技術であるため、内部の仕組みを知っておくことが非常に重要だと思いました。 現在開発中の独自ネットワークプロトコルや、それを提供するアダプタデバイスのチューニングにおいても役立てていきたいと思います。