Go 言語における Scanning の特性と使い分け
はじめに
Go で競技プログラミングに臨んだことがある人なら、一度は fmt.Scan 関数の落とし穴にハマったことがあるのではないでしょうか。
Go では標準入力を受け付ける際に、fmt.Scan 関数、もしくは bufio.Scanner メソッドや bufio.ReadLine メソッドをよく用います。
しかし、Go を使って競技プログラミングをやる場合、bufio.Scanner を使用しなければ困る場面があります。
今回のブログでは、fmt パッケージの Scan 関数と bufio パッケージの Scanner メソッドに注目しながら、fmt.Scan で TLE が発生する原因と解決策について紹介します。
fmt.Scan
まずは、fmt.Scan 関数の詳細を見てみます。
fmt.Scan で TLE が発生する
競プロにおいて、大量のデータ入力が必要になる場合があります。 例えば、競プロでよく見かける以下の入力形式において
ここで、レギュレーションとして N の最大値を とします。 一般的に Go ではこのような形式で入力を受け付ける時、
のような書き方をするのではないでしょうか。
この時、N の最大値は なので、for 文の中では 300 万件ものデータを受け付けなければなりません。
そのため、このような状況において ② の箇所で fmt.Scan を使うと大抵、TLE(Time Limit Exceeded)でコケてしまいます。
なぜ fmt.Scan だとダメなのか
なぜ、fmt.Scan だと TLE するのかを理解するために、fmt パッケージの scan.go を読みに行ってみます。
Scan は、標準入力から読み込んだテキストをスキャンし、スペースで区切られた値として、順に引数に格納します。 改行文字はスペースとしてカウントされます。この関数はスキャンに成功した項目数を返します。 この数が、引数の数より少ないときは、err にその理由を返します。
Fscan は、r (io.Reader) から読み取られたテキストをスキャンし、スペースで区切られた連続する値を連続する引数に格納します。 改行はスペースとしてカウントされます。 正常にスキャンされたアイテムの数を返します。 それが引数の数より少ない場合、err はその理由を報告します。
fmt.Scan は内部的に fmt.Fscan 関数を呼び出します。
つまり、fmt.Scan は fmt.Fscan のラッパー関数であり、引数の io.Reader に標準入力を渡しているだけです。
I/O 処理はプログラムを実行する上では比較的重い動作であり、unbufferd I/O の場合、内部バッファを使用しずに直接ディスクに対してファイル書き込みを行うため、都度システムコールが発生します。
そのため、 程度の数値を入力すると TLE します。
つまり、通常は比較的簡単に書くことができる fmt.Scan で問題なくても、膨大な量のデータを高速で受け付ける必要がある場合は、fmt.Scan だと遅すぎるわけです。
bufio.Scanner
では、bufio.Scanner の場合はどうなっているのか。
まず、Scanner の正体を知るために、bufio パッケージの Scanner 構造体を見にいきます。
Scanner は、改行で区切られたテキスト行のファイル等のデータを読み取るための便利なインターフェイスを提供します。 Scan メソッドを連続して呼び出すと、ファイルの「トークン」がステップスルーされ、トークン間のバイトがスキップされます。 トークンの指定は、SplitFunc 型の split 関数によって定義されます。 デフォルトの分割関数は、入力を行の終端を取り除いた行に分割します。 このパッケージでは、ファイルを行、バイト、UTF-8 でエンコードされたルーン文字、およびスペースで区切られた単語にスキャンするための分割関数が定義されています。 クライアントは、代わりにカスタム分割機能を提供する場合があります。
Scanner メソッドは、トークン によって、単語毎(スペース区切り)、行毎(改行文字区切り)に効率的に読み取ることができます。
また、トークンの指定は SplitFunc 型の split 関数によって定義することができるようです。
split 関数(無名関数)は以下のような定義になっています。
SplitFunc は、入力をトークン化するために使用される分割関数のシグネチャです。
SplitFunc 型に代入することができる関数として、以下の 4 つが定義されています。
これらの関数は、split 関数と Underlying Type が同一であるため、Go の特性の一つである Assignability によって代入することが可能になっています。
Assignability(代入可能性)に関しては、こちら の記事が分かりやすいかと思います。
加えて、Scanner メソッドは fmt.Scan と異なり、内部にバッファを持っています。
これを利用することで、split フィールドに定義されたトークンに従ってバッファに格納されたバイト列毎に I/O 処理(Bufferd I/O)を行うため、fmt.Scan よりも高速に動作することが可能になります。
スキャナーの作成は、NewScanner 関数によって行います。
デフォルトで作成されたスキャナーは、「行」をトークンとして、入力を受け付けるよう設定されています。
これを上述した split 関数に置き換えたい場合、Split メソッドを使用します。
実際に使用する場合
これを以下のような形式で受け付ける場合、
単語(空白スペース)毎に受け付けることで、高効率かつ高速に処理が可能になります。
速度比較
実際に以下のコードを使って、データの入力値を増やした時の、fmt.Scan と bufio.Scanner の読み込み速度を比較してみます。(本番環境を想定して、メモリを 512MB に制限して計測を行なっています)
| データ数 | fmt.Scan | bufio.Scanner |
|---|---|---|
| 10 | 0.000123s | 0.000023s |
| 100 | 0.000310s | 0.000025s |
| 1000 | 0.004084s | 0.000224s |
| 10000 (=) | 0.033157s | 0.000550s |
| 100000 (=) | 0.509994s | 0.006163s |
| 1000000 (=) | 3.771113s | 0.064092s |
| 2000000 (=) | 7.210549s | 0.142498s |
| 3000000 (=) | 10.357201s | 0.190407s |
| 4000000 (=) | 13.958481s | 0.253358s |
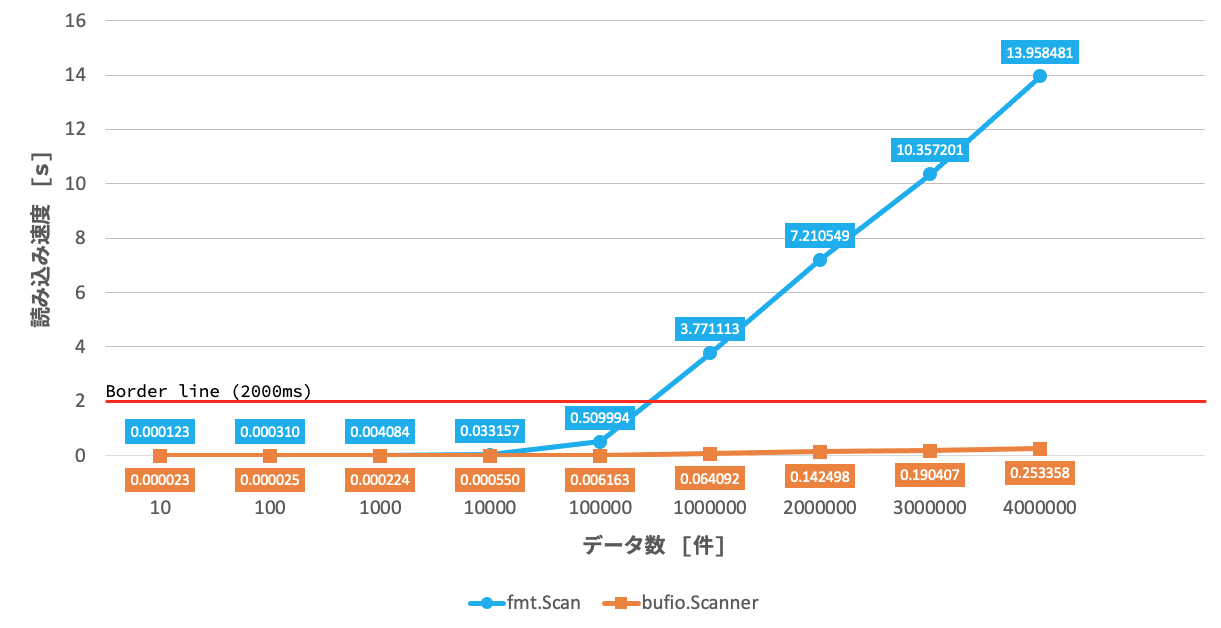
データ件数が 1 万()件ぐらいまでは、双方でほぼ同じ読み込み速度であるため、簡単に書ける fmt.Scan の方が良さそうです。
しかし、10 万()件を超えたあたりから fmt.Scan が明らかに遅くなってきます。
今回、レギュレーションとして設定されている『メモリ上限:512MB / 実行タイムアウト:2000ms』において、100 万()件を読み込む時点で 3 秒以上も掛かるようでは、300 万()件を読み込んで処理する際に TLE が発生するのも納得です。
一方、bufio.Scan はデータ件数が増えた場合にも、読み込み速度が劣化しにくく安定して使えるため、膨大な量のデータを読み込むことが可能になります。
結論
これらのことから、① では、fmt.Scan によって入力を受け付ければ良く、② では、bufio.Scanner を使用する必要があるということになります。
まとめると、
- 速度を気にしなくても良い場合
fmt.Scan
- 膨大なデータ()を高速に読み込む必要がある場合
bufio.Scanner
- また、今回は触れなかったが、行数が多い場合()
bufio.ReadLine
という感じになるかと思います。