k6 で実現する負荷試験のモダナイゼーション
- Authors
- Name
- ごとれん
- X
- @ren510dev


目次
- 目次
- はじめに
- k6
- 主な特徴
- 懸念点
- ユースケース
- サポートしているプロトコル
- 大規模な負荷試験
- 他の負荷試験ツールとの比較
- 検証事例
- 留意すべき点
- ローカル環境でのお手軽負荷試験
- k6 CLI
- Docker Compose で負荷試験スタックを起動
- Docker Compose 上で負荷試験を実行
- k6-operator による実用的な負荷試験
- Kubernetes に導入
- 負荷試験コンポーネントのデプロイ
- データソースの確認
- Kubernetes 上で負荷試験を実行
- まとめ
- 余談

はじめに
Web アプリケーションは、高いパフォーマンスと信頼性が要求されます。 増大するリクエストに耐え得る設計になっているかどうかを開発者が把握しておくことは、スケーラビリティ(規模拡張性)の観点でも非常に重要になってきます。
リリース前や、大規模なイベント・セールの前に行いたい検証の一つに負荷試験があります。 実際にアクセスしてくるユーザ数やリクエスト数、もしくはそれ以上の同接数を想定し、システムが耐えられるかどうか、レスポンスタイムは妥当であるか等、いくつかのシナリオを検証します。 事前の負荷試験によって、ボトルネックや潜在的な問題を洗い出しておくことで、予期せぬサービスダウンを低減できたり、キャパシティプランニング に役立てることができます。
従来、Apache JMeter や Gatling, Locust 等、様々なツールが負荷試験に採用さてきましたが、設定やシナリオの定義が複雑だったり、GUI 経由であることから柔軟さに欠けたりと、いくつか課題があり、近年のマイクロサービスやクラウドネイティブな設計においては、さらにクローズアップされます。
また、一部では大規模な負荷試験を実施する際、Sender 側(負荷を発生させる側)のマシン性能や、負荷試験ツールの特性も気にする必要があり、トラフィックを思うようにシミュレートできない懸念がありました。
このような背景から、昨今では Kubernetes やクラウドネイティブな環境下での負荷試験において、Grafana Labs の k6 が注目されています。 k6 はコンテナフレンドリーな設計となっており、シナリオの定義も非常に容易です。 また、Kubernetes への導入には、オペレータ(k6-operator)を用いることで、大規模な負荷シナリオや分散実行、自動化されたパイプラインとの統合も可能です。
今回のブログでは、モダンな負荷試験ツールである k6 を取り上げ、導入方法や負荷試験環境の構築についてまとめてみたいと思います。
k6

k6 is a modern load-testing tool, built on our years of experience in the performance and testing industries. It's built to be powerful, extensible, and full-featured. The key design goal is to provide the best developer experience.
k6 は、シングルバイナリで動作するためコンテナ化が容易であり、エコシステムも充実したクラウドネイティブな負荷試験ツールです。 k6 は、Grafana Labs ホスティングの下、OSS としてメンテナンスされており、新バージョンは約 2 ヶ月毎にリリースされます。
k6 自体は Go 言語で実装されており、Goroutine による分散実行や並列化機能が取り入れられているため、膨大なリクエストを生成できます。
また、負荷試験用のスクリプト(シナリオ)は、JavaScript ES2015/ES6 で記述することができます。 そのため、JavaScript に慣れている人であれば、基本的な構文が同じなのでキャッチアップコストが低くて済むのも魅力の一つです。
ただし、k6 は Node.js でもなければブラウザでもないため、例えば、os や fs といった npm モジュールは機能しません。 npm module や NodeJS API を使用する場合、別途モジュールを作成して、ファイルからインポートしてやる必要があります。 例えば、Amazon API Gateway へリクエストを投げる場合は、browserify を利用して node_modules にインストールした後、インポートすることで k6 でも実行可能です。
k6 は、内部的に goja をフォークした Sobek を呼び出すことで、ECMAScript 2015+(ES6+)を解析・実行しています。参考
主な特徴
- モニタリングツールとの親和性
k6 は Grafana Labs 傘下のプロダクトということもあり、Kubernetes 関連のモニタリングツールとのエコシステムが充実している印象です。 負荷試験の結果はメトリクスとして Prometheus に送りだすことで、Grafana ダッシュボードで可視化することができます。 他にも、New Relic や Datadog 等、SaaS ツールとの連携も可能です。
また、OpenTelemetry(Otel)を組み合わせてトレーシングを整備しておくことで、アプリケーションやネットワーク周りのボトルネックの改善に役立てることができます。
- シングルバイナリ
先でも述べた通り、k6 は Go 言語で実装されています。 そのため、CLI 実行やコンテナ化が容易であり、シングルバイナリで動かせる点も、クラウドネイティブな負荷試験ツールと言われる所以だと思います。
オーソドックスな例では、シナリオをコピーした k6 イメージを準備し、コンテナレジストリにアップロードすることで、Kubernetes への展開ができます。
- 直感的なスクリプト
k6 は JavaScript で定義したシナリオを元に、負荷試験を実行します。 例えば、以下のようなスクリプトを用いて、段階的な負荷をシミュレートできます。
import http from 'k6/http'
export const options = {
stages: [
{ duration: '30s', target: 20 },
{ duration: '1m30s', target: 10 },
{ duration: '20s', target: 0 },
],
}
export default function () {
http.get('https://test.k6.io')
}
この例では、https://test.k6.io というエンドポイントに GET リクエストを送信します。 30 秒間で 20 VUs に増加し、1 分 30 秒かけて 10 VUs に減少、さらに 20 秒かけて 0 VUs にコンバージョンします。 これだけで簡単な負荷試験は実行できるため、他のツールと比較してもハードルを下げることができるのではないでしょうか。
- CI/CD との親和性
CI/CD パイプラインに統合することで ChatOps ライクな負荷テストを実装することができます。
例えば、run-k6-action では、負荷試験スクリプトを GitHub に Push して Job 用のカスタムリソースを生成し、負荷テストまでを自動化することができます。 CI Workflow に組み込むことで、SRE でなくても容易に負荷試験を実行したり、その結果を報告したりすることができます。
CircleCI Developer Hub - grafana/k6
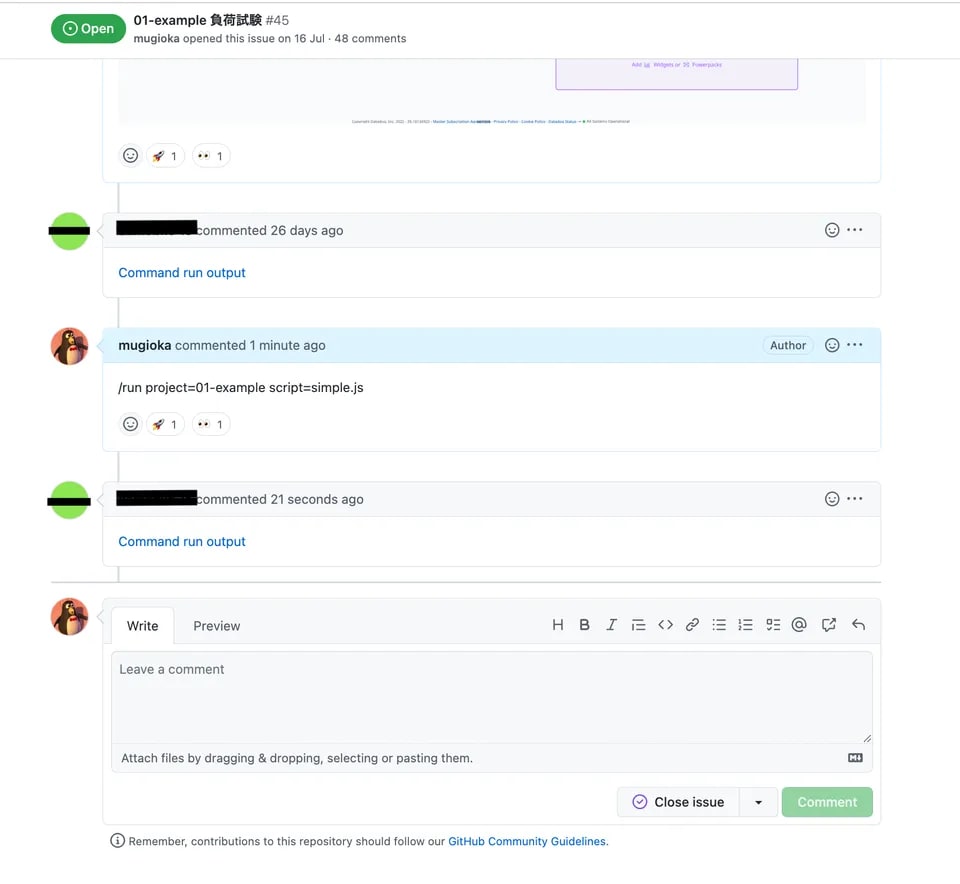
実際に、k6 を ChatOps 化した例が 株式会社 CAM SRE チームより紹介されています。
CAM TechBlog - 負荷試験環境に k6-operator を活用し、ChatOps ライクな負荷試験を実現できた話

【アーキテクチャ】
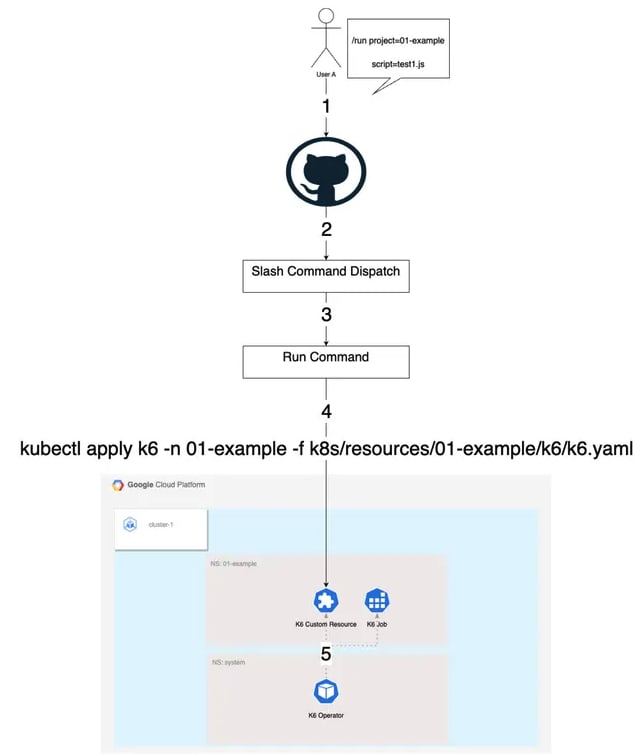
【スラッシュコマンドによる実行】
- Kubernetes オペレータ
k6 には、k6-operator という Kubernetes のオペレータが準備されています。 これにより、TestRun というカスタムリソースからシナリオを定義した ConfigMap を参照して Kubernetes 上で容易に負荷試験を実行することができます。
リリース当初から K6 というカスタムリソースが使用されてきましたが、2023 年 10 月に発表された v0.0.11rc3 では TestRun への移行が推奨されています。
⚠️ Future deprecation
K6 CRD is going to be deprecated in favor of TestRun CRD. The behaviour of both should be identical for now, but it is strongly recommended to switch to TestRun CRD in your workflows as K6 CRD will be removed in the future.

まずシナリオをカスタムリソースとして適用すると、k6-operator のコントローラが変更を検知してクラスタを更新します。 その後、負荷試験用の Job が作成され、Sender Pod をデプロイしてリクエストを生成します。参考
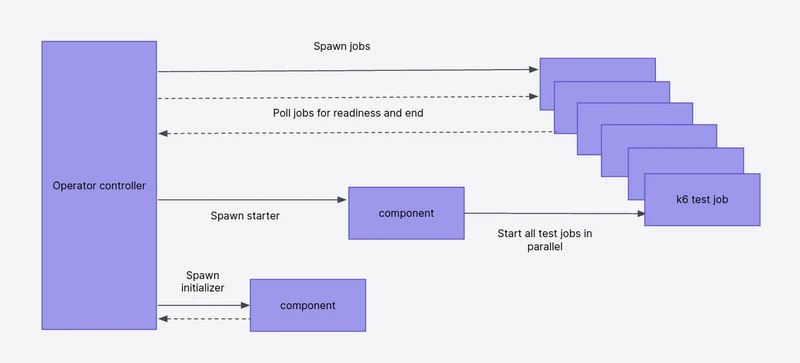
例えば、以下のようなカスタムリソースを用いると、load-test.js というスクリプトを元にシナリオを実行し、結果を Remote-Write で Prometheus へ送信します。
apiVersion: k6.io/v1alpha1
kind: TestRun
metadata:
name: k6-operator-example01
namespace: k6-operator
spec:
parallelism: 1
arguments: -o experimental-prometheus-rw ## Prometheus Remote-Write を使用
script:
configMap:
name: k6-operator-example01
file: load-test.js
runner:
env:
- name: K6_PROMETHEUS_RW_SERVER_URL
value: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090/api/v1/write
Prometheus の他にも InfluxDB や Kafka 等、セルフホスティングデータベースから、New Relic や Datadog 等の SaaS にも流すことができます。
実際に、負荷試験を実行する際は、k6-operator を使用することが殆どだと思います。 シナリオテンプレートを作成しておくことで、負荷試験の基盤を IaC や CaC で管理できるようになります。
懸念点
ここまで k6 のメリットを取り上げてきましたが、導入に際する懸念点も挙げておきます。
- JavaScript だが Node.js ではない
こちらも先で述べていますが、k6 が利用する負荷スクリプトは JavaScript で定義できますが、Node.js ではありません。 npm モジュールのような NodeJS API は利用できないため、ニッチな負荷試験を行う場合は、必要に応じてツールのインストールやコール方法等、対応策を考える必要があります。
- デフォルトでは時系列変化の把握がしずらい
k6 CLI の場合、負荷試験の結果は以下のように出力されます。
$ k6 run load-test.js
/\ Grafana /‾‾/
/\ / \ |\ __ / /
/ \/ \ | |/ / / ‾‾\
/ \ | ( | (‾) |
/ __________ \ |_|\_\ \_____/
execution: local
script: load-test.js
output: -
scenarios: (100.00%) 1 scenario, 20 max VUs, 2m50s max duration (incl. graceful stop):
* default: Up to 20 looping VUs for 2m20s over 3 stages (gracefulRampDown: 30s, gracefulStop: 30s)
data_received..................: 72 MB 512 kB/s
data_sent......................: 632 kB 4.5 kB/s
http_req_blocked...............: avg=4.35ms min=0s med=6µs max=1.13s p(90)=11µs p(95)=14µs
http_req_connecting............: avg=2.02ms min=0s med=0s max=190.94ms p(90)=0s p(95)=0s
http_req_duration..............: avg=287.46ms min=171.78ms med=186.46ms max=2.15s p(90)=382.26ms p(95)=589.08ms
{ expected_response:true }...: avg=287.46ms min=171.78ms med=186.46ms max=2.15s p(90)=382.26ms p(95)=589.08ms
http_req_failed................: 0.00% 0 out of 6194
http_req_receiving.............: avg=12ms min=14µs med=115µs max=1.52s p(90)=313.69µs p(95)=171.54ms
http_req_sending...............: avg=24.04µs min=2µs med=22µs max=1.88ms p(90)=40µs p(95)=45µs
http_req_tls_handshaking.......: avg=2.31ms min=0s med=0s max=948.13ms p(90)=0s p(95)=0s
http_req_waiting...............: avg=275.43ms min=171.56ms med=185.13ms max=2.15s p(90)=377.05ms p(95)=576.24ms
http_reqs......................: 6194 44.230332/s
iteration_duration.............: avg=291.92ms min=171.87ms med=186.96ms max=2.15s p(90)=406.84ms p(95)=593.94ms
iterations.....................: 6194 44.230332/s
vus............................: 1 min=1 max=20
vus_max........................: 20 min=20 max=20
running (2m20.0s), 00/20 VUs, 6194 complete and 0 interrupted iterations
default ✓ [======================================] 00/20 VUs 2m20s
見ての通り最終的な結果のみで、k6 単体では時系列の変化を取得できないため、Grafana や Datadog 等、外部の可視化ツールと連携する必要があります。 その点では、JMeter や Taurus 等と比較してやや面倒かもしれません。
ちょっとした検証を実施したい場合は、k6 の 拡張機能として用意されている xk6-dashboard(xk6) というツールを利用することができます。 xk6 は、負荷試験の結果を時系列で出力してくれるので、ローカルで実行する場合はこちらを利用するのが良いと思います。 ただし、自前でビルドしてあげる必要があるのでちょっと面倒です 😢
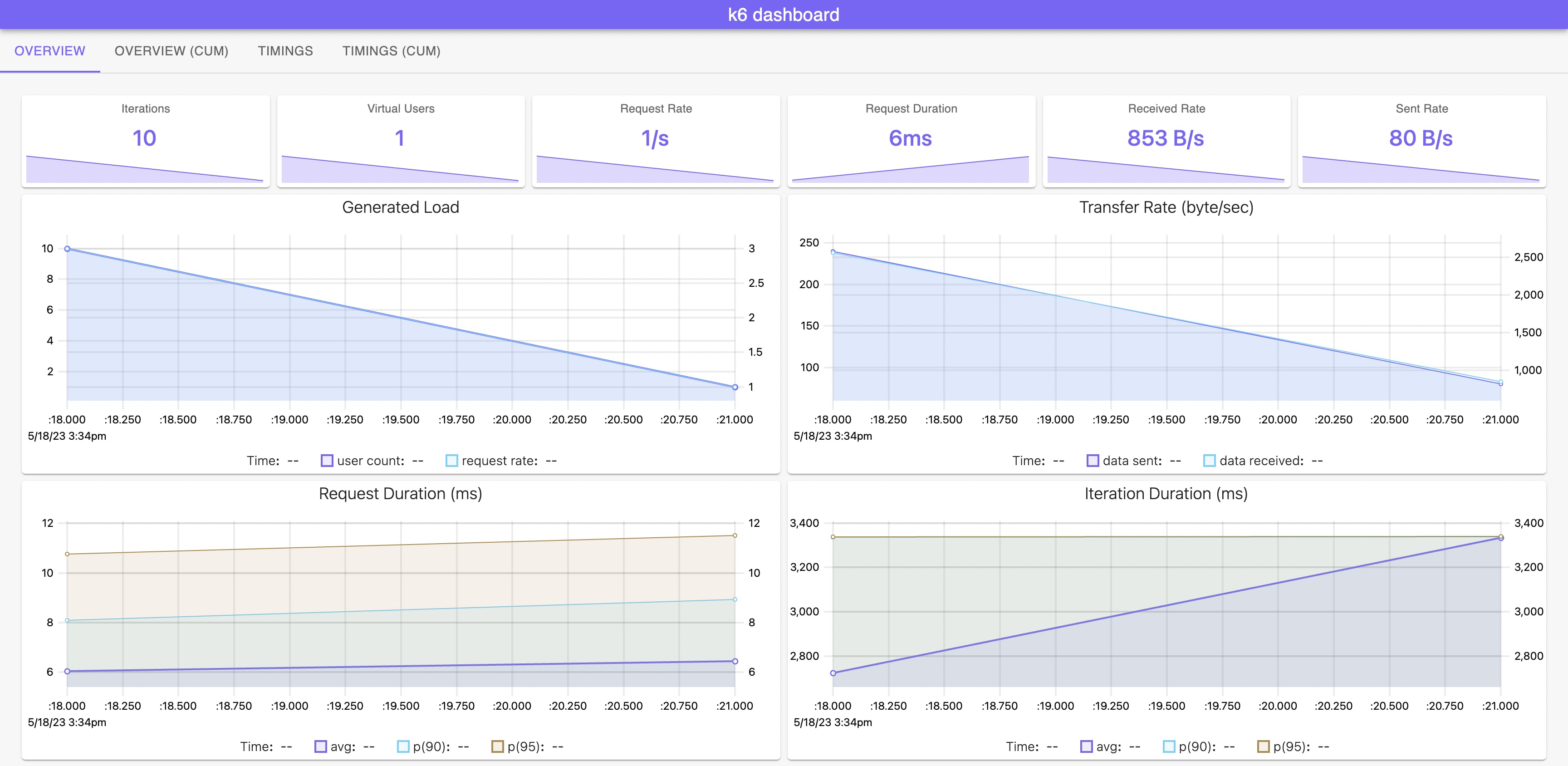
また、単にレポートを取得したい場合は、サードパーティ製の k6-reporter を使用することで HTML ファイルとして保存することもできます。
import http from 'k6/http'
import { htmlReport } from 'https://raw.githubusercontent.com/benc-uk/k6-reporter/main/dist/bundle.js' // k6-reporter を追加
export const options = {
stages: [
{ duration: '30s', target: 20 },
{ duration: '1m30s', target: 10 },
{ duration: '20s', target: 0 },
],
}
export default function () {
http.get('https://test.k6.io')
}
// レポート出力
export function handleSummary(data) {
return {
'summary.html': htmlReport(data),
}
}
多くの場合は、k6-operator を Kubernetes に導入してエコシステムと連携するので、このあたりは運用に際して然程問題にならないと思います。
ユースケース
k6 では以下のような試験を行うことができます。
- 負荷テスト
最も基本的なユースケース。 k6 は、リソース消費を最小限に抑えるように最適化されているため、高負荷テスト(スパイク、ストレス、ソークテスト)を容易に実行することができます。
- ブラウザテスト
インターフェースレベルでアプリケーションのパフォーマンスを検証し、ページ要素が画面にどのように、いつ表示されるかを考慮したラウンドトリップメトリックを測定することができます。
- カオスと回復力のテスト
Injecting faults with xk6-disruptor
カオス試験を行う際には、xk6-disruptor を用いて、k6 にフォールトインジェクション(障害注入)機能を追加することができます。 これにより、遅延やレスポンスエラー等の不安定な状況下でのアプリケーションの信頼性をテストすることが可能となっています。
- パフォーマンスと統合モニタリング
継続的な本番環境監視のために k6 スモークテスト をスケジュールすることにより、k6 を統合監視ツールとして使用できます。
スモークテスト
ソフトウェアの新しいビルドやリリースが基本的に機能することを確認するために行われる一連の簡易テストのこと。
- 基本機能の確認:アプリケーションの主要な機能が正しく動作するか
- 初期品質の確認:開発の初期段階で重大な問題がないか
- ビルドの安定性の確認:新しいビルドがテスト対象として十分に安定しているか
サポートしているプロトコル
2023 年 5 月現在、k6 は以下のプロトコルをサポートしています。
- HTTP/1.1, HTTP/2
- Java, Node.js, PHP, ASP.NET, etc...
- SOAP(Simple Object Access Protocol)
- REST(REpresentational State Transfer)
- WebSocket
- gRPC
大規模な負荷試験
サービスによっては数百万から数千万人規模の同時アクセスを想定した負荷試験を実施しなければならないケースがあります。 実際に負荷試験を実施してみると、アプリケーションの性能を検証する以前に、環境構築が非常に厄介になってきます。 ネットワークミドルウェアに起因した問題であったり、リクエストを生成する Sender 側のマシンの方が先に限界を迎えてしまったりと、思うように負荷試験が進まず、頭を抱える SRE も少なくないと思います。
例えば、Locust は Python で実装されていますが、シングルスレッドで動作するため、リクエストを生成した際にマスタプロセスが落ちてデータ収集に苦戦するケースがありました。
このような大規模な負荷試験の際にも、k6 は Go 言語の特性を活かして対応することができるように工夫されています。
他の負荷試験ツールとの比較
ここでは Locust との比較を例に挙げたいと思います。
Locust は言語特性もありますが、シングルスレッド(1 vCPU)で動作するため、複数の CPU コアを効率的に使用できないという課題があります。 そのため、マルチ CPU サーバ上のすべての CPU を完全に使用するには、負荷生成を複数のプロセスに分散する必要があります。 負荷試験基盤の構築者はマスター・スレーブのような構成を取り、言わばマシンのパワーで押し進めるような状況に追い込まれます。
一方の k6 は、Goroutine を用いて高度にマルチスレッド化されているため、利用可能なすべての CPU コアを効果的に利用して並列実行することができます。
参考までに、Locust は単一インスタンスで実行すると最大でも 900 RPS 程度が限界 とされています。
Locust was run in distributed mode, which means that five Locust instances were started: one master instance and four slave instances (one slave for each CPU core). Locust is single-threaded so can’t use more than one CPU core, which means that you have to distribute load generation over multiple processes to fully use all the CPU on a multi-CPU server. (They should really integrate the master/slave mode into the app itself so it auto-detects when a machine has multiple CPUs and starts multiple processes by default.) If I had run Locust in just one instance it would only have been able to generate ~900 RPS.
これに対し、k6 は 理論上、30,000 ~ 40,000 VUs の同時リクエストを生成することが可能である とされています。
つまり、1 秒あたり 100,000 ~ 300,000 VUs(1 分あたり 600 ~ 1200 万)を超えるリクエストを必要としない限り、単一インスタンスでも十分な負荷試験が実施できるということです。
- 実行時解釈の違い
Python と Go では実行時のコード解釈も異なります。 Python はインタプリタ言語なので実行時の逐次解釈の手続きを踏む必要がありますが、Go 言語はコンパイル型言語なのでそのような処理は不要です。 加えて、Go 言語はシングルバイナリで動作するため、外部への依存関係も無く、潜在的なボトルネックが生じずらいというメリットがあります。
- スレッドハンドリングの違い
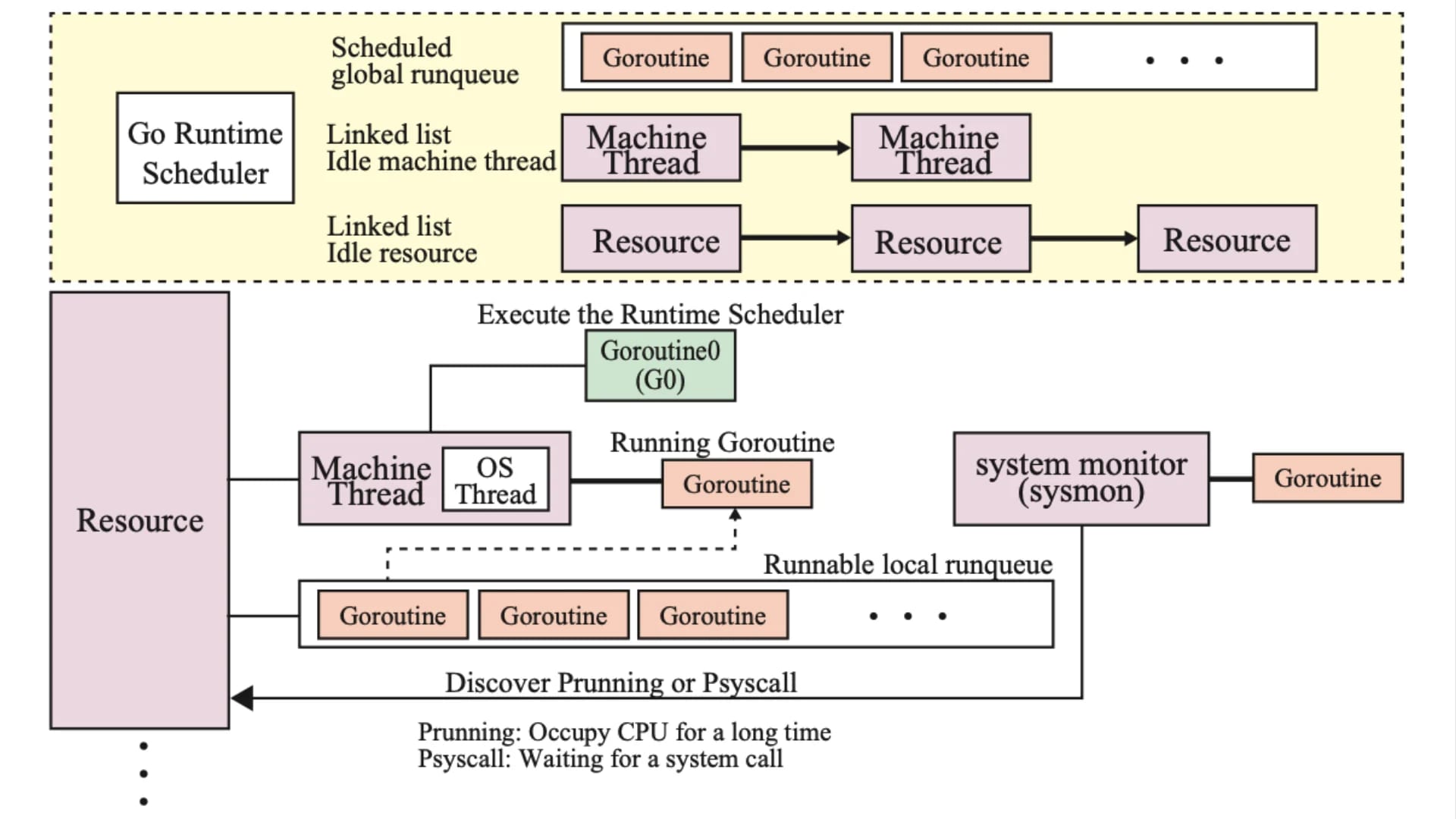
JVM やインタプリタベースのイテレーティブな実装では、1 VU を 1 スレッドに割り当てます。 1 スレッド 1 VU の場合、任意の VM が応答を待つ間、他のスレッドがブロックされて処理が進まなくなるという問題があります。 実際に、JMeter をはじめとする JVM スレッドはデフォルトの 1 MB(ヒープ領域)を使用するため、スレッドの増加に伴いヒープに負荷が掛かってメモリ不足に陥る事例はよく知られています。 また、直接ツールの利用者が気にすることは無いと思いますが、カーネル r スレッド間の通信は厄介で潜在的なボトルネックも発生します。参考
一方の k6 の場合は、各 VU を Goroutine に割り当てて実行するように実装されています。 Goroutine は単一のカーネルスレッド内で、Go のランタイムがユーザ空間スレッドをシミュレートします。 つまり、前述のような課題が非常に発生しずらくなります。 また、Go 言語は 理論的に数十万程度の Goroutine を同時に実行可能である とされています。
Go 言語がなぜ膨大なスレッドを扱えるようになっているのかは、こちら のブログでも紹介しています。
Orenge Diary TechBlog - Goroutine はなぜ軽量スレッドと称されるのか
以上を踏まえると、k6 は、Locust や JMeter と比較しても、少ないコンピューティングリソースで高いパフォーマンスを出せる傾向にあり、大規模負荷試験に伴ういくつかの課題を根本的に解決することができます。
検証事例
Depending on the resources of the load generator, JMeter can run about a thousand virtual users on average, and scaling up your test beyond that point will require a distributed execution setup. A single instance of k6, on the other hand, can run tens of thousands of virtual users given the same resources.
留意すべき点
- メトリクスの保存
大規模な負荷試験を実施すれば、当然得られるデータも肥大化します。 実際に、k6 から得た負荷試験結果のメトリクスは、Persistent Disk のような永続ボリュームで管理します。
また、モニタリングにおいては、Persistent Disk からメトリクスを引き出す際にもタイムアウトが発生する懸念があります。 例えば、VictoriaMetrics や Thanos のような専用のメトリクス管理ツールの導入を検討する必要があるかもしれません。
- カーネルパラメータのチューニング
近年のカーネルは、アプリケーションが作成できる同時ネットワーク接続数の制限が低くめに設定されています。 ネットワーク容量をすべて使用し、最大限パフォーマンスを発揮させたい場合は、必要に応じてカーネルパラメータ(Network capacity, Memory, CPU)のチューニングが必要になります。 特に負荷試験実行時には、ソケットディスクリプタが枯渇し、そもそも TCP セッションを開くことができなくなる場合もあります。 例えば、Amazon Linux(CentOS 系)で k6 を動かす場合、Sender VM の以下のファイルおよびパラメータを編集することで、ネットワーク、メモリ管理、プロセス・ファイルシステムの動作等、カーネルレベルの設定を変更できます。
### システムがブートアップする時に適用されるパラメータ
$ sudo vim /etc/sysctl.conf
### 通信セッションが開始される時に適用されるパラメータ
$ sudo vim /etc/security/limits.conf
### システムが使用するローカルポートの範囲
$ sudo sysctl -w net.ipv4.ip_local_port_range="1024 65535"
### TIME_WAIT 状態の TCP ソケットを再利用するかどうか
$ sudo sysctl -w net.ipv4.tcp_tw_reuse=1
### TCP タイムスタンプを使用するかどうか
$ sudo sysctl -w net.ipv4.tcp_timestamps=1
### 単一ユーザに対する最大 FD 数
$ sudo ulimit -n 250000
ローカル環境でのお手軽負荷試験
負荷試験スクリプトは、基本的に以下の形式に沿って書いていきます。 各セクションは、JavaScript の Named Export や Default Export で定義します。
// 1. 初期化
// 2. API 実行前の処理
export function setup() {
// ログイン、トークンの取得等 API 実行に必要な処理を実装する箇所
}
// 3. API 実行
export default function (data) {
// API を実行するシナリオを実装する箇所
}
// 4. API 実行後の処理
export function teardown(data) {}
他にも、Headless Browser を使ったブラウザテストでは、ユーザの Web 操作(ナビゲーション、マウスとキーボードのアクション、スクリーンショットの撮影)を想定したシナリオも作成できます。 また、Chrome Extension からシナリオを作成できる k6 Browser Recorder という拡張機能もあるみたいです。
k6 CLI
基本書式
$ k6 run [シナリオ].js [コマンドオプション]コマンドオプション
--vus:同時接続数(ユーザ数)--duration:試験の実行時間--rps:Request Per Second(秒間リクエスト数)--iteration:シナリオを繰り返す回数--out:出力形式
例えば、
-vus 10 --duration 10sとした場合、同時接続数 10 人で 10 秒間負荷をかけることができます。 なお、コマンドオプションは直接、JavaScript に記述することも可能です。出力結果
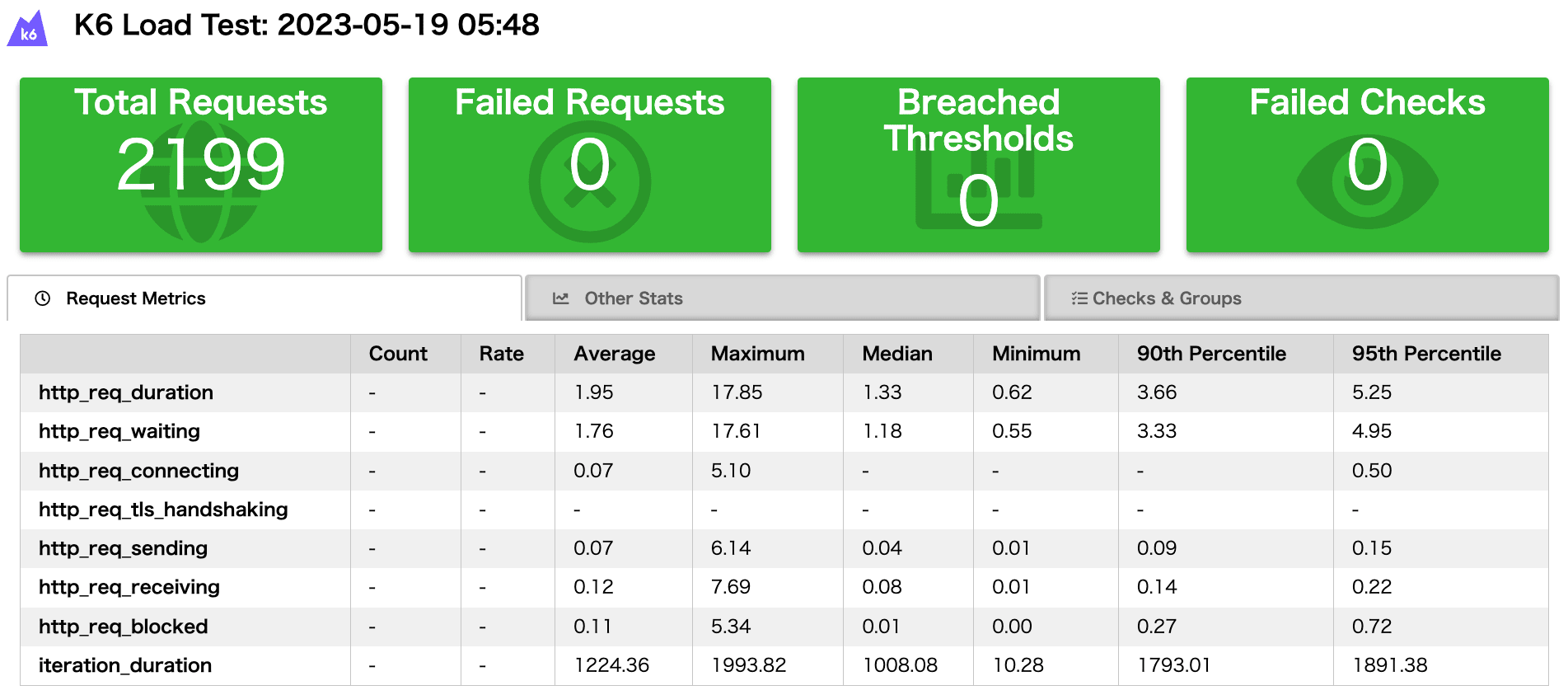
✓ http response status code is 200 checks.........................: 100.00% ✓ 282479 ✗ 0 data_received..................: 241 MB 4.0 MB/s data_sent......................: 28 MB 470 kB/s http_req_blocked...............: avg=12.14µs min=1.49µs med=3.31µs max=105.32ms p(90)=5.09µs p(95)=9.01µs http_req_connecting............: avg=3.43µs min=0s med=0s max=104.73ms p(90)=0s p(95)=0s http_req_duration..............: avg=20.76ms min=190.42µs med=1.29ms max=793.55ms p(90)=92.84ms p(95)=95.96ms { expected_response:true }...: avg=20.76ms min=190.42µs med=1.29ms max=793.55ms p(90)=92.84ms p(95)=95.96ms http_req_failed................: 0.00% ✓ 0 ✗ 282479 http_req_receiving.............: avg=378.45µs min=13.45µs med=34.83µs max=695.53ms p(90)=76.13µs p(95)=190.08µs http_req_sending...............: avg=28.4µs min=3.98µs med=9.24µs max=456.41ms p(90)=17.61µs p(95)=26.8µs http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s http_req_waiting...............: avg=20.35ms min=143.79µs med=1.21ms max=287.99ms p(90)=92.66ms p(95)=95.78ms http_reqs......................: 282479 4702.492214/s iteration_duration.............: avg=21.17ms min=255.46µs med=1.39ms max=794.08ms p(90)=93.04ms p(95)=96.19ms iterations.....................: 282479 4702.492214/s vus............................: 199 min=0 max=199 vus_max........................: 200 min=200 max=200
| 指標 | 概要 | 単位 | 備考 |
|---|---|---|---|
checks | リクエストが成功した割合 | % | |
data_received | レスポンスデータ量 | Total, /s | |
data_sent | リクエエストデータ量 | Total, /s | |
http_req_blocked | TCP 接続の順番待ちをした時間 | avg, min, med, max, p(90), p(95) | |
http_req_connecting | TCP 接続にかかった時間 | avg, min, med, max, p(90), p(95) | |
http_req_duration | http_req_sending + http_req_waiting + http_req_receiveing の合計 | avg, min, med, max, p(90), p(95) | |
expected_response | 正常応答のみの http_req_duration | avg, min, med, max, p(90), p(95) | 正常な応答がない場合、この項目は表示されない |
http_req_failed | リクエストが失敗した割合 | % | threshold をシナリオに追加することでエラー率を定義できる |
http_req_receiving | レスポンスの 1 バイト目が到達してから最後のバイトを受信するまでの時間 | avg, min, med, max, p(90), p(95) | |
http_req_sending | リクエストを送信するのにかかった時間 | avg, min, med, max, p(90), p(95) | |
http_req_tls_handshaking | TLS コネクションの確立にかかった時間 | avg, min, med, max, p(90), p(95) | http の場合は 0s |
http_req_waiting | リクエストが送信完了してからレスポンスが開始されるまでの時間(TTFB:Time To First Byte) | avg, min, med, max, p(90), p(95) | |
http_reqs | リクエスト総数 | Total, /s | 右側が RPS の実測値(この例では 100 RPS) |
iteration_duration | シナリオ 1 ループにかかった時間 | avg, min, med, max, p(90), p(95) | |
iterations | シナリオを繰り返した回数 | Total, /s | |
vus | 並列数(アクセスユーザ数) | ||
vus_max | 最大並列数(ピークユーザ数) |
Docker Compose で負荷試験スタックを起動
https://github.com/GotoRen/k6-operator-playground をベースに、ローカル環境に負荷試験基盤を構築してみます。 今回は、負荷試験の結果を InfluxDB と Prometheus の両方に保存する方法を紹介します。
まず、locals ディレクトリの compose.yaml を起動します。
### リポジトリをクローン
$ git clone [email protected]:GotoRen/k6-operator-playground.git
$ cd ./locals
### Docker Compose を起動
$ docker compose up -d
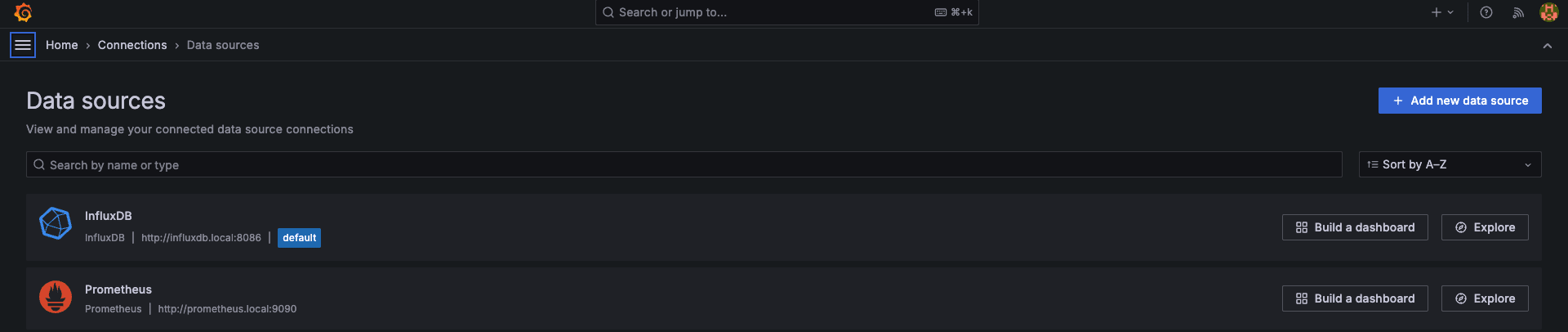
http://localhost:3000 (admin/password)から Grafana ダッシュボードにアクセスして、データソース に InfluxDB と Prometheus が登録されていることを確認します。
今回は InfluxDB v2.7 を使用しますが、通常の k6 イメージは InfluxDB 2 系に対応していない ため、以下のような Dockerfile で xk6 をビルドしてから実行します。
FROM golang:1.23-alpine as builder
RUN apk --no-cache add git \
&& go install go.k6.io/xk6/cmd/xk6@latest \
&& xk6 build --with github.com/grafana/xk6-output-influxdb --output /tmp/k6
FROM alpine:3.20
RUN apk add --no-cache ca-certificates \
&& adduser -D -u 12345 -g 12345 k6
COPY /tmp/k6 /usr/bin/k6
USER 12345
WORKDIR /home/k6
ENTRYPOINT ["k6"]
Docker Compose 上で負荷試験を実行
以下のコマンドで xk6 のビルドと負荷試験の実行、メトリクスを InfluxDB に保存するまでをワンライナーで行えます。
シナリオは、Makefile の SCRIPT_PATH 環境変数で定義しているので、こちらを適宜変更します。
### 負荷試験を実施して、結果を InfluxDB に出力する
$ make run/influxdb-out
[+] Building 37.8s (13/13) FINISHED
(省略)
running (1m01.3s), 000/200 VUs, 23725 complete and 0 interrupted iterations
default ✓ [ 100% ] 000/200 VUs 1m0s
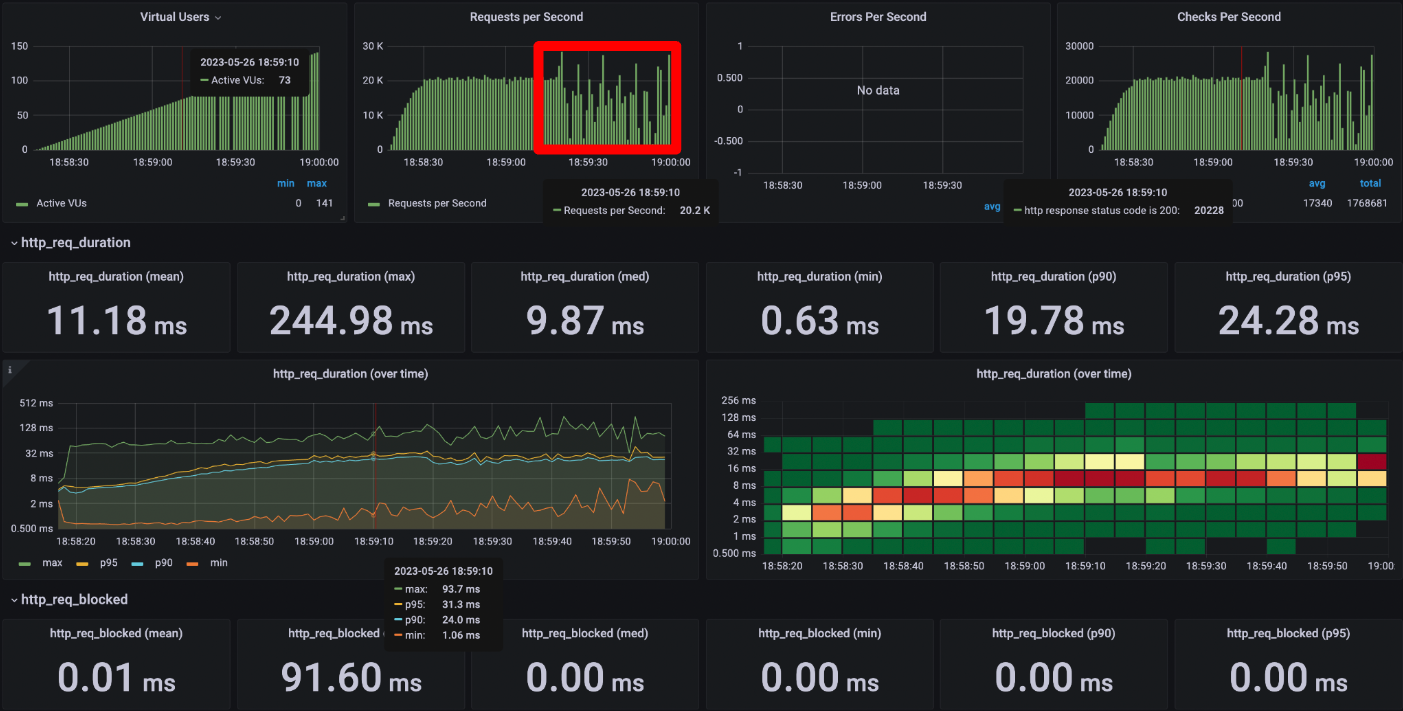
ダッシュボードを確認すると、負荷試験の実行状況が確認できます。
今回は こちら を参考にダッシュボードを準備しています。
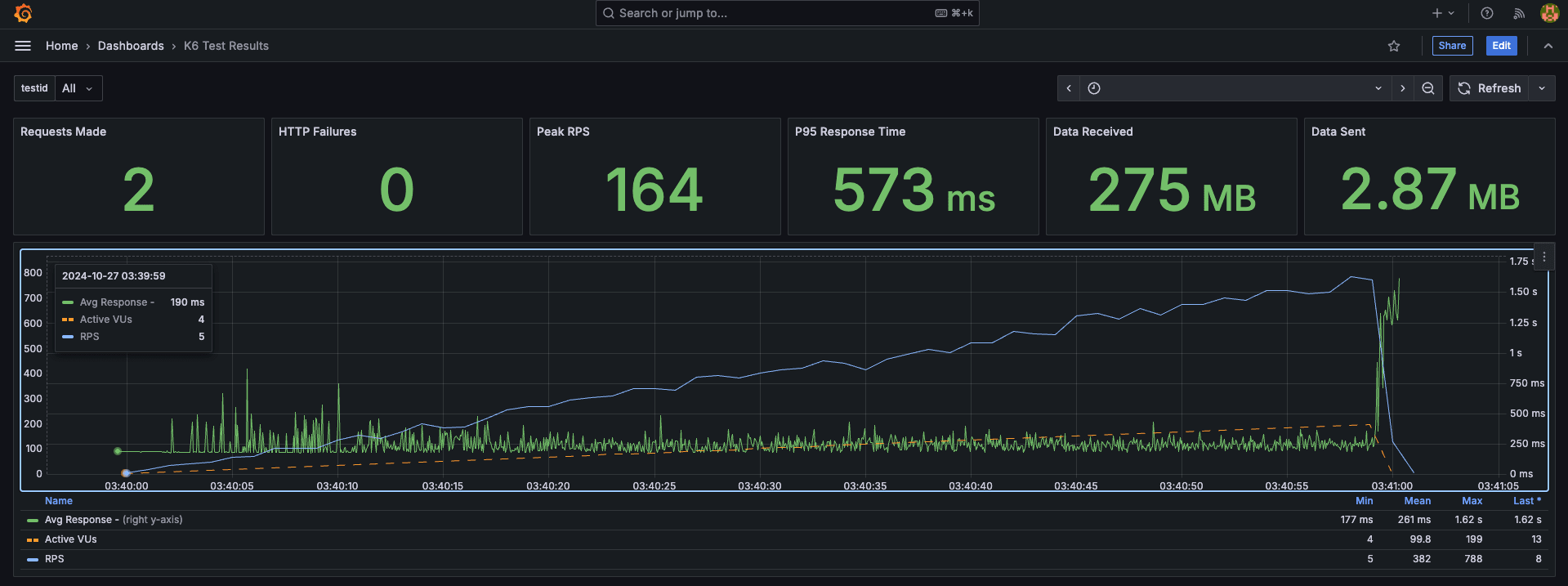
【k6 performance test】
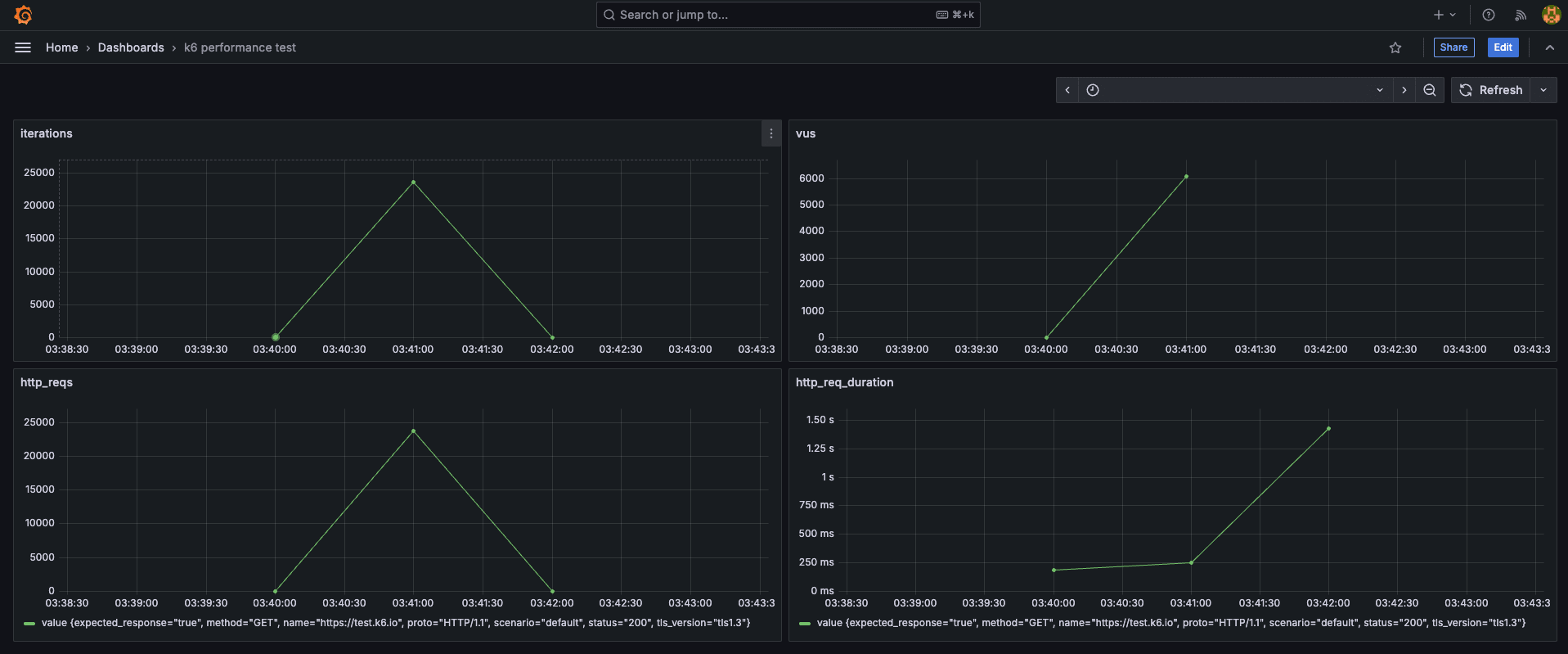
【K6 Test Results】
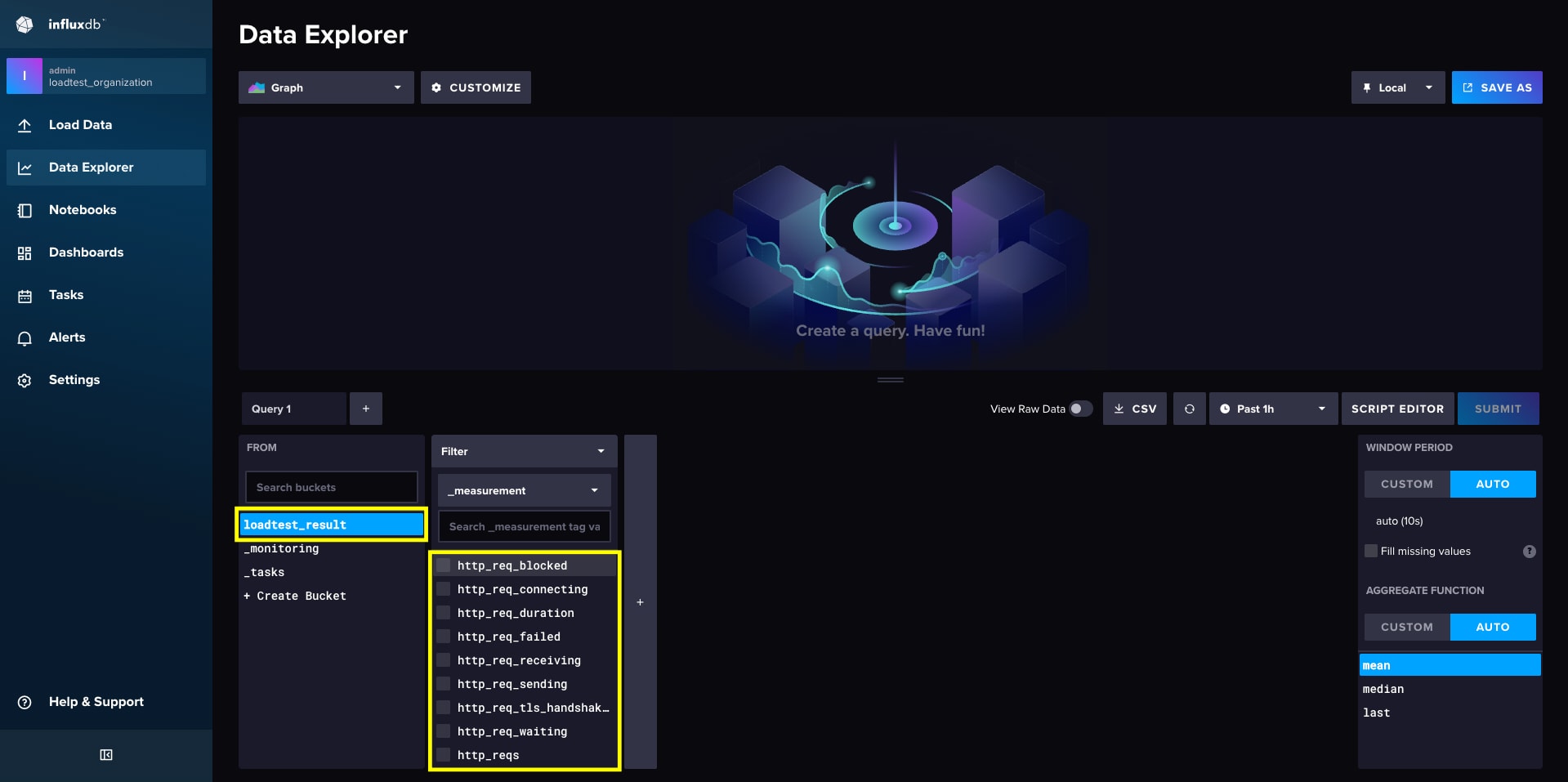
また、http://localhost:8086 (admin/password)にアクセスして、InfluxDB の Data Explorer を確認すると、loadtest_result バケットに負荷試験データが格納されていることが分かります。
続いて、負荷試験の結果を Remote-Write で飛ばして Prometheus に保存する場合は、以下のコマンドを実行します。 こちらは、通常の k6 コマンドが使用できます。
### 負荷試験を実施して、結果を Prometheus に出力する
$ make run/prometheus-out
【Official k6 Test Result】
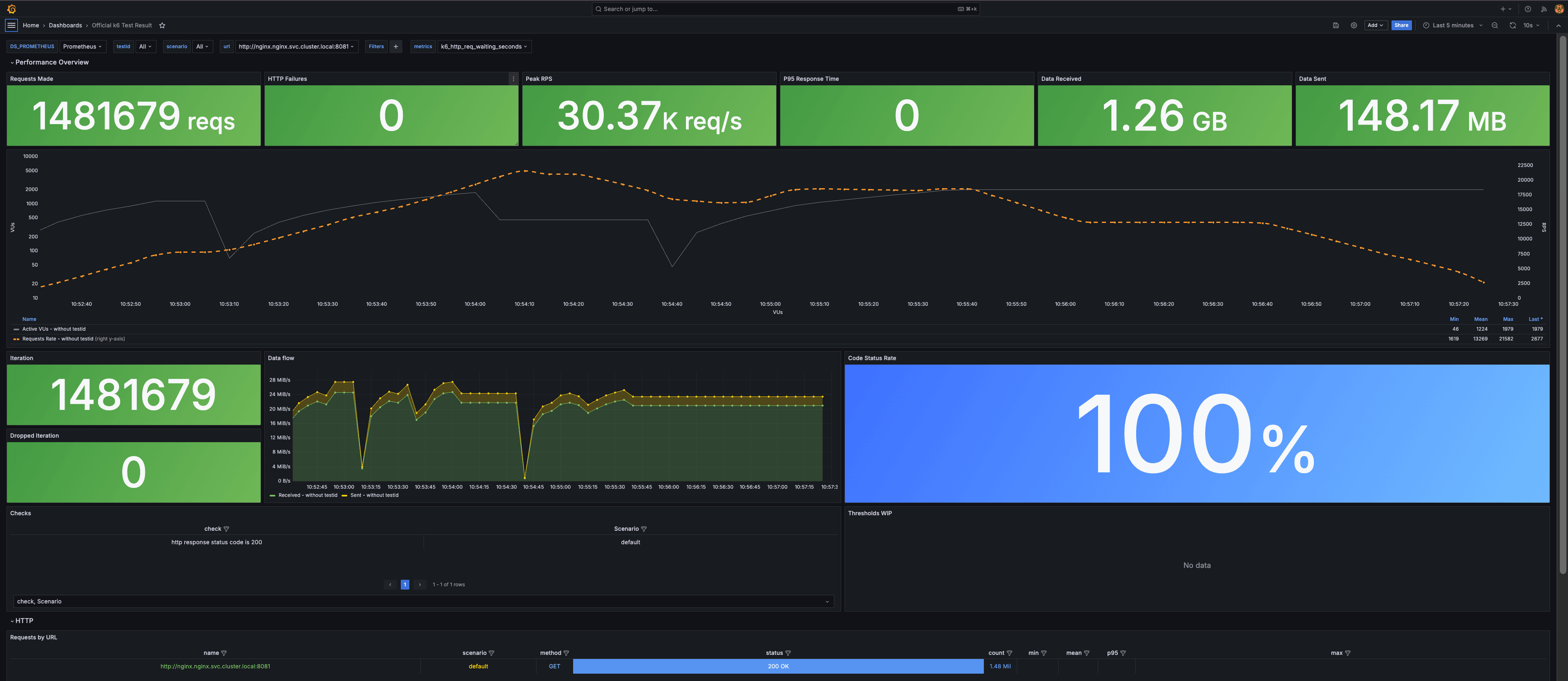
以上のように、Docker Compose を用いれば、ローカル環境にも簡単に負荷試験基盤を構築することができます。
k6-operator による実用的な負荷試験
k6-operator を Kubernetes に導入した、より実用的な負荷試験の構成について紹介します。
Kubernetes に導入
先ほど、Docker Compose で試した構成を Kubernetes 上で構築すると以下のようになります。
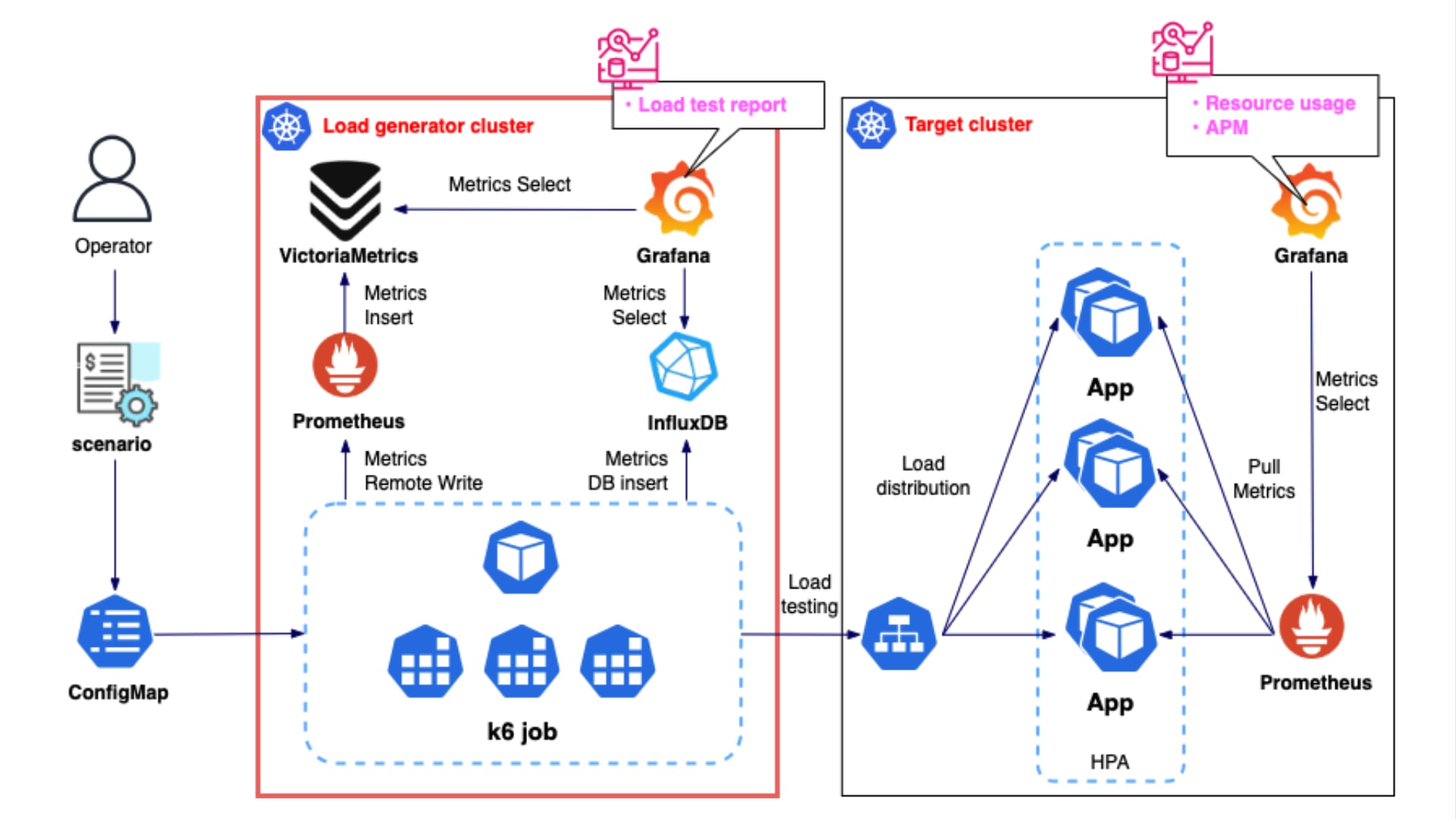
この構成では、InfluxDB と Prometheus(VictoriaMetrics)の 2 つデータストアを使用していますが、実際は負荷試験の規模やメトリクス量に応じてどちらか一方を選択すれば十分かと思います。
小規模な負荷試験であれば、シンプルな構成の InfluxDB で十分だと思いますが、InfluxDB は、メトリクスの格納・引き出しの際に都度レコードの整形が必要なため、負荷をかけ過ぎるとタイムアウトが発生する可能性があります。
The flush operation took higher than the expected set push interval. If you see this message multiple times then the setup or configuration need to be adjusted to achieve a sustainable rate.
Couldn't send metrics points elapsed: context deadline exceeded (Client.Timeout exceeded while awaiting headers)
A query returned too many datapoints and the results have been truncated at 18881 points to prevent memory issues.
このようなエラーが発生した場合は、データフラッシュやタイムアウトの設定をよしなに変更したり、データポイント数を少なくしたりして調整してあげる必要があります。参考
サービス規模が大きく、負荷試験規模が数百万から数千万人を想定するようなケースでは、Prometheus の採用をお勧めします。 それでも、Prometheus 単体で機能不足に陥る場合は、例えば、メトリクスの管理を VictoriaMetrics で行うようにします。 メトリクスデータの長期保存を考慮するなら、初めから VictoriaMetrics は用意しておいた方が良いかもしれません。(このラボは単に Prometheus のみを用います)
負荷試験コンポーネントのデプロイ
今回は、Docker Desktop の Kubernetes Engine を使用します。検証だけならシングルノードクラスタで構いません。
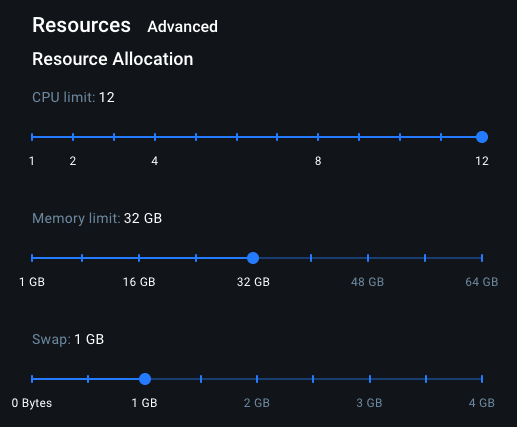
ただし、デフォルトでは Docker Desktop のリソース割り当ては低めに設定されているため、負荷試験を行う際は普段よりも多めに確保しておいた方が良さそうです。
とりあえず以下のように設定しました。
| 設定項目 | 設定値 |
|---|---|
| CPU limit | 12 vCPU |
| Memory limit | 32 GiB |
| Swap | 1 GiB |
以下のコマンドでクラスタを確認します。
$ kubectl config current-context; kubectl get namespace
docker-desktop
NAME STATUS AGE
default Active 38d
kube-node-lease Active 38d
kube-public Active 38d
kube-system Active 38d
マニフェストはメンテンスの観点より、Helm on Kustomize で定義しています。
| Namespace | Name | Charts | Chart version | Application version |
|---|---|---|---|---|
| monitoring | kube-prometheus-stack | https://prometheus-community.github.io/helm-charts | v62.7.0 | v0.76.1 |
| kube-system | metrics-server | https://kubernetes-sigs.github.io/metrics-server | v3.12.2 | v0.7.2 |
| influxdb | influxdb2 | https://helm.influxdata.com | v2.1.2 | v2.7.4 |
| k6-operator | k6-operator | https://grafana.github.io/helm-charts | v.0.0.17 | v3.9.0 |
kube-prometheus-stack
### monitoring NS を作成
$ kubectl create namespace monitoring
### kube-prometheus-stack
$ cd ./manifests/platform/kube-prometheus-stack/playground
### Helm Chart でデプロイ
$ kustomize build . --enable-helm | kubectl apply -f - --server-side
kube-prometheus-stack の CRD には、metadata.annotations が 262144 bytes(≒ 260 KB)を超えるリソースが含まれているため、Server-Side Apply でデプロイします。
[resource mapping not found for name: "kube-prometheus-stack-alertmanager" namespace: "monitoring" from "STDIN": no matches for kind "Alertmanager" in version "monitoring.coreos.com/v1"
ensure CRDs are installed first, resource mapping not found for name: "kube-prometheus-stack-prometheus" namespace: "monitoring" from "STDIN": no matches for kind "Prometheus" in version "monitoring.coreos.com/v1"
ensure CRDs are installed first]
Error from server (Invalid): error when creating "STDIN": CustomResourceDefinition.apiextensions.k8s.io "alertmanagers.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
Error from server (Invalid): error when creating "STDIN": CustomResourceDefinition.apiextensions.k8s.io "prometheusagents.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
Error from server (Invalid): error when creating "STDIN": CustomResourceDefinition.apiextensions.k8s.io "prometheuses.monitoring.coreos.com" is invalid: metadata.annotations: Too long: must have at most 262144 bytes
is invalid: metadata.annotations: Too long: must have at most 262144 bytes
InfluxDB
### influxdb NS を作成
$ kubectl create namespace influxdb
### influxdb
$ cd ./manifests/platform/influxdb/playground
### Helm Chart でデプロイ
$ kustomize build . --enable-helm | kubectl apply -f -
k6-operator
### k6-operator NS を作成
$ kubectl create namespace k6-operator
### k6-operator
$ cd ./manifests/platform/k6-operator/playground
### Helm Chart でデプロイ
$ kustomize build . --enable-helm | kubectl apply -f -
metrics-server
必要に応じてデプロイします。
特に Docker Desktop Kubernetes では、ちょっとした検証でも OOM が発生する可能性があるため、metrics-server でリソース使用量を取得・把握して調整すると良いです。
### metrics-server
$ cd ./manifests/platform/metrics-server/playground
### Helm Chart でデプロイ
$ kustomize build . --enable-helm | kubectl apply -f -
nginx
負荷試験対象として nginx をデプロイします。
### nginx
$ cd ./manifests/services/nginx/playground
### Helm Chart でデプロイ
$ kustomize build . | kubectl apply -f -
データソースの確認
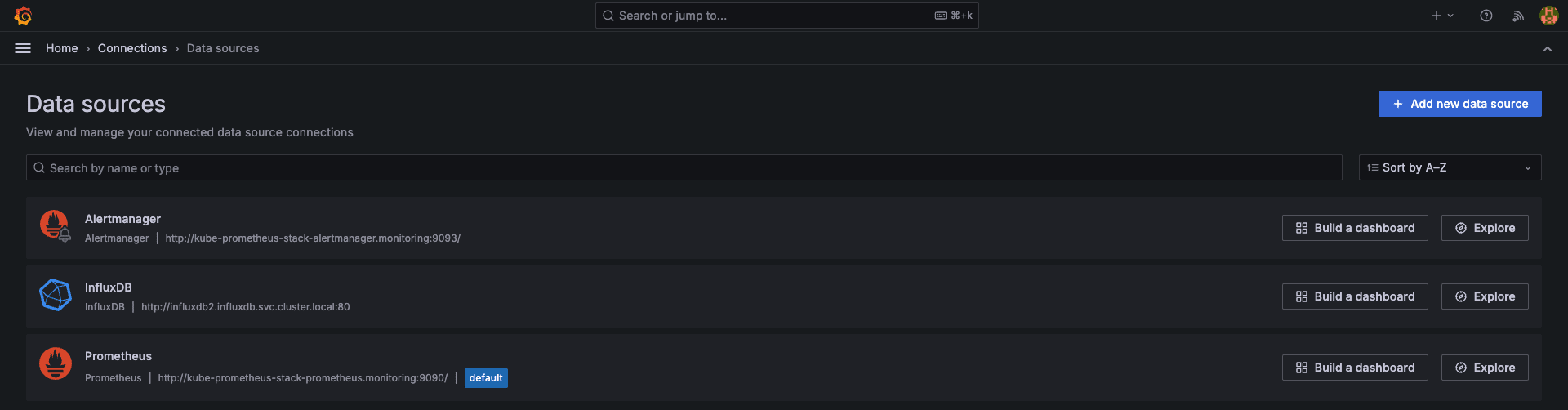
### Grafana に接続
$ kubectl port-forward -n monitoring service/kube-prometheus-stack-grafana 3000:80
http://localhost:3000 (admin/password)から Grafana ダッシュボードにアクセスして、データソース に InfluxDB と Prometheus が登録されていることを確認します。
Kubernetes 上で負荷試験を実行
コマンド
基本的に以下で準備している 3 つの make コマンド で実行できるようにしています。
1. シナリオファイルから ConfigMap を生成してデプロイする(既存の ConfigMap があれば削除して更新する)
このコマンドにより、JavaScript で定義された負荷スクリプトから ConfigMapGenerator で ConfigMap リソースを生成・適用します。
$ make generate/configmap
sh ./load/scripts/gen-k6-scenarios-configmaps.sh
find ./load/scenarios/ -type f -name "configmap.yaml" -exec kubectl apply -f {} \;
configmap/k6-operator-example02 created
configmap/k6-operator-example01 created
2. カスタムリソースをデプロイして負荷試験を開始する(1 で生成した ConfigMap を参照)
TestRun カスタムリソースは、まず initializer Job を生成し、次に starter Job を起動、最後に負荷試験を実行する Sender Job を作成します。
$ make run/job
sh ./load/scripts/run-load-testing.sh example01 1
k6.k6.io/k6-operator-example01 created
Applied TestRun CR
3. 負荷試験を停止して 2 でデプロイしたカスタムリソースを削除する
負荷試験を中断したい場合や、デプロイしたワークロードを削除する場合は以下のコマンドを実行します。
$ make stop/job
k6.k6.io "k6-operator-example01" deleted
定義ファイル
主に以下の 2 つのファイルのみを適宜変更して負荷試験を実行します。
ベースとなるカスタムリソースが定義されています。 base.yaml を元に、run/job コマンドで以下のスクリプトを実行して、カスタムリソースファイルから各シナリオ毎に Job が生成されます。
#!/usr/bin/env bash
set -o errexit
set -o nounset
set -o pipefail
SCENARIOS_DIR=$(dirname "$0")/../
NAME=k6-operator-$1
PARAL=$2
if [ -z "${NAME}" ]; then
NAME=k6-operator-no-name
fi
if [ -z "${PARAL}" ]; then
PARAL=1
fi
yq ea '
.metadata.name = "'"${NAME}"'" |
.spec.parallelism = '${PARAL}' |
.spec.script.configMap.name = "'"${NAME}"'"
' "${SCENARIOS_DIR}/k6/base.yaml" >"${SCENARIOS_DIR}/k6/k6.yaml"
kubectl apply -f "${SCENARIOS_DIR}/k6/k6.yaml"
echo "Applied TestRun CR"
import http from 'k6/http'
import { check } from 'k6'
export const options = {
stages: [
{ target: 100, duration: '1m30s' },
{ target: 200, duration: '1m30s' },
{ target: 300, duration: '1m30s' },
{ target: 400, duration: '1m30s' },
],
}
export default function () {
const result = http.get('http://nginx.nginx.svc.cluster.local:8081')
check(result, {
'http response status code is 200': result.status === 200,
})
}
シナリオを定義します。 便宜上、スクリプトファイルは一律で load-test.js という名前にします。 複数のシナリオを準備する場合は、example01, example02, example03, ... のように定義します。 ここで、example01 等はシナリオ名に相当します。
また、configmap.yaml は、上で説明している generate/configmap コマンドで自動的に生成されます。
apiVersion: v1
data:
load-test.js: |
import http from "k6/http";
import { check } from "k6";
export const options = {
stages: [
{ target: 100, duration: "1m30s" },
{ target: 200, duration: "1m30s" },
{ target: 300, duration: "1m30s" },
{ target: 400, duration: "1m30s" },
],
};
export default function () {
const result = http.get("http://nginx.nginx.svc.cluster.local:8081");
check(result, {
"http response status code is 200": result.status === 200,
});
}
kind: ConfigMap
metadata:
creationTimestamp: null
name: k6-operator-example01
負荷試験の結果を Prometheus に送信
負荷試験を実行して、Prometheus に結果を出力する場合は、./load/k6/base.yaml に以下のカスタムリソースを使用します。
apiVersion: k6.io/v1alpha1
kind: TestRun
metadata:
name: k6-operator-example01
namespace: k6-operator
spec:
parallelism: 1
arguments: -o experimental-prometheus-rw
script:
configMap:
name: k6-operator-example01
file: load-test.js
runner:
env:
- name: K6_PROMETHEUS_RW_SERVER_URL
value: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090/api/v1/write
まず、シナリオをクラスタにデプロイします。
$ make generate/configmap
run/job で負荷試験を開始します。 この時に、引数として任意のシナリオと、負荷試験の際の並列数を渡すこともできます。
$ make run/job NAME=[シナリオ名] PARAL=[同時実行数]
負荷試験が終了すると、Pod のログにも出力されます。
$ kubectl logs -f -n k6-operator [Sender Pod 名]
✓ http response status code is 200
checks.........................: 100.00% ✓ 282479 ✗ 0
data_received..................: 241 MB 4.0 MB/s
data_sent......................: 28 MB 470 kB/s
http_req_blocked...............: avg=12.14µs min=1.49µs med=3.31µs max=105.32ms p(90)=5.09µs p(95)=9.01µs
http_req_connecting............: avg=3.43µs min=0s med=0s max=104.73ms p(90)=0s p(95)=0s
http_req_duration..............: avg=20.76ms min=190.42µs med=1.29ms max=793.55ms p(90)=92.84ms p(95)=95.96ms
{ expected_response:true }...: avg=20.76ms min=190.42µs med=1.29ms max=793.55ms p(90)=92.84ms p(95)=95.96ms
http_req_failed................: 0.00% ✓ 0 ✗ 282479
http_req_receiving.............: avg=378.45µs min=13.45µs med=34.83µs max=695.53ms p(90)=76.13µs p(95)=190.08µs
http_req_sending...............: avg=28.4µs min=3.98µs med=9.24µs max=456.41ms p(90)=17.61µs p(95)=26.8µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=20.35ms min=143.79µs med=1.21ms max=287.99ms p(90)=92.66ms p(95)=95.78ms
http_reqs......................: 282479 4702.492214/s
iteration_duration.............: avg=21.17ms min=255.46µs med=1.39ms max=794.08ms p(90)=93.04ms p(95)=96.19ms
iterations.....................: 282479 4702.492214/s
vus............................: 199 min=0 max=199
vus_max........................: 200 min=200 max=200
Grafana ダッシュボードに こちらの Official k6 Test Result をサンプルとして追加してみます。

こちらの GIF では、負荷試験の様子がリアルタイムにモニタリングできていることが分かるかと思います。
他にも多様なダッシュボードが公開されているので利用してみました。
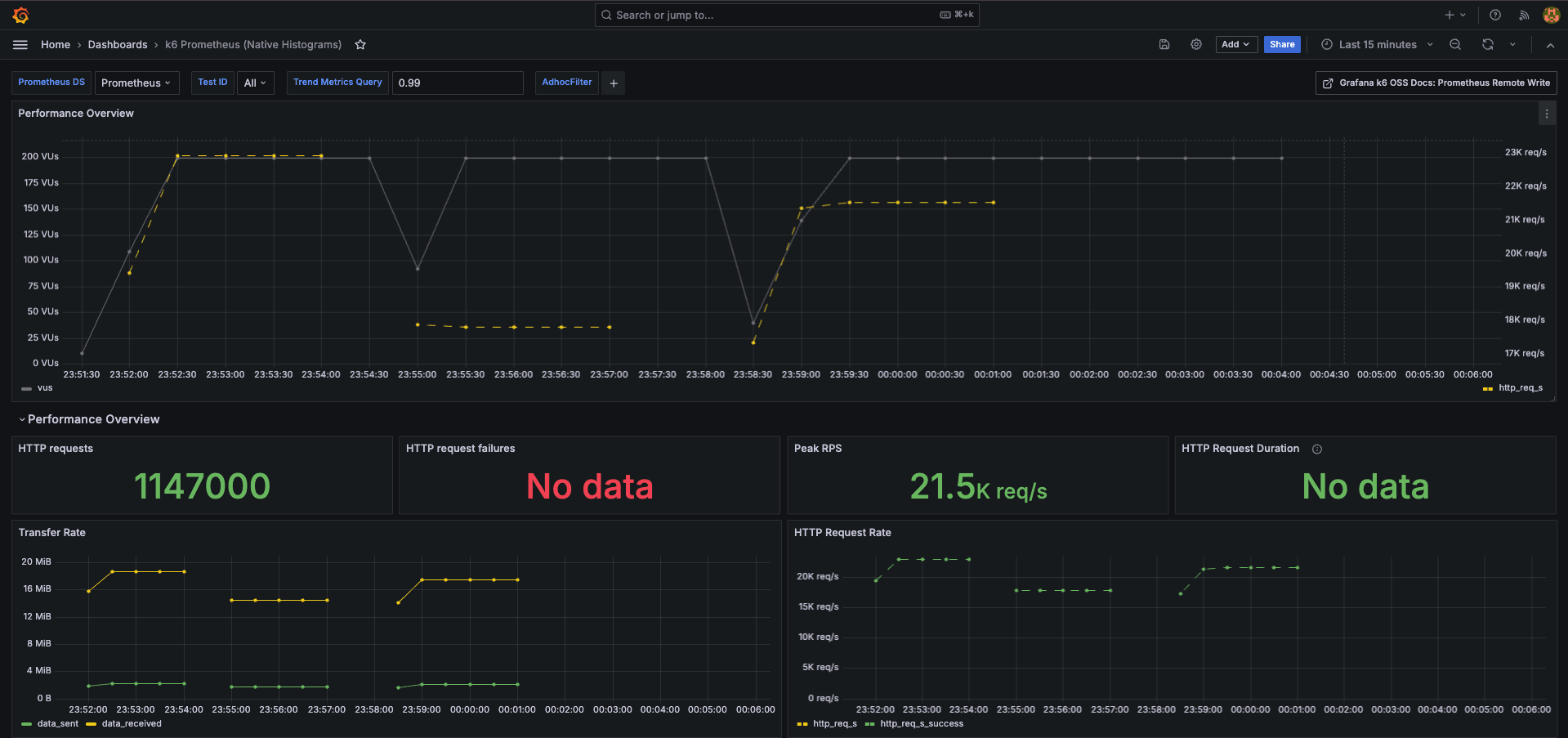
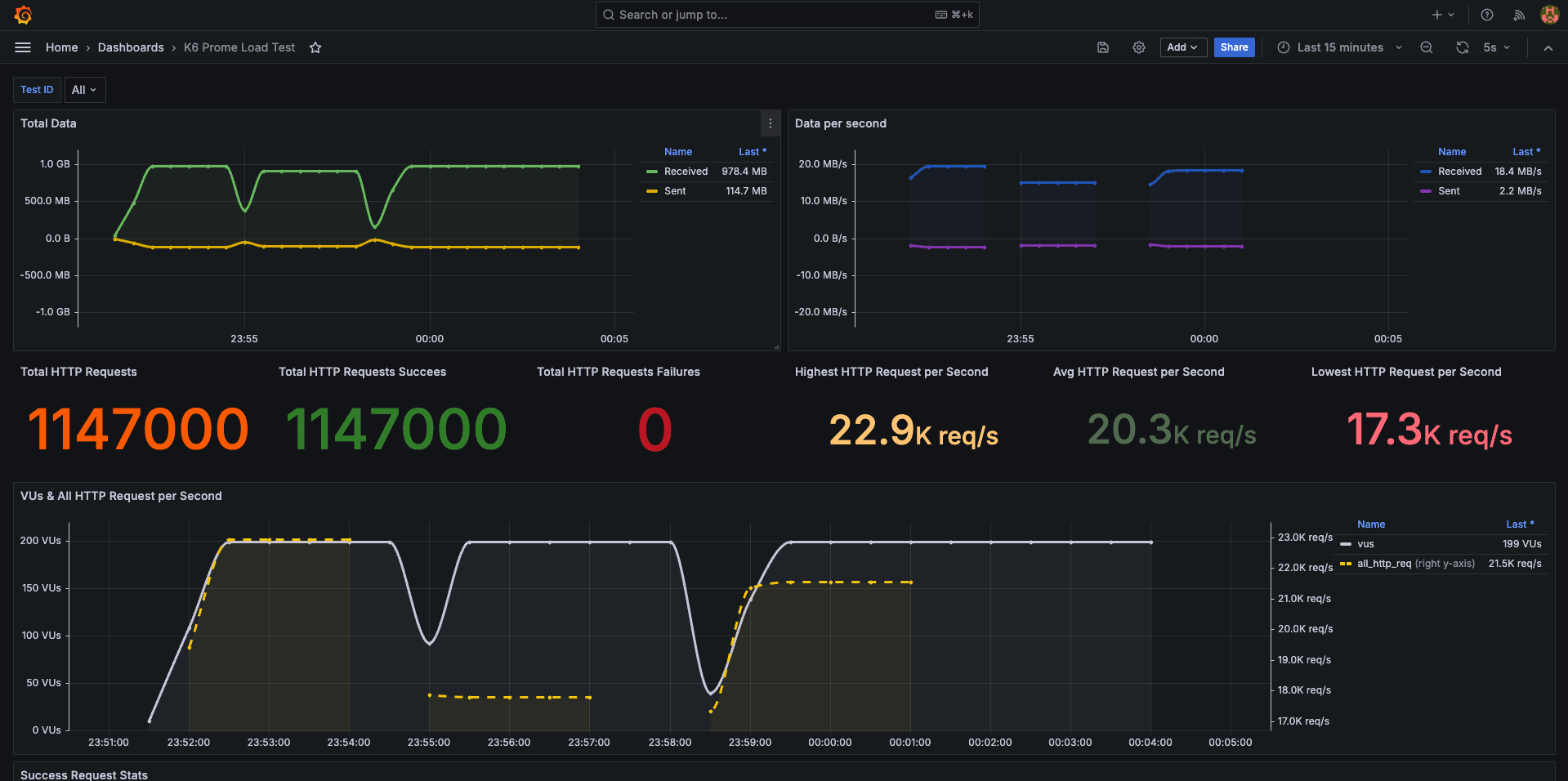
実際は、サービス毎に見たい情報は様々かと思うので、必要なパネルを整備してあげてください。
負荷試験の結果を InfluxDB に送信
こちらは、./load/k6/base.yaml に以下のカスタムリソースを使用します。
apiVersion: k6.io/v1alpha1
kind: TestRun
metadata:
name: k6-operator-example01
namespace: k6-operator
spec:
parallelism: 1
arguments: -o xk6-influxdb=http://influxdb2.influxdb.svc.cluster.local:80
script:
configMap:
name: k6-operator-example01
file: load-test.js
runner:
image: ren1007/k6:latest ## xk6 カスタムイメージを使用
env:
- name: K6_INFLUXDB_ORGANIZATION
value: 'loadtest_organization'
- name: K6_INFLUXDB_BUCKET
value: 'loadtest_result'
- name: K6_INFLUXDB_TOKEN
value: 'admin_token'
- name: K6_INFLUXDB_PUSH_INTERVAL ## メトリクスの送信間隔を調整
value: '30s'
resources: ## リソース割り当て量を調整
requests:
memory: '2Gi'
cpu: '1'
limits:
memory: '4Gi'
cpu: '2'
InfluxDB 2 系を使用する場合はいくつか注意点があります。 先でも述べている通り、現在、k6 は InfluxDB 1 系のみをサポートしており、2 系には対応していません。
なのでカスタムイメージを使用します。 こちら で定義している Dockerfile をコンテナレジストリ(Docker Hub)にアップロードしたものを Pull して使用します。 arm64 でビルドしているので、必要に応じて amd イメージを準備してください。
また、InfluxDB は陳腐なリソースで負荷試験を実施しようとすると、タイムアウトや OOM 等、度々嬉しくない事態が起きはじめる可能性があるので、予め K6_INFLUXDB_PUSH_INTERVAL でメトリクスの更新間隔をデフォルトの 1 秒から伸ばしたり、runner.resources でリソース割り当て量を調整したりします。
こちらも同様に、generate/configmap でシナリオをデプロイし、run/job で負荷試験を開始します。
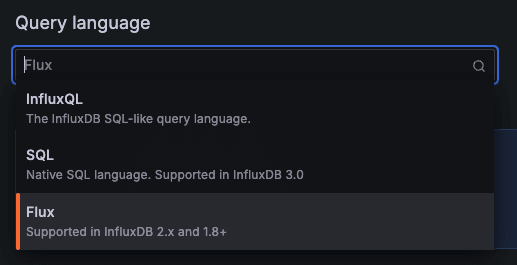
Grafana の Explore からいくつか Flux クエリ を投げてみます。
-- レスポンスタイム(ウィンドウ期間毎の平均応答時間)
from(bucket: v.defaultBucket)
|> range(start: v.timeRangeStart, stop:v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "http_req_duration")
|> filter(fn: (r) => r._field == "value")
|> filter(fn: (r) => r.status == "200")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> yield(name: "mean")
-- ユーザ数
from(bucket: v.defaultBucket)
|> range(start: v.timeRangeStart, stop:v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "vus")
-- リクエスト数
from(bucket: v.defaultBucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "http_reqs")
|> filter(fn: (r) => r["_field"] == "value")
|> group(columns: ["_measurement"])
|> aggregateWindow(every: 1s, fn: sum, createEmpty: false)
|> yield(name: "sum")
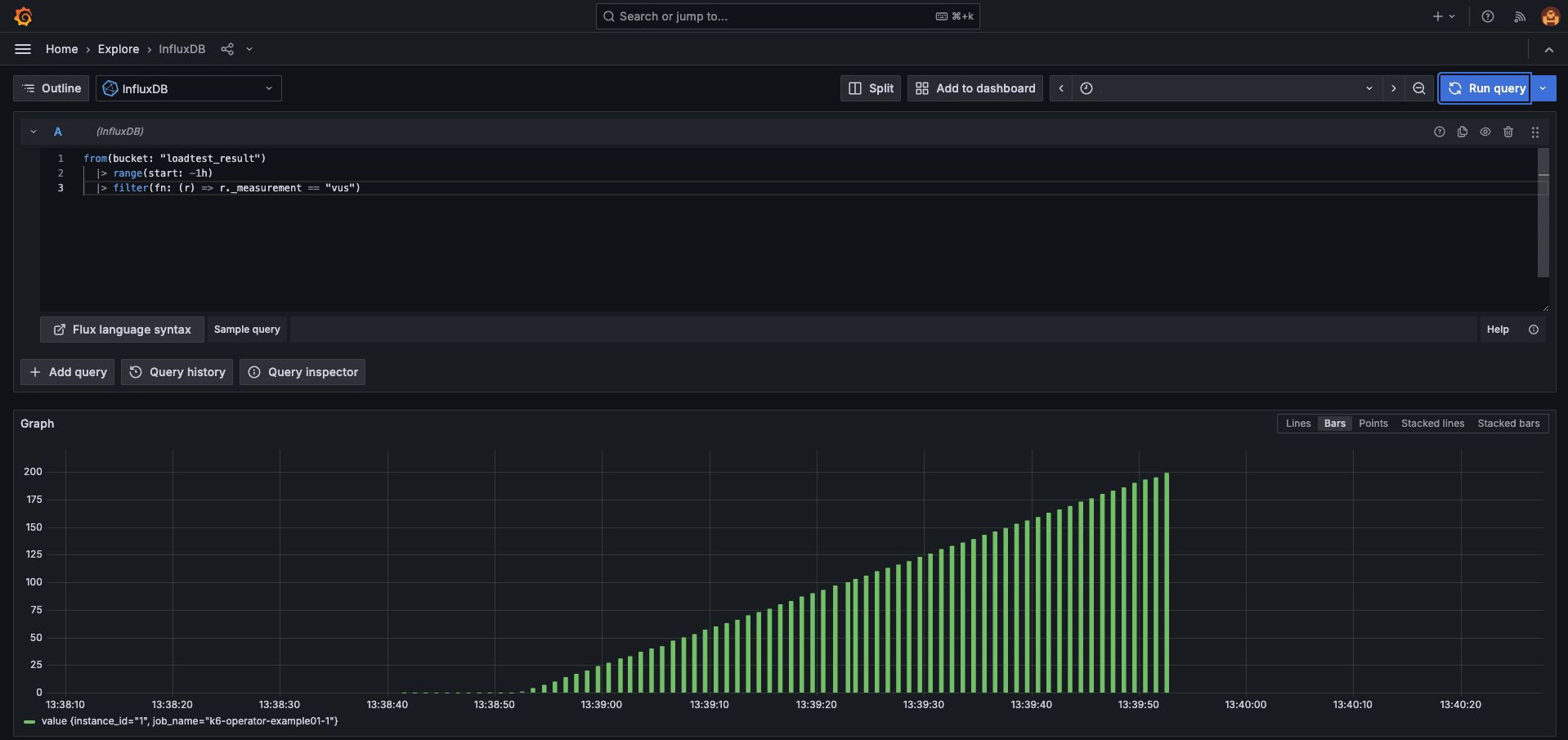
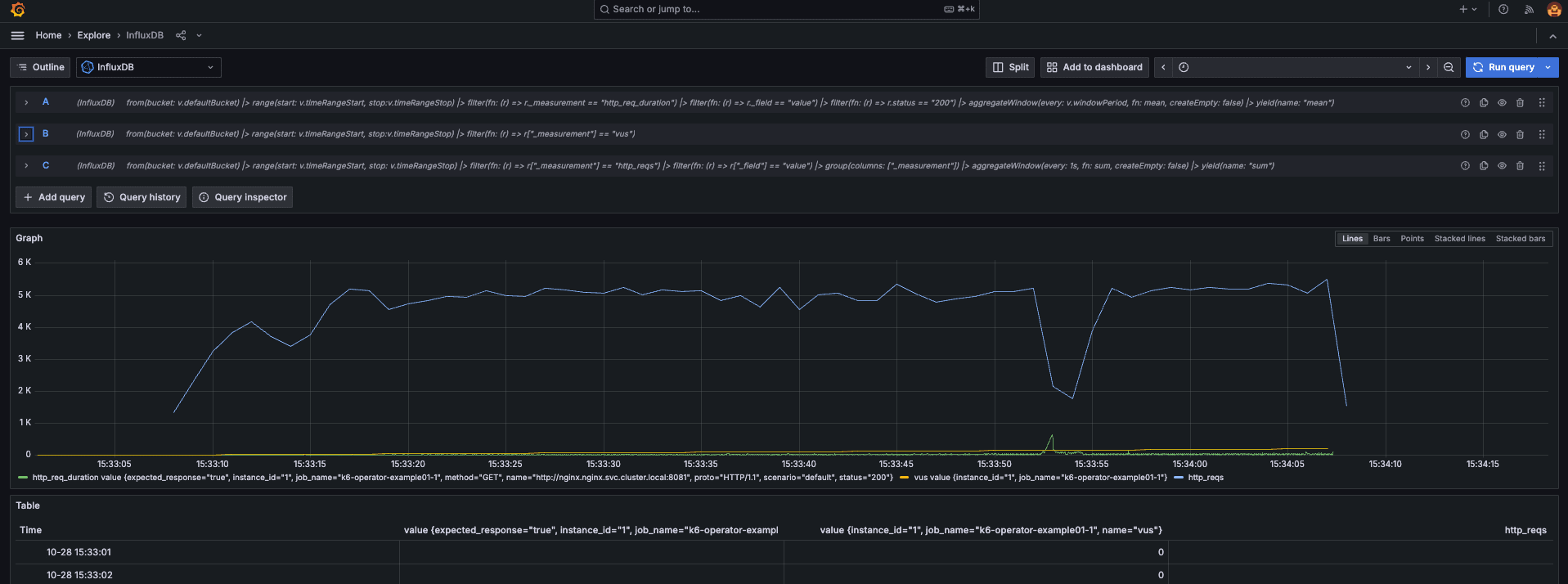
ちゃんと取得できていそうですね。
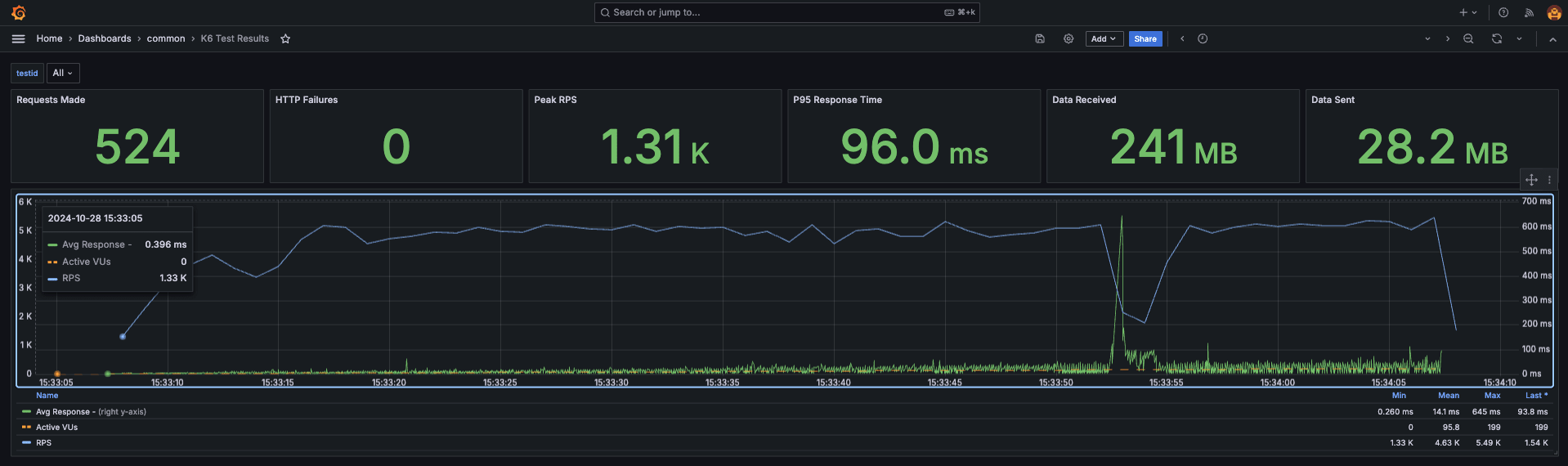
こちら のダッシュボードを使用すると、以下のように負荷試験の結果がモニタリングできます。
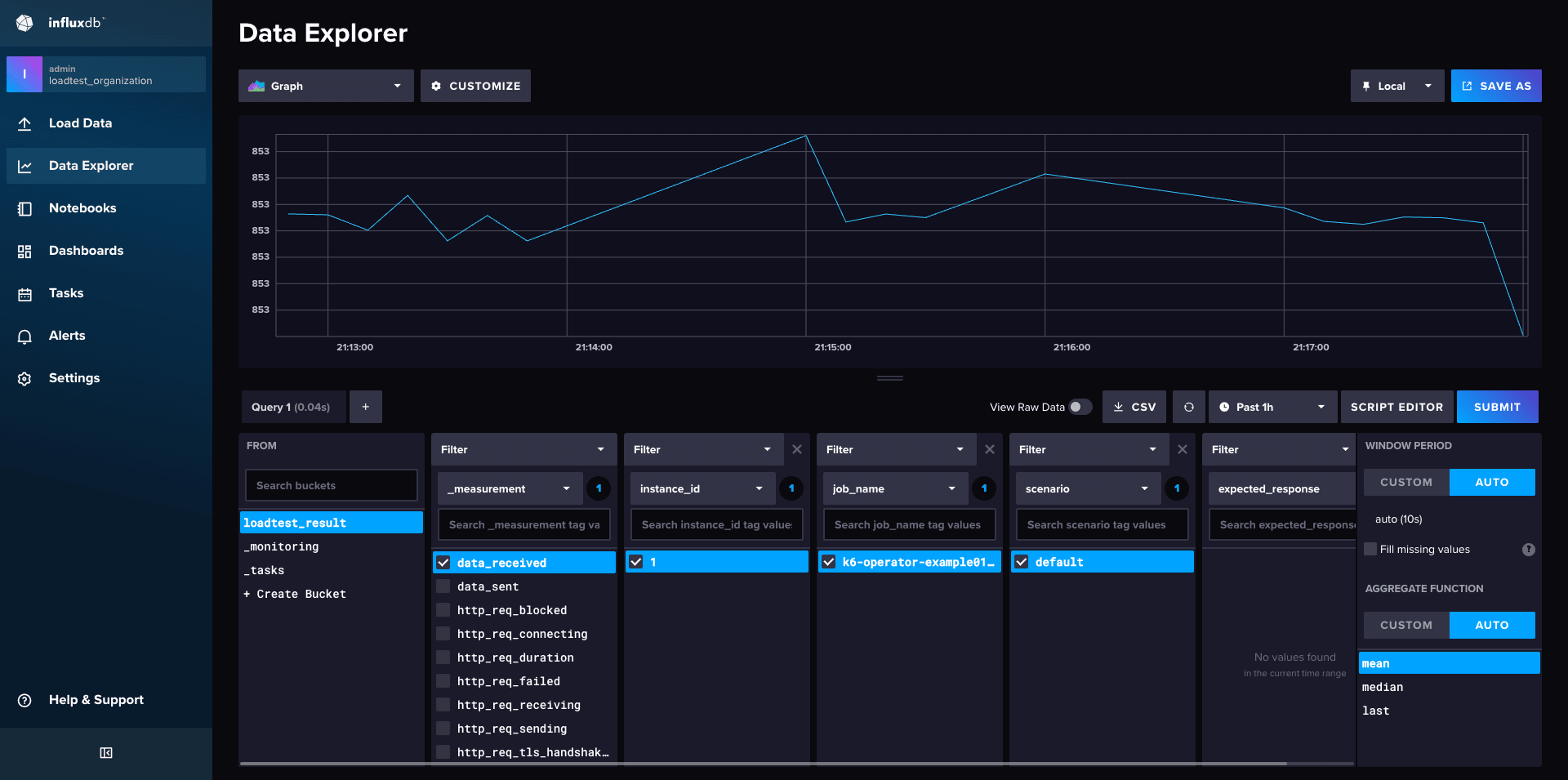
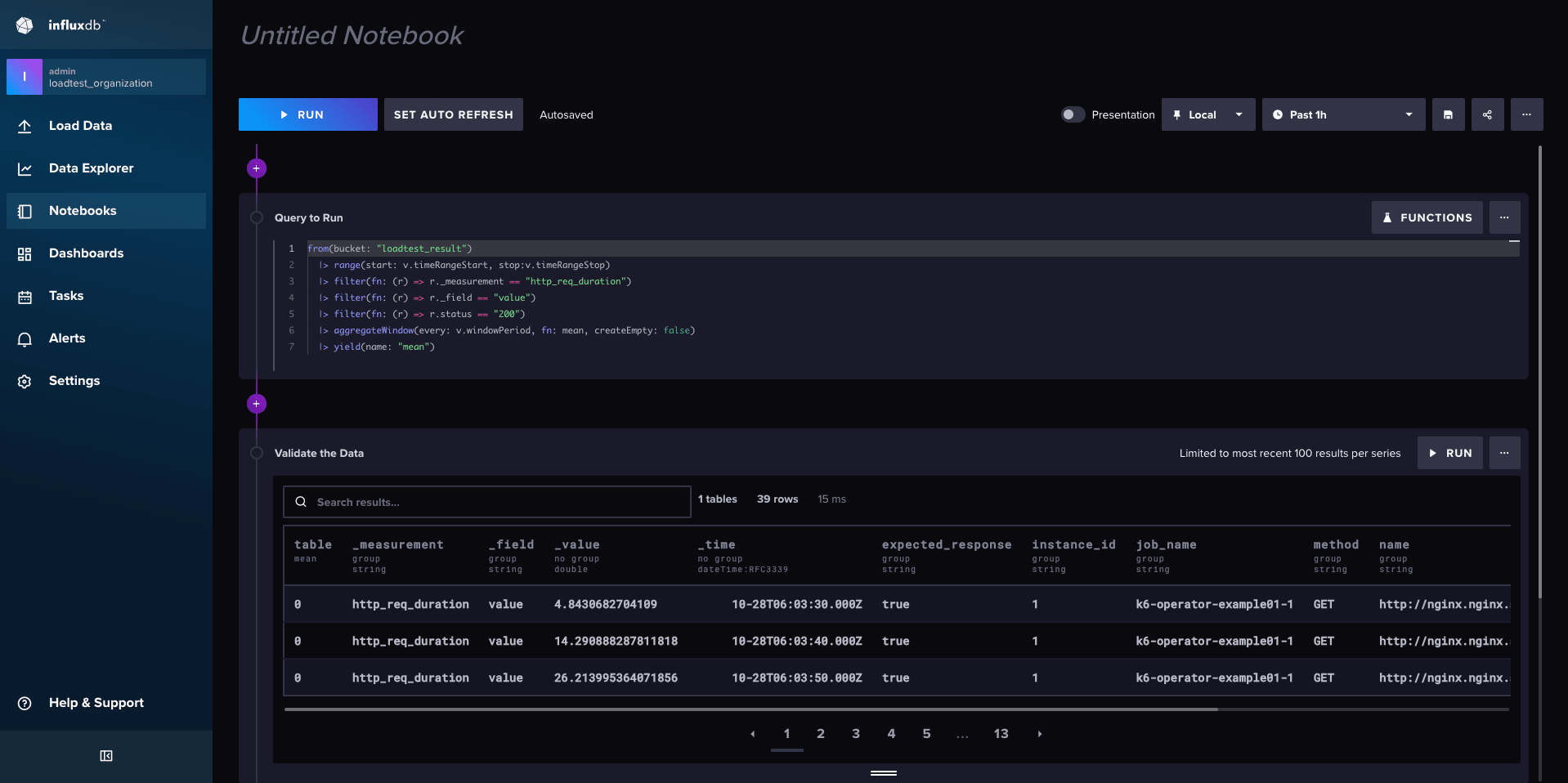
InfluxDB の Data Explorer や Notebooks でも負荷試験の結果をプロットすることができます。
まとめ
今回は、Docker Compose によるお手軽な負荷試験環境の構築と、Docker Desktop の Kubernetes Engine を使用した、より実用的な負荷試験環境の構築について紹介してみました。
ちなみに、ローカル環境で 100,000 RPS を超える負荷をかけてみましたが、Docker Desktop はもちろんのこと、PC 自体がクラッシュしそうになりました。 K9s でも普段見かけない表示が出ました 😇

当然のことながらローカル環境でかけられる負荷は本番で想定されるリクエストよりも遥かに低いため、実際は EKS や GKE 等のプロダクション向け Kubernetes を使用します。
実際に、クラウドサービス上で負荷試験を行う際は、ネットワーク環境やレートリミット等、関連する事項を考慮し、必要に応じて暖機やベンダとのやり取りが必要になる場合があります。 パブリッククラウドは Egress 通信料が高い傾向にあるため、不用意な負荷試験を行うとコストが爆発する可能性もあるので注意が必要です。
また、k6 に限った話ではありませんが、一般公開されているエンドポイントに負荷をかけると DoS/DDoS 攻撃として判定されたり、アカウント自体が BAN の対象になってしまったりする恐れがあるので、くれぐれも気を付けて扱ってください。
余談
k6 自体は Influx 1 系の利用を推奨しており、2 系に関してはほとんど整備されていません。
そもそも、InfluxDB 自体が 1 系 と 2 系 で破壊的な変更が入っており、『データベース(ブロックストレージ)』から『バケット(オブジェクトストレージ)』に変わっています。 クエリ言語も、1 系は SQL ライクな InfluxQL を使用しますが、InfluxDB 2 系では、Flux を使用します。参考
これに伴い各種パラメータや引数も変えてやる必要があるので、 Influx 2 系をチャレンジングに使用する場合はある程度の理解が必要になります。