RaspberryPi で構築する Bare-Metal Kubernetes - 構築編
- Authors
- Name
- ごとれん
- X
- @ren510dev


目次
- 目次
- はじめに
- 全体の流れ
- 1. Kubernetes のインストール
- パッケージ追加
- kubelet / kubectl / kubeadm のインストール
- スワップの無効化
- カーネルパラメータの変更
- Cgroup の変更
- 2. Kubernetes の初期設定
- Control-Plane のデプロイ
- Data-Plane のデプロイ
- クラスタ情報の更新
- 別のマシンから接続
- Tips:トラブルシューティング
- 3. アプリケーションのデプロイ
- デプロイと公開
- MetalLB の追加
- 4. 【番外編】MetalLB の仕組み
- ベアメタル環境のロードバランサ
- MetalLB のアーキテクチャ
- MetalLB L2 モード
- L2 モードのフェールオーバ
- まとめ
- 参考・引用

はじめに
このブログは『RaspberryPi で構築する Bare-Metal Kubernetes』の構築編です。 準備編では、機器類の準備、セットアップ、各種 OSS の選定と全体設計について紹介しました。
構築編では、セットアップした RaspberryPi に Kubernetes をインストールして Control-Plane 1 台、Data-Plane 3 台のクラスタを構築し、アプリケーションをデプロイして公開してみます。 本記事では MetalLB の仕組みについても簡単に紹介します。
前回のブログは こちら から読めます。
全体の流れ
以下の流れで作業します。
【準備編】準備・設計
- 機器類の準備: RaspberryPi 等の必要機器を準備します。
- 技術選定:主に CRI / CNI / LB を選定します。
- ネットワーク設計:ネットワーク構成と IP アドレスレンジを決定します。
- RaspberryPi の初期設定:OS のインストールとホストマシンの基礎設定をします。
【構築編】クラスタ構築 ⭐️ 本ブログ ⭐️
- Kubernetes のインストール:依存パッケージの追加とカーネルパラメータを設定します。
- Kubernetes の初期設定:Control-Plane / Data-Plane を構築します。
- アプリケーションのデプロイ:アプリケーションを追加して MetaLB で公開します。
- 【番外編】MetalLB の仕組み:MetalLB の仕組みについて紹介します。

【エコシステム編】エコシステム整備
- モニタリング基盤の整備:クラスタメトリクスを収集して監視基盤を構築します。
- GitOps の整備:GitHub とベアメタル Kubernetes を接続します。
1. Kubernetes のインストール
RaspberryPi の基本的な設定ができたら Kubernetes をインストールしていきます。

使用するバージョンは以下の通りです。
| ソフトウェア | バージョン |
|---|---|
| Kubernetes(kubeadm) | v1.31.5 |
| KVS(etcd) | v3.5.15 |
| CRI(containerd) | v1.7.25 |
| CNI(flannel) | v0.26.3 |
ここから先は こちら のコードを参考に説明します。
パッケージ追加
はじめに依存パッケージをインストールします。
#!/bin/bash -e
SCRIPT_DIR=$(
cd $(dirname $0)
pwd
)
apt update && apt upgrade -y
while read line; do
DEBIAN_FRONTEND=noninteractive apt install $line -y
done <${SCRIPT_DIR}/Aptfiles
apt list --installed
### パッケージのインストール
$ cd ./scripts/packages
$ sudo ./apt.sh
kubelet / kubectl / kubeadm のインストール
次に Kubernetes v1.31.5 をインストールします。 主に kubelet / kubectl / kubeadm の 3 つのコンポーネントを追加します。参考
#!/bin/bash
KUBERNETES_VERSION="1.31"
curl -fsSL https://pkgs.k8s.io/core:/stable:/v${KUBERNETES_VERSION}/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo "deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v${KUBERNETES_VERSION}/deb/ /" | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt update
sudo apt install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
kubelet --version
kubectl version
kubeadm version
systemctl enable kubelet
systemctl status kubelet
### マイナーバージョンを指定してインストール
$ cd ./scripts
$ sudo ./install.sh
インストールが終わったら確認します。
### パッケージ
$ dpkg -l | grep kube
hi kubeadm 1.31.5-1.1 arm64 Command-line utility for administering a Kubernetes cluster
hi kubectl 1.31.5-1.1 arm64 Command-line utility for interacting with a Kubernetes cluster
hi kubelet 1.31.5-1.1 arm64 Node agent for Kubernetes clusters
ii kubernetes-cni 1.5.1-1.1 arm64 Binaries required to provision kubernetes container networking
### kubelet
$ kubelet --version
Kubernetes v1.31.5
### kubectl
$ kubectl version
Client Version: v1.31.5
Kustomize Version: v5.4.2
The connection to the server localhost:8080 was refused - did you specify the right host or port?
### kubeadm
$ kubeadm version
kubeadm version: &version.Info{Major:"1", Minor:"31", GitVersion:"v1.31.5", GitCommit:"af64d838aacd9173317b39cf273741816bd82377", GitTreeState:"clean", BuildDate:"2025-01-15T14:39:21Z", GoVersion:"go1.22.10", Compiler:"gc", Platform:"linux/arm64"}
### kubelet の実行ステータス(この時点では dead となっている)
$ sudo systemctl status kubelet
○ kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/lib/systemd/system/kubelet.service; enabled; preset: enabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
└─10-kubeadm.conf
Active: inactive (dead)
Docs: https://kubernetes.io/docs/
スワップの無効化
Kubernetes は物理メモリをベースにスケジューリングを行うため、スワップが有効になっているとパフォーマンスの低下や OOM 対応の不整合を引き起こす可能性があります。
Control-Plane(kube-apiserver, kube-scheduler, kube-controller-manager, etcd)は Data-Plane(kubelet)のリアルタイム性やリソースの予測可能性を前提に Pod をスケジュールします。 kubelet はホストシステムと Pod が要求するリソースを評価する必要がありますが、スワップが有効になっていると、現在の状態を正確に把握することが困難になります。
そのため、以下のコマンドでスワップを無効化しておきます。
# スワップの確認(サイズ 512MB)
$ swapon --show
NAME TYPE SIZE USED PRIO
/var/swap file 512M 0B -2
### スワップを無効化
$ sudo swapoff -a
### 無効化を確認
$ cat /proc/swaps
Filename Type Size Used Priority
### dphys-swapfile サービスを停止
$ sudo systemctl stop dphys-swapfile
$ sudo systemctl disable dphys-swapfile
$ systemctl status dphys-swapfile
○ dphys-swapfile.service - dphys-swapfile - set up, mount/unmount, and delete a swap file
Loaded: loaded (/lib/systemd/system/dphys-swapfile.service; disabled; preset: enabled)
Active: inactive (dead)
Docs: man:dphys-swapfile(8)
Jan 19 01:02:15 master systemd[1]: Starting dphys-swapfile.service - dphys-swapfile - set up, mount/unmount, and delete a swap file...
Jan 19 01:02:16 master dphys-swapfile[473]: want /var/swap=512MByte, checking existing: keeping it
Jan 19 01:02:16 master systemd[1]: Finished dphys-swapfile.service - dphys-swapfile - set up, mount/unmount, and delete a swap file.
Jan 21 22:46:01 master systemd[1]: Stopping dphys-swapfile.service - dphys-swapfile - set up, mount/unmount, and delete a swap file...
Jan 21 22:46:01 master systemd[1]: dphys-swapfile.service: Deactivated successfully.
Jan 21 22:46:01 master systemd[1]: Stopped dphys-swapfile.service - dphys-swapfile - set up, mount/unmount, and delete a swap file.
### 再起動
$ sudo reboot
### スワップが利用されていないことを確認
$ top
top - 23:22:45 up 35 min, 3 users, load average: 0.04, 0.04, 0.05
Tasks: 210 total, 2 running, 208 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.1 us, 0.2 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7809.9 total, 6556.3 free, 511.1 used, 891.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 7298.8 avail Mem ## スワップを使用していないことが分かる
カーネルパラメータの変更
Linux カーネルの overlay モジュールと br_netfilter モジュールを有効化します。参考
- overlay
overlay は、OverlayFS(Overlay Filesystem)を提供するカーネルモジュールです。 Kubernetes では、コンテナランタイム(containerd)がコンテナイメージを効率的に管理するために利用されます。 特に、レイヤ構造で管理されるコンテナイメージのファイルシステムを実現するために必要となります。
- br_netfilter
br_netfilter は、ネットワークブリッジを介してパケットをフィルタリングするためのカーネルモジュールです。 Kubernetes では、Pod 間通信やネットワークポリシの実装において適切にパケットをルーティングまたはフィルタリングするために利用されます。
### パラメータの永続化
$ sudo tee /etc/modules-load.d/containerd.conf <<EOF
overlay
br_netfilter
EOF
### overlay モジュール 有効化
$ sudo modprobe overlay
### br_netfilter モジュール 有効化
$ sudo modprobe br_netfilter
### 確認
$ lsmod | awk 'NR==1 || $1=="overlay" || $1=="br_netfilter"'
Module Size Used by
br_netfilter 32768 0
overlay 143360 14
次に、ブリッジインターフェースを通過する IP トラフィックを iptables で処理できるように設定します。 クラスタネットワークでは、常にブリッジインターフェースを経由して通信するため、トラフィックが iptables に渡らなければ、ネットワークポリシやルーティングの適用、Service のロードバランシングが正しく動作しません。
また、カーネルのトラフィックルーティングを許可することで、ノード間または Pod 間でパケットを転送することができます。 例えば、あるノード内の Pod から他のノード内の Pod への通信や、ノードの外部ネットワークへのルーティングが利用されます。 この設定が無効(0)となっている場合、カーネルは受け取ったパケットを転送しないため、通信が失敗します。
### IP 転送を有効化
$ sudo tee /etc/sysctl.d/kubernetes.conf<<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
### 適用
$ sudo sysctl --system
### 確認
$ sudo sysctl -a | grep -e 'net.bridge.bridge-nf-call-ip' -e 'net\.ipv4\.ip_forward\s*='
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
※ 公式ドキュメント に沿って設定していますが、今回 IPv6 は使用しません。
Cgroup の変更
Linux では Cgroup(Control Groups) と呼ばれるカーネルの機能によってプロセスに割り当てられるリソースを制限・管理しています。
Kubernetes では、Pod の CPU やメモリの Request / Limit によるリソース管理を強制します。 kubelet と CRI(containerd)は cgroup をインターフェースとして接続することで、ワークロードへのリソース割り当てを Kubernetes で制御できるようになります。
次のコマンドで containerd の cgroup ドライバを systemd に変更することで、Kubernetes と CRI の互換性を確保します。 Kubernetes はネイティブに systemd を使用するため、cgroup ドライバを統一しておくことでプロセスやリソース管理の一貫性を保ちます。
### config.toml の修正
$ sudo mv /etc/containerd/config.toml /etc/containerd/config.toml.bak
$ sudo containerd config default | sudo tee /etc/containerd/config.toml > /dev/null
$ sudo vim /etc/containerd/config.toml
~~ 省略 ~~
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
BinaryName = ""
CriuImagePath = ""
CriuPath = ""
CriuWorkPath = ""
IoGid = 0
IoUid = 0
NoNewKeyring = false
NoPivotRoot = false
Root = ""
ShimCgroup = ""
SystemdCgroup = true # true にする
~~ 省略 ~~
### 反映
$ sudo systemctl restart containerd
### 確認
$ containerd config dump | grep SystemdCgroup
SystemdCgroup = true
次に cgroup の設定を永続化します。 Kubernetes v1.25 以降および Linux Kernel v5.8 以降(Debian12)では、cgroup v2 を利用することができます。参考
### カーネルバージョンの確認
$ uname -r
6.6.62+rpt-rpi-v8 # Linux Kernel v6.6.62
詳細は省きますが、cgroup v2 は Linux API の次世代バージョンで、従来の cgroup と比べてリソース管理機能を強化した統合制御システムが提供されています。
cgroup v2 は、cgroup v1(従来)に比べて次のような改善が施されています。
- よりシンプルな設計(個別の Cgroup 階層ではなく 1 つの統一階層に基づく)
- マルチリソースの制限や制御を組み合わせた強力な機能
- 従来の cgroup v1 よりも高いパフォーマンスと柔軟性
一部の Kubernetes では、リソース管理と分離を強化するために cgroup v2 のみを使用します。 例えば、メモリ QoS を改善するための Memory QoS 機能は cgroup v2 でのみサポートされています。
### cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory を追加
$ sudo vim /boot/firmware/cmdline.txt
console=serial0,115200 console=tty1 root=PARTUUID=35fb8665-02 rootfstype=ext4 fsck.repair=yes rootwait quiet splash plymouth.ignore-serial-consoles cfg80211.ieee80211_regdom=JP cgroup_enable=cpuset cgroup_memory=1 cgroup_enable=memory
### 再起動
$ sudo reboot
### 確認
$ cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 0 110 1 ## 有効化済み
cpu 0 110 1 ## 有効化済み
cpuacct 0 110 1 ## 有効化済み
blkio 0 110 1 ## 有効化済み
memory 0 110 1 ## 有効化済み
devices 0 110 1 ## 有効化済み
freezer 0 110 1 ## 有効化済み
net_cls 0 110 1 ## 有効化済み
perf_event 0 110 1 ## 有効化済み
net_prio 0 110 1 ## 有効化済み
pids 0 110 1 ## 有効化済み
$ stat -fc %T /sys/fs/cgroup/
cgroup2fs ## cgroup v2 が有効
この作業を 4 台分行います。
2. Kubernetes の初期設定
RaspberryPi に Kubernetes がインストールできたら kubeadm でクラスタを構築していきます。
kubeadm は Kubernetes クラスタを作成する方法として kubeadm init と kubeadm join というコマンドを提供します。 Control-Plane(master)を init して、Data-Plane(node01, node02, node03)を join させます。
Control-Plane のデプロイ
### マイナーバージョンを指定
$ export KUBERNETES_VERSION=1.31.5
### Control-Plane のアドレスを指定(今回 192.168.68.200)
$ export API_SERVER_ADDRESS=192.168.68.200
### Control-Plane のデプロイ
$ sudo kubeadm init --kubernetes-version $KUBERNETES_VERSION --apiserver-advertise-address $API_SERVER_ADDRESS --apiserver-bind-port 6443 --pod-network-cidr 10.16.0.0/12 --service-cidr 10.1.0.0/20
[init] Using Kubernetes version: v1.31.5
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: hugetlb
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action beforehand using 'kubeadm config images pull'
W0122 01:18:54.199755 2334 checks.go:846] detected that the sandbox image "registry.k8s.io/pause:3.8" of the container runtime is inconsistent with that used by kubeadm.It is recommended to use "registry.k8s.io/pause:3.10" as the CRI sandbox image.
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local master] and IPs [10.1.0.1 192.168.68.200]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost master] and IPs [192.168.68.200 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost master] and IPs [192.168.68.200 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "super-admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests"
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 2.502437958s
[api-check] Waiting for a healthy API server. This can take up to 4m0s
[api-check] The API server is healthy after 13.503139187s
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node master as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: hm95tq.q29pn4nsh0i0bjvw
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.68.200:6443 --token hm95tq.q29pn4nsh0i0bjvw \
--discovery-token-ca-cert-hash sha256:fc2a30b8021ccf6196ff52607464f9df9d2eacc1345e959bba68ee8f15c38f7d
kubeadm init では主に次のプロセスを実行します。
- init 前のチェック(Preflight checks)
- kubelet 起動
- 各種証明書の作成
- Control-Plane 用の構成ファイルを作成(kubeconfig, manifest)
- etcd 用の構成ファイル作成(manifest)
- Control-Plane の起動を待機
- kubeadm, kubelet のコンフィグをアップロード
- Control-Plane をラベリング
- TLS Bootstrap
- Addon のインストール(CoreDNS, kube-proxy)
Control-Plane の構築が終わると、次のステップの実行コマンドが提示されるので順次実行します。
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ sudo chmod 666 /etc/kubernetes/admin.conf
Control-Plane のワークロードは以下のコマンドで確認できます。
$ sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID POD
d81851999b053 571bb7ded0ff9 51 seconds ago Running kube-proxy 0 85705a30fbc0b kube-proxy-hdtww
bf6e536d46f0e 27e3830e14027 About a minute ago Running etcd 24 4bb68be1a82a1 etcd-master
fffe83b8acb51 c33b6b5a9aa53 About a minute ago Running kube-apiserver 24 c8e8e1477a9b7 kube-apiserver-master
3e466d083423c 066a1dc527aec About a minute ago Running kube-scheduler 57 3012e8d142a93 kube-scheduler-master
665e6990f8443 678a3aee724f5 About a minute ago Running kube-controller-manager 57 dcb815ce2b21b kube-controller-manager-master
※ コマンドが失敗する、もしくはコンテナが起動しないといった場合、前述の設定が正しくない可能性があります。
次に、こちら のマニフェストで flannel をデプロイして CNI を追加します。
$ cd ./k8s/manifests/platform/flannel/playground
$ kustomize build . --enable-helm | kubectl apply -f -
namespace/kube-flannel created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds created
今回は Kustomize + Helm を用いますが、直接 マニフェスト を適用することも可能です。
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
これにより、Data-Plane が Control-Plane と疎通できるようになります。
### クラスタステータスの確認
$ kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready control-plane 2m22s v1.31.5
ノードの状態を確認して、master のステータスが Ready となっていればデプロイ完了です。
Data-Plane のデプロイ
次にクラスタに Data-Plane を追加していきます。
先ほど、kubeadm init した際に join コマンドが提示されていますが、以下のコマンドでも確認できます。
### Control-Plane: トークンを再発行(有効期限が切れている場合)
$ sudo kubeadm token create --print-join-command
> ログインコマンドが表示されるので控える
ノードをクラスタに追加します。
$ sudo kubeadm join 192.168.68.200:6443 --token stx9j1.p7qv2easgewi2b7v --discovery-token-ca-cert-hash sha256:fc2a30b8021ccf6196ff52607464f9df9d2eacc1345e959bba68ee8f15c38f7d
[preflight] Running pre-flight checks
[WARNING SystemVerification]: missing optional cgroups: hugetlb
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-check] Waiting for a healthy kubelet at http://127.0.0.1:10248/healthz. This can take up to 4m0s
[kubelet-check] The kubelet is healthy after 2.508023669s
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
node01, node02, node03 で実行した後、再度クラスタのステータスを確認します。
### 全ノードが登録されたことを確認
$ kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
master Ready control-plane 13m v1.31.5 192.168.68.200 <none> Debian GNU/Linux 12 (bookworm) 6.6.62+rpt-rpi-v8 containerd://1.7.25
node01 Ready <none> 71s v1.31.5 192.168.68.201 <none> Debian GNU/Linux 12 (bookworm) 6.6.62+rpt-rpi-v8 containerd://1.7.25
node02 Ready <none> 68s v1.31.5 192.168.68.202 <none> Debian GNU/Linux 12 (bookworm) 6.6.62+rpt-rpi-v8 containerd://1.7.25
node03 Ready <none> 68s v1.31.5 192.168.68.203 <none> Debian GNU/Linux 12 (bookworm) 6.6.62+rpt-rpi-v8 containerd://1.7.25
### Namespace の確認
$ kubectl get namespaces -o wide
NAME STATUS AGE
default Active 14m
kube-flannel Active 12m
kube-node-lease Active 14m
kube-public Active 14m
kube-system Active 14m
全てのコンポーネントのステータスが Ready となっていればクラスタの構築は完了です。
クラスタ情報の更新
デフォルトだと kubernetes-admin@kubernetes というクラスタ名が付与されているため、kubeadm-orenge-cloud-playground としておきます。
### クラスタ名を変更
$ kubectl config rename-context kubernetes-admin@kubernetes kubeadm-orenge-cloud-playground
### 確認
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* kubeadm-orenge-cloud-playground kubernetes kubernetes-admin
別のマシンから接続
構築したクラスタに別の PC から接続する方法について紹介します。
基本的に Control-Plane に API リクエストを送信することでクラスタに対してマニフェストを適用します。 その際に認証情報を用いますが、この情報を別の PC に渡しておくことで、master(RaspberryPi)以外の別のホストからクラスタを制御できます。
認証情報は以下のコマンドで確認できます。
### master の認証情報を確認
$ cat ~/.kube/config
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: XXXXXXXXXXX
server: https://192.168.68.200:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubeadm-orenge-cloud-playground
current-context: kubeadm-orenge-cloud-playground
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: XXXXXXXXXXX
client-key-data: XXXXXXXXXXX
構成情報を管理用 PC(macOS)に登録します。
macOS の場合は ~/.kube/config です。


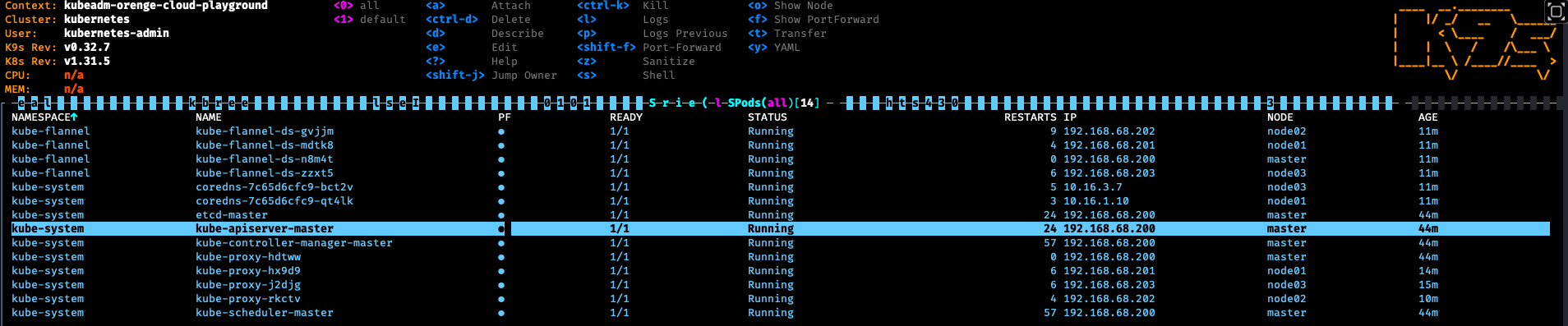
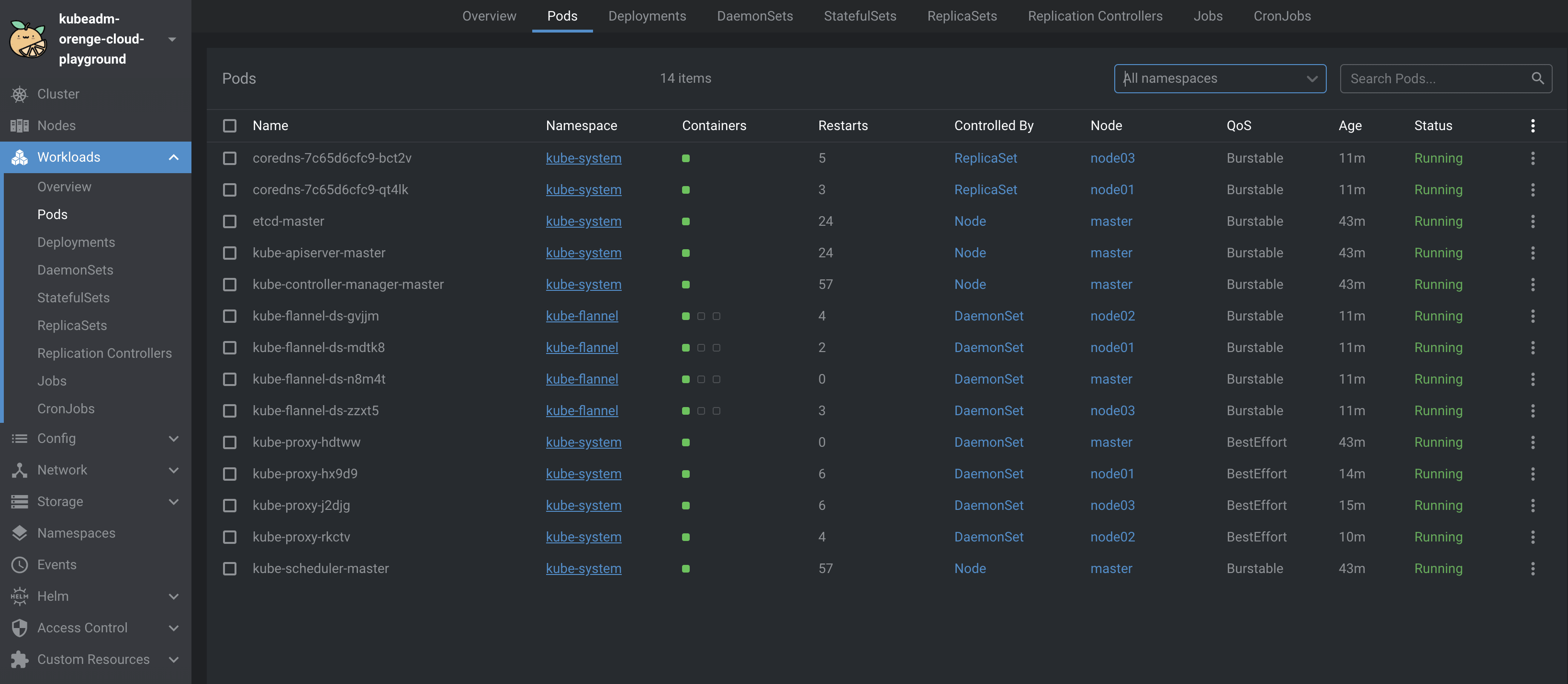
接続できたら Kubernetes クラスタの構築は完了です。
※ 注意
認証情報を不用意に第三者に渡してしまうと、クラスタとネットワーク疎通が取れる限り自由にアクセスできてしまいます。 RBAC で制御する等、セキュリティ面には注意してください。
Tips:トラブルシューティング
### 設定項目を全てリセット
$ sudo kubeadm reset
### Listen ポートの確認
$ sudo lsof -i -P
### Listen ポートを指定してプロセスを kill
$ sudo kill -9 $(sudo lsof -t -i :[ポート番号])
### ログ出力
$ journalctl -xeu kubelet
$ journalctl -xe | grep kubelet
### CRI ステータスの確認
$ sudo crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a
$ crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs [CONTAINER_ID]
今回は直接 kubeadm コマンドを叩きましたが、詳細な設定項目を記述したマニフェストを用意して kubeadm init することもできます。
$ kubeadm init --config /path/to/kubeadm-config.yaml
構成情報は Control-Plane(master)の /var/lib/kubelet/config.yaml に格納されます。
- Reconfiguring a kubeadm cluster: Persisting kubelet reconfiguration
- Reconfiguring a kubeadm cluster: Configuring the kubelet cgroup driver
3. アプリケーションのデプロイ
デプロイと公開
クラスタの構築が完了したので、実際にアプリケーションをデプロイしてみます。 今回は手取り早くデプロイできる Nginx を追加してみます。
### nginx.yaml ###
apiVersion: v1
kind: Namespace
metadata:
name: nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: nginx
spec:
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:latest
imagePullPolicy: Always
ports:
- containerPort: 80
resources:
limits:
memory: '512Mi'
cpu: '0.2'
requests:
memory: '256Mi'
cpu: '0.1'
---
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: nginx
spec:
type: ClusterIP ## ClusterIP で公開
selector:
app: nginx-pod
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
上記マニフェストを適用します。
### デプロイ
$ kubectl apply -f ./nginx.yaml
### 確認
$ kubectl get pod -n nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-649fcbf54f-sgc27 1/1 Running 2 (6d6h ago) 10d 10.16.2.50 node02 <none> <none>
$ kubectl get svc -n nginx -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
nginx-svc ClusterIP 10.1.6.20 <none> 80:32749/TCP 10d app=nginx-pod
ポートフォワードで接続してみます。
### Nginx Pod にポートフォワード
$ kubectl port-forward -n nginx svc/nginx-svc 8080:80
localhost:8080 にアクセスして Nginx の Welcome ページが表示されたらデプロイ完了です。
$ curl -I localhost:8080
HTTP/1.1 200 OK
Server: nginx/1.27.3
Date: Wed, 22 Jan 2025 06:31:34 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 26 Nov 2024 15:55:00 GMT
Connection: keep-alive
ETag: "6745ef54-267"
Accept-Ranges: bytes
MetalLB の追加
実際にアプリケーションを運用する際は、ポートフォワードでアクセスすることはありません。 そこで、MetalLB を追加し、L4LB でサービスを公開することで、ローカルネットワークアドレス(Private IP)で接続することにします。
こちら のマニフェストを適用して MetalLB をデプロイします。
$ cd ./k8s/manifests/platform/metallb/playground
$ kustomize build . --enable-helm | kubectl apply -f -
namespace/metallb created
customresourcedefinition.apiextensions.k8s.io/bfdprofiles.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bgpadvertisements.metallb.io created
customresourcedefinition.apiextensions.k8s.io/bgppeers.metallb.io created
customresourcedefinition.apiextensions.k8s.io/communities.metallb.io created
customresourcedefinition.apiextensions.k8s.io/ipaddresspools.metallb.io created
customresourcedefinition.apiextensions.k8s.io/l2advertisements.metallb.io created
customresourcedefinition.apiextensions.k8s.io/servicel2statuses.metallb.io created
serviceaccount/metallb-controller created
serviceaccount/metallb-speaker created
role.rbac.authorization.k8s.io/metallb-config-watcher created
role.rbac.authorization.k8s.io/metallb-controller created
role.rbac.authorization.k8s.io/metallb-pod-lister created
clusterrole.rbac.authorization.k8s.io/metallb-speaker created
clusterrole.rbac.authorization.k8s.io/metallb:controller created
rolebinding.rbac.authorization.k8s.io/metallb-config-watcher created
rolebinding.rbac.authorization.k8s.io/metallb-controller created
rolebinding.rbac.authorization.k8s.io/metallb-pod-lister created
clusterrolebinding.rbac.authorization.k8s.io/metallb-speaker created
clusterrolebinding.rbac.authorization.k8s.io/metallb:controller created
configmap/metallb-config created
secret/metallb-memberlist created
secret/metallb-webhook-cert created
service/metallb-webhook-service created
deployment.apps/metallb-controller created
poddisruptionbudget.policy/metallb-controller created
daemonset.apps/metallb-speaker created
ipaddresspool.metallb.io/network-pool-for-system created
l2advertisement.metallb.io/network-pool-for-system created
networkpolicy.networking.k8s.io/metallb-controller created
networkpolicy.networking.k8s.io/metallb-speaker created
validatingwebhookconfiguration.admissionregistration.k8s.io/metallb-webhook-configuration created
MetalLB がデプロイできたら、先ほどの Nginx マニフェストのサービスを以下のように変更します。 ポイントは type を LoadBalancer にしているところです。 loadBalancerIP を指定することで、クラスタが接続しているルータから DHCP でアドレスを払い出します。
IPAddressPool カスタムリソースで 192.168.68.230 - 192.168.68.250 を静的 IP として押さえています。
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: network-pool-for-system
namespace: metallb
spec:
addresses:
- 192.168.68.230-192.168.68.250
autoAssign: true
avoidBuggyIPs: false
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: network-pool-for-system
namespace: metallb
spec:
ipAddressPools:
- network-pool-for-system
この IP レンジの中から割り当てるアドレスを選択します。
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: nginx
spec:
type: LoadBalancer ## LoadBalancer で公開
loadBalancerIP: 192.168.68.230 ## Private IP を付与
selector:
app: nginx-pod
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
再度マニフェストを適用します。
$ kubectl apply -f ./nginx.yaml
デプロイしたら、今度は LAN IP で接続できることを確認します。
192.168.68.0/24 ネットワーク内の他の PC から接続してみます。
$ curl -I http://192.168.68.230
HTTP/1.1 200 OK
Server: nginx/1.27.3
Date: Wed, 22 Jan 2025 06:30:20 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 26 Nov 2024 15:55:00 GMT
Connection: keep-alive
ETag: "6745ef54-267"
Accept-Ranges: bytes
Nginx が 200 番を返していれば MetalLB でサービスを公開することができています。
実際に WEB ブラウザからもアクセスできます。

4. 【番外編】MetalLB の仕組み
今回使用した MetalLB の仕組みについて覗いてみたいと思います。
ベアメタル環境のロードバランサ
EKS / GKE 等のマネージド Kubernetes で type: LoadBalancer を使った場合は自動的に IP アドレスが払い出されますが、MetalLB の場合はあらかじめユーザが指定した IP アドレスプール(192.168.68.230 - 192.168.68.250)からの払い出しになります。 そのため、MetalLB を利用したネットワークは、DHCP 等による LAN の IP 払い出しが利用シーンとして想定されており、クラウドのロードバランサのようにグローバル IP が割り当てられることはありません。 外部と接続させたい場合は MetalLB で払い出したプライベート IP アドレスを NAPT する仕組みを別で準備する必要があります。
MetalLB のアーキテクチャ
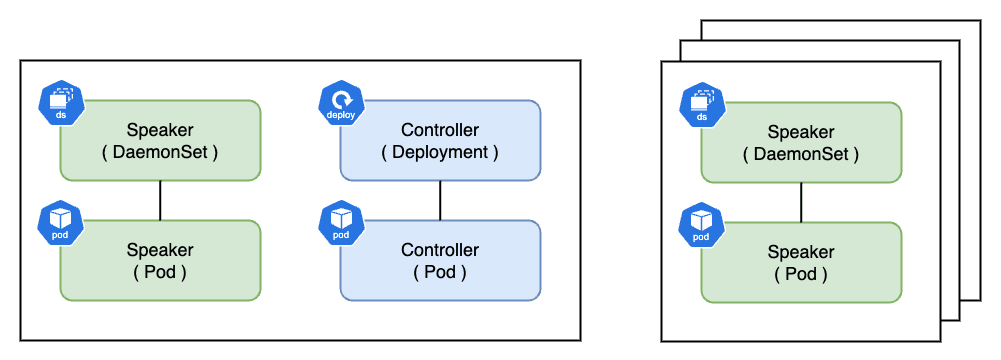
MetalLB をデプロイすると、Speaker と Controller と呼ばれる Pod がノード(Data-Plane)で起動します。
$ kubectl get pod -n metallb -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
metallb-controller-59d9df8d77-n2l95 1/1 Running 2 (6d7h ago) 10d 10.16.3.60 node03 <none> <none>
metallb-speaker-6vh5n 1/1 Running 4 (6d7h ago) 10d 192.168.68.203 node03 <none> <none>
metallb-speaker-q9czb 1/1 Running 4 (6d7h ago) 10d 192.168.68.202 node02 <none> <none>
metallb-speaker-r488z 1/1 Running 3 (6d7h ago) 10d 192.168.68.201 node01 <none> <none>
Speaker は DaemonSet で管理されており、すべてのノードで最低 1 Pod 起動し、ノードの IP アドレスを持ちます。 通常、Pod に割り当てられる Cluster IP はクラスタ内でのみ有効であり、クラスタ外のリソースから認識することができません。
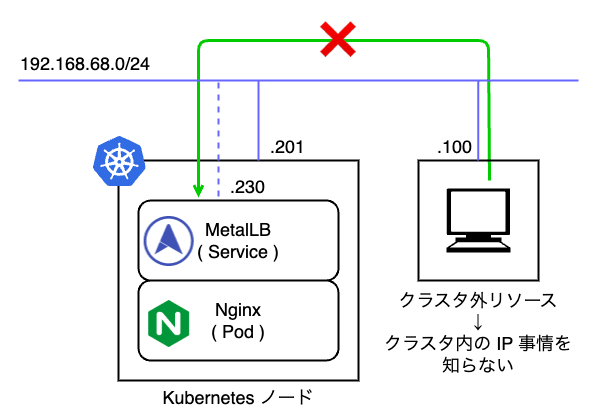
そこで、MetalLB Speaker は ARP(Address Resolution Protocol)、NDP(Neighbor Discovery Protocol)BGP(Border Gateway Protocol)のいずれかを使用してサービスの通信到達性を担保します。
- ARP:IPv4 向け L2 プロトコル
- NDP:IPv6 向け L2 プロトコル(NDP の実態は ICMPv6 なので実際は L3 プロトコルに該当)
- BGP:AS(Autonomous System)間通信向け L3 プロトコル
- より大規模な負荷分散を実現する上で BGP ルータとクラスタ間で経路広報やピアリングを行う際に利用
MetalLB ではこれらのプロトコルを利用して L2 モードと BGP モードの 2 種類の設定が可能です。 今回は IPv4 を使用しているので L2 モード、ARP によってパケットの到達性を保証しています。
一方の Controller は Deployment で管理されており、MetalLB で利用する IP アドレスの管理や払い出しを Kubernetes クラスタを跨って行う制御機能を持ちます。 Controller は Data-Plane のいずれかのノードで 1 Pod 起動し、Cluster IP が割り当てられます。
MetalLB L2 モード
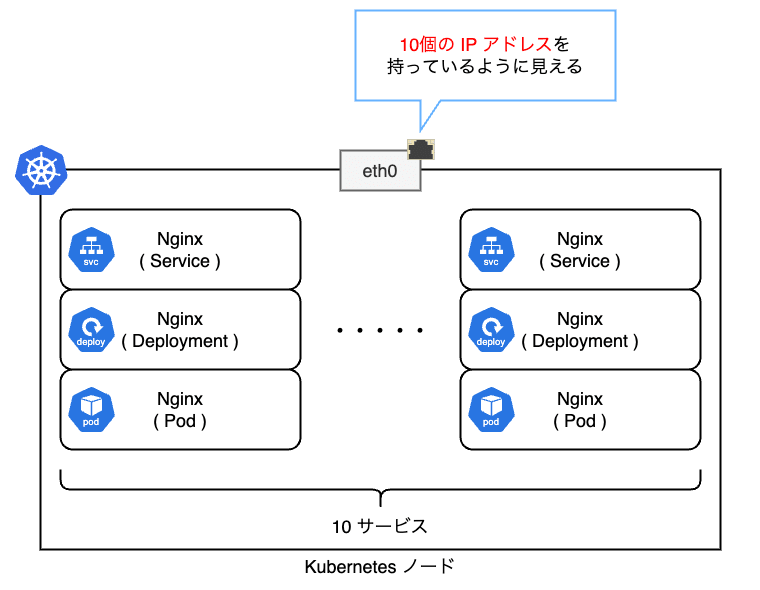
L2 モードの場合は各ノードがサービスを提供する責任を持ちます。 ネットワーク的な観点では以下の図のようにサービスの数だけ NIC に IP アドレスが紐付いているように見えます。 ただし、実際には IP アドレスは UP していないため、ifconfig 等のコマンドを叩いても確認できません。
ARP の場合は接続元からの ARP リクエストに対して、接続先ノードの MetalLB Speaker が 192.168.68.201 はノードの MAC アドレスであることを ARP リプライで応答します。
つまり、サービスに割り当てた IP アドレスは、あるノードの MAC アドレスに解決されることになります。 その結果、L2 モードでは払い出された IP に対する全ての通信は 1 台のノードに集約されます。 その後、Data-Plane の kube-proxy によって設定された iptables のルールに従ってトラフィックが各 Pod に分散される仕組みとなっています。
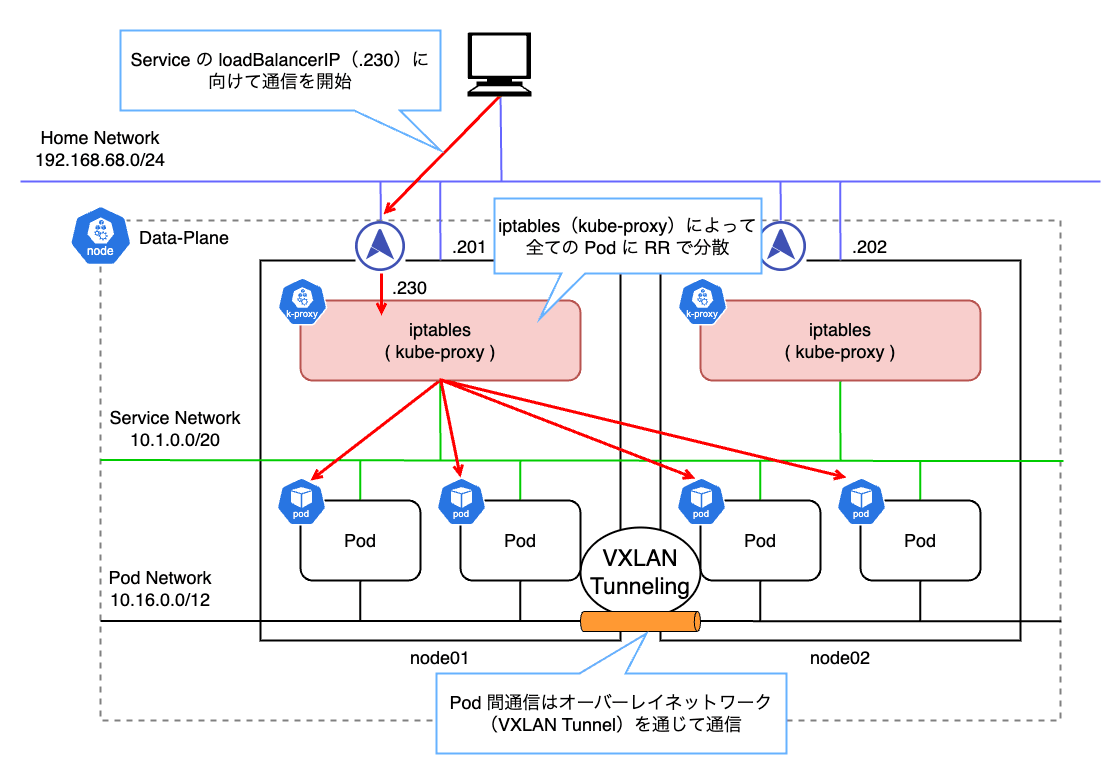
今回の例で確認してみます。 192.168.68.230 を割り当てた Nginx にアクセスした後、ARP テーブルを確認します。
$ arp -na | grep 192.168.68.230
? (192.168.68.230) at dc:a6:32:bf:8b:77 on en0 ifscope [ethernet]
192.168.68.230 という IP アドレスに dc:a6:32:bf:8b:77 という MAC アドレスがマッピングされていることが分かります。 つまり、LAN 内ではこの MAC アドレスに向けて L2 通信をしているということです。
ここで、node01(RaspberryPi)の eth0 I/F の MAC アドレスを確認します。
$ ip a | awk '/^[0-9]+: eth0:/ {flag=1} /^[0-9]+: / && !/eth0:/ {flag=0} flag'
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether dc:a6:32:bf:8b:77 brd ff:ff:ff:ff:ff:ff
inet 192.168.68.201/24 brd 192.168.68.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
すると、dc:a6:32:bf:8b:77 が eth0 I/F の MAC アドレスであることが分かります。 つまり、L2 モードでは、例え Pod が複数のノードに分散していたとしても、全てのリクエストは一旦単一のノードに集約されることになります。
L2 モードではロードバランサと言いつつも、実際はサービスの IP を持ったノードがダウンした場合に、別のノードに振り分けるフェールオーバに近い形で冗長化しています。
パフォーマンスの点で注意すべきは、実際のロードバランサは特定のノード内で kube-proxy(iptables)によって行われるということです。 iptables は Chain Rule が増えると性能が著しく劣化します。 これは iptables がすべてのルールを順番に評価しようとするためです。 つまり、ルール数が n 個の時、計算量は となります。
回避策としては、IPVS(IP Virtual Server) と呼ばれる別のエンジンを利用することです。 こちらはルールが増加した場合でも計算量は となります。参考
しかし、IPVS においてもまだまだ不具合があるようなので、Production で利用するのはあまりお勧めできません。
MetalLB might work with IPVS mode in kube-proxy, in Kubernetes 1.13 or later. However, it is not explicitly tested yet, so it’s at your own risk. See our tracking bug for details.
L2 モードでの Speaker は払い出された IP をハンドリングするリーダーが用意されます。 以下の図では合計で 3 つの IP が 2 つのノードに払い出されており、各ノードの Speaker がそれぞれのリーダーとなっています。
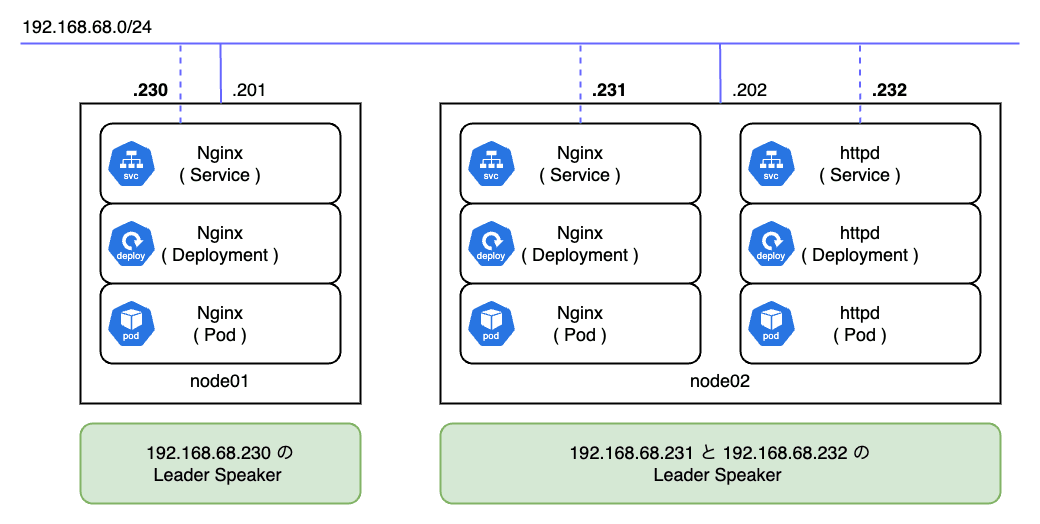
今回は Nginx Pod のレプリカ数が 1 で、node02 に配置されていることが分かります。
$ kubectl get pod -n nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-649fcbf54f-sgc27 1/1 Running 2 (6d10h ago) 10d 10.16.2.50 node02 <none> <none>
つまり、リーダーノードは Pod の配置状況を考慮して選出されるわけではありません。
MetalLB は各ノードのキャパシティ、優先度、および現在の負荷状況を常に監視し、サービスの IP をどのノードがアクティブに保持するかを決定します。 リーダーノードのエレクション責務は MetalLB の Controller Pod が担っています。
L2 モードのフェールオーバ
L2 モードでは何らかの理由でリーダーノード(対象の IP が存在するノード)がダウンした場合に自動でフェールオーバが行われます。 割り当てられた IP アドレスの解放は 10 秒程度 掛かり、その後別のノードがリーダーとなります。
ただし、ノードのダウンは Kubernetes 自体が検知するため、node-monitor-grace-period で設定された時間(デフォルトでは 40 秒)が確定で掛かります。 さらに到達不能になったノード上で稼働している Pod のタイムアウトはデフォルトで 5 分程度です。 結果、フェールオーバによるノードの切り替えは 5 分超 掛かる ため可用性の観点で注意が必要です。
MetalLB はフェールオーバ時に GARP(Gratuitous ARP) によって通信元に IP アドレスと MAC アドレスの紐付けが変更されたことを通知します。 ほとんどのシステムでは GARP を正しく扱うことができるため、キャッシュを更新することでフェールオーバは数秒で終わります。
一方で、従来機器の中にはキャッシュの更新が遅れるバグのあるシステムも存在するようです。 近年の Linux / macOS / Windows では支障ありませんが、一部の古い OS では問題になることがあります。
まとめ

今回のブログでは、RaspberryPi に Kuberetes をインストールしてクラスタを構築する方法について紹介しました。 また、構築したクラスタに Nginx を導入し、MetalLB で LAN IP を払い出してサービスを公開してみました。
Kubernetes の構築に際してはカーネルパラメータを適切に設定する必要があり、Linux に関する基本的な知識が必要となります。 kubeadm init を実行した際に、Control-Plane の構築に失敗する場合は、前提の設定が正しくない可能性があります。 特に cgroup v2 を利用する場合は、従来と大きく異なる点があるので、各種パラメータが適切であるかを確認してください。
また、本記事では MetalLB の仕組みについても紹介しました。 現在では、ベアメタルで Kubernetes をホスティングする際は、L4 のロードバランサとして MetalLB を選定することが多いのではないでしょうか。
MetalLB は L2 モードと BGP モードの 2 つが利用できます。
L2 モードは主に、ARP や NDP 等のアドレス解決プロトコルを利用することで、IP アドレスの問い合わせに対してリーダーノードの MAC アドレスを応答します。 そのため、Pod の負荷を分散できる一方で、単一ノードにトラフィックが集中することによるボトルネックや、iptables(kube-proxy)による Chain Rule の評価やルーティングのオーバーヘッドが少なからず生じます。
また、BGP モードの場合、クラスタと BGP ルータをピアリングして経路広報することで、ノードレベルで負荷分散することができますが、ネットワーク規模が非常に大きくなります。
MetalLB にはまだまだ課題がありますが、ベアメタルで Kubernetes を運用する際には非常に強力なツールとなっています。
次回のブログでは、より本番環境に近い Kubernetes の運用を目指すべく、いくつかエコシステムを整備したいと思います。