Google Cloud を活用した Platform Engineering の実践
- Authors
- Name
- ごとれん
- X
- @ren510dev


目次
- 目次
- はじめに
- Google Cloud Handson Seminar とは
- スケジュール
- 参加のモチベーション
- GKE で始める Platform Engineering - 入門編
- プラットフォームエンジニアリング
- DevOps
- Plaform Engineering ≠ PaaS
- プラットフォームエンジニアリングの原則
- Platform Engineering の導入が重要な理由
- 開発者への舗装された道路の提供
- Golden Path による生産性・安全性の向上
- 組織に合わせた Golden Path の提供
- チームスコープでの管理(GKE Fleet)
- GCP 上での Platform Engineering 実装例
- Platform Engineering の実践
- Google Cloud Workstations
- Day 1 まとめ
- GKE で始める Platform Engineering - 実践編
- DORA:DevOps Research and Assessment
- DORA 4 つの指標 - Four Keys
- CI/CD
- GCP における CI/CD パイプラインの例
- CI と CD の分離
- GitOps
- GitOps における CI と CD の分離
- CI と CD の分離によるメリット・デメリット
- GCP のマネージドサービス
- Cloud Build
- Code Deploy
- Cloud Deploy によるデプロイの流れ
- デプロイフローの例
- GCP におけるオブザーバビリティ
- Cloud Logging
- Cloud Logging のアーキテクチャ
- GKE のロギング
- GKE のログ転送の仕組み(デフォルト構成)
- Fleet ロギング(GKE Enterprise のみ)
- モニタリング
- ワークロードメトリクス
- GMP:Google Managed Prometheus
- GMP の特長
- クエリ
- Day 2 まとめ
- GKE で始める Platform Engineering - セキュリティガードレール編
- クラウド活用におけるガードレールの必要性
- 開発者に求められる安全なプラットフォーム
- Kubernetes(GKE)環境に潜むリスクの把握
- コンテナイメージ脆弱性への対策
- サプライチェーンに潜む脆弱性
- Log4Shell
- サプライチェーン攻撃に対する課題
- Software Delivery Shield
- 依存関係とアーティファクトのセキュリティ改善
- 実行時のセキュリティ分析
- GKE Fleet Rollout Sequencing
- クラスタアップグレードと脆弱性情報の自動通知
- ワークロード構成スキャン
- GKE Sandbox
- Container-Optimized OS(COS)
- GKE Threat Detection
- Security Command Center(SCC)
- Container Threat Detection(KTD)
- ハンズオン
- Day 3 まとめ
- セミナーに参加してみて

はじめに
5 月 28 - 30 日(3 Days)Google Cloud が開催する Platform Engineering のハンズオンセミナーに参加してきました。 今回のセミナーは Google Cloud カスタマーエンジニアの公演を聞きながら、Google Kubernetes Engine(GKE)を活用して実践的に Platform Engineering を学ぶコンテンツとなっており、座学とラボの両方が実施されました。
今回のブログでは、振り返りも兼ねて 3 日間の参加レポートをまとめたいと思います。
Google Cloud Handson Seminar とは
Google Cloud Handson Seminar は Google Cloud 主催の元、年に数回開催されており、様々なコンテンツが用意されています。
Google Cloud Handson Seminar では、アプリケーション開発から AI・機械学習まで幅広いテーマのハンズオンを提供しています。 初心者から上級者まで、レベルに合わせた内容となっており、経験豊富な講師陣が分かりやすく解説します。 実際に手を動かしながら学ぶことで、クラウドスキルを効果的に習得できる絶好の機会となっています。
スケジュール
- 5 月 28 日(1 日目):GKE で始める Platform Engineering - 入門編
- Platform Engineering における "ゴールデンパス" と "ガードレール" とは
- 5 月 29 日(2 日目):GKE で始める Platform Engineering - 実践編
- GCP を活用した "ゴールデンパス" の整備および実践
- 5 月 30 日(3 日目):GKE で始める Platform Engineering - セキュリティガードレール編
- GCP を活用した "ガードレール" と "セキュリティ" の整備および実践
参加のモチベーション
これまで Platform Engineering について明確な言語化ができずにいたので、この機会にしっかりとキャッチアップし、自分の中で定着させたいという狙いがありました。 そこで、以下の項目についてキャッチアップすることを目的に、本セミナーへの参加を決意しました。
- Platform Engineering とは。
- Platform Engineering において心がけることとは。
- GKE(Google Platform)を用いてどのように Platform Engineering を実現するのか。
- 所属組織・自身の業務ではどのように活かせるか。
GKE で始める Platform Engineering - 入門編
本ハンズオンセッションでは Google Kubernetes Engine(GKE)を基盤とした開発者向けプラットフォーム開発の基本的なプラクティスを学ぶことができます。 Platform Engineering の基本的なプラクティスから Platform as a Product をベースにしたプラットフォーム開発の具体的な手法、また基盤となる GKE の概要についてハンズオン形式で習得します。 これから Platform Engineering プラクティスの導入を検討されている方々に最適な内容となっています。 ※本セッションはコンテナ・Kubernetes の基本的な知識をお持ちの方を対象としています。
Day 1 では、主に GCP を用いた Platform Engineering の基本的なプラクティスから Platform as a Product をベースにしたプラットフォーム開発の具体的な手法について学びました。
また、GKE の Fleet と呼ばれる機能や、Cloud Workstations を活用したチームスコープでの Platform Engineering をハンズオンで実践しました。
プラットフォームエンジニアリング
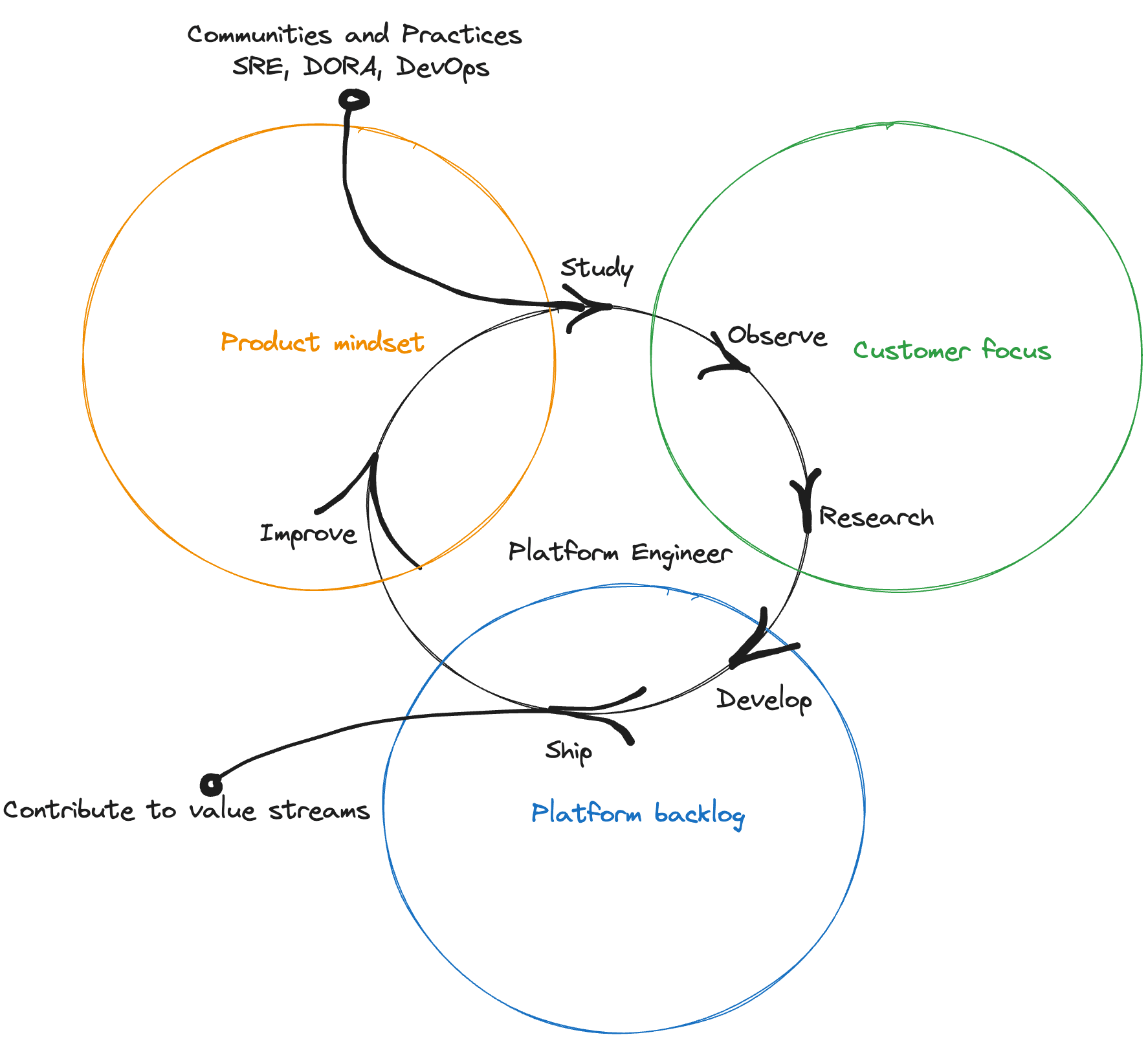
- 組織において 有用な抽象化 を行い、セルフサービスインフラストラクチャを構築するアプローチ
- 散乱したツールをまとめ、開発者の生産性 を高める効果がある
- 開発者が体験する日常的な困難を解消し、行きすぎた責任共有モデルが引き起こす学習の手間を抑制する狙いがある
- 開発者が体験する日常的な困難を解消:ツール不備, デプロイの手間, ドキュメントの整備不良, ...
- 行きすぎた責任共有モデル:サービスを稼働させるプラットフォームとアプリケーションの密集度合い
そもそも、プラットフォームエンジニアリングとは何なのか、
『開発者が日々の開発を滞りなく進めるために必要なプラットフォーム(ツール類)を整備して自律的なインフラストラクチャ・運用体制を確立できる環境を整備すること(開発者に対するエンジニアリング)』 だと思っています。
属人化やサイロ化という言葉があるように、開発者のアイデアやプロダクトをユーザに届けるまでには、多くの開発上の障壁があり、マイクロサービスをはじめとする近年の複雑なサービスアーキテクチャの上ではこれらの課題がさらに浮き彫りになってきます。

プラットフォームエンジニアリングの最も重要なポイントは、インフラエンジニアや SRE が積極的に介入しなくとも、開発者が自律的、かつ滞りのない開発と運用のサイクルを回せるように、ナレッジの負荷を下げるためのツールを提供することではないかと思います。
インフラストラクチャとサービスとの間を取り持つ、抽象化されたレイヤを整備することで、開発者の生産性を高めることが、プラットフォームエンジニアにとっての一番の使命になります。 念頭に置かなければならないのは、サービスと同じで、単にプラットフォームを整備して終わり ではなく、そのツールを開発者(エンドユーザ)に使ってもらえて初めて意味があるということです。
プラットフォームエンジニアは、アプリケーションからインフラまでの高度な技術力と知見を持つことが大前提であり、加えて『ドキュメンテーション能力』や『開発組織全体を俯瞰して見れる視野の広さ』、『浸透力』が要求されます。
DevOps
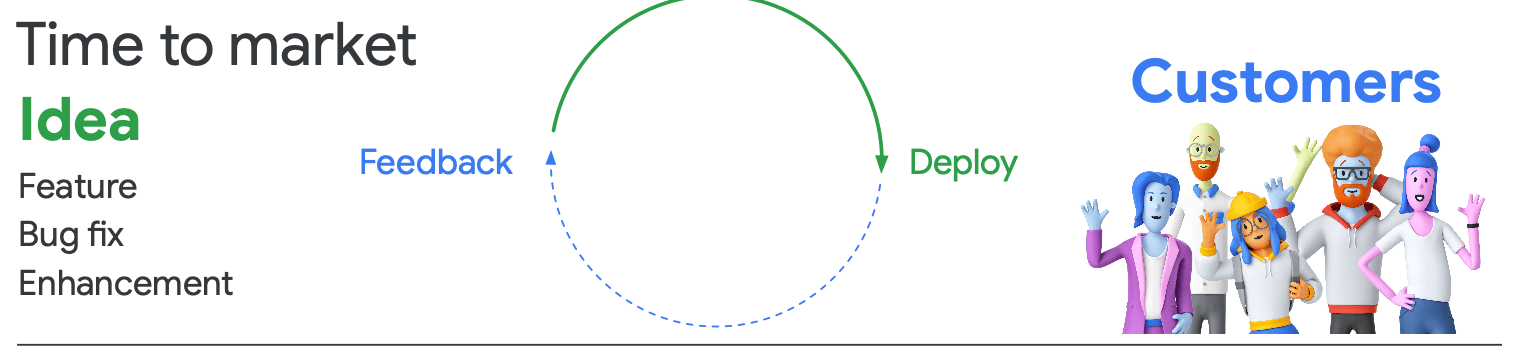
- ソフトウェア開発(Dev)と運用(Ops)のプロセスを統合し、協調して効率的に作業を進めるためのプラクティス、ガイドライン、カルチャーを指す
- アイデアをマーケットに投入するまでの時間を短くする
- カスタマーからのフィードバックを早く得る
- それに対してすぐにレスポンスを返す
- 参考:CI/CD Metrics with GSM Framework
DevOps はプラットフォームエンジニアリングを実践する上で最も基本的なプラクティスの一つです。 また、CI/CD パイプラインの整備は DevOps を実現するための手段の一つです。
CI/CD や DevOps、SRE やプラットフォームエンジニアリングが相互に作用し合う事で、開発者が自律的に運用できる環境を整えられるようになります。
Plaform Engineering ≠ PaaS

- Plaform Engineering
- 開発チームに 舗装された道路 を提供できるようにチームを強化し、プラットフォームをプロダクトとして提供 する
- これにより、ユーザ(開発者)のニーズに合わせて プラットフォームが進化し続けられるようにする
プラットフォームエンジニアリングの原則
- 開発者はインフラを構築するために 最小限の実行可能なプラットフォーム を使用する
- プラットフォームはプロダクトであり、プロダクトマネージャが割り当てられるべき
- プラットフォームチームは複雑なインフラに纏わる ツールチェーン と 抽象化に責任をもち、ビルドを実施する
- プラットフォームは、エンドツーエンドの 舗装された道路 を提供する
プラットフォームエンジニアリングでは『Platform Enigneering is not PaaS』が原則です。
PaaS は『プラットフォームをサービスとして提供する』というのが使命で、プラットフォームをどのように活用するのかは開発者自身に委ねることになります。
一方、プラットフォームエンジニアリングを実現する上で、プラットフォームエンジニア自体は PaaS を使いこなせなくてはならないのですが、その上で開発者が、よりプラットフォームを使いやすくなるように『舗装された道路』を整備してあげることが使命となります。
プラットフォームエンジニアリングは、PaaS と開発者の間で行われるエンジニアリングという位置付けになるかと思います。 つまり、サービス運用に伴うインフラストラクチャ(クラウドプラットフォーム)を提供する PaaS とは別の概念であるということです。
Platform Engineering の導入が重要な理由
- 開発者の認知負荷を軽減し、燃え尽き症候群のリスクも軽減
- アプリケーション開発を加速し、低コストで市場投入までの時間を短縮
- 組織に合わせたガードレールを早期に取り入れ、安全性を向上
開発者への舗装された道路の提供
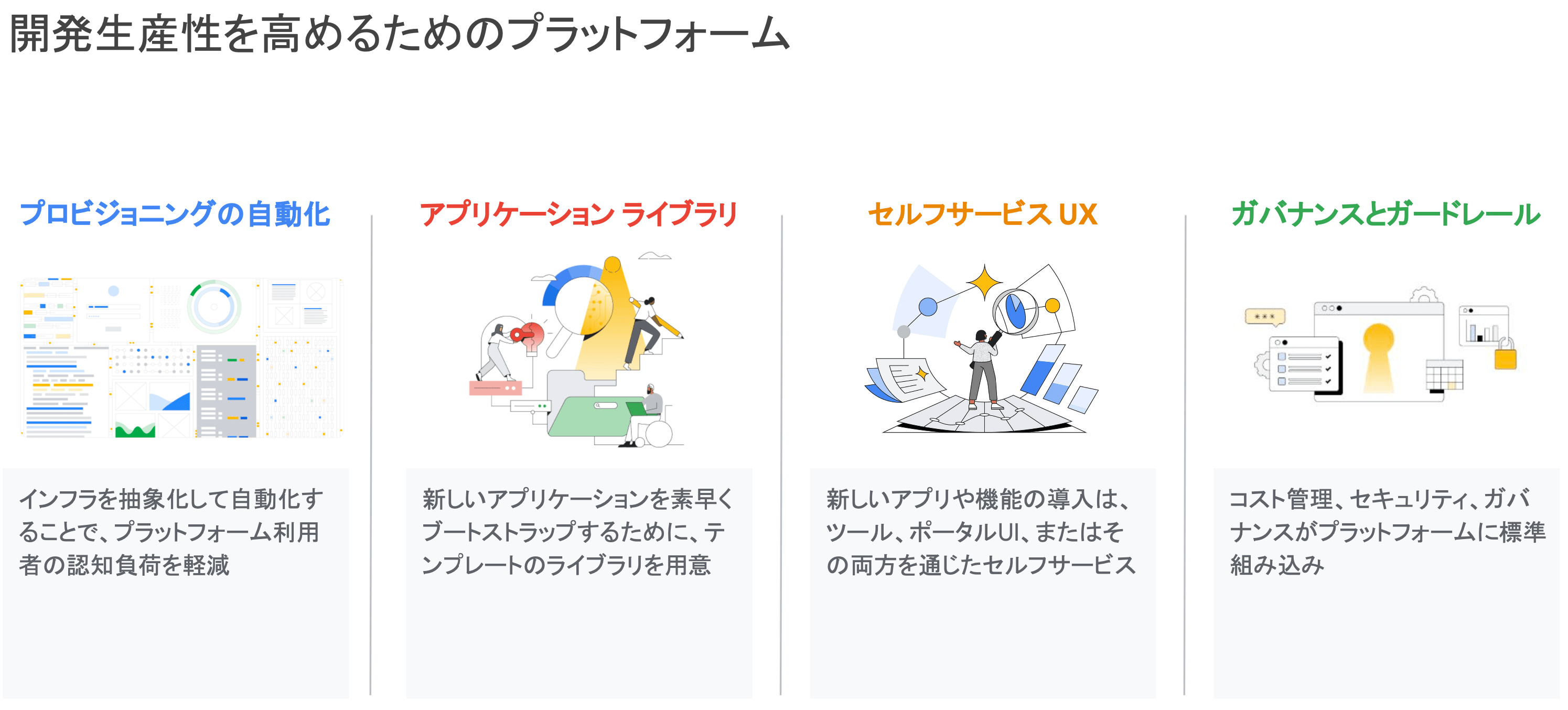
- プロビジョニングの自動化
- インフラを抽象化して自動化することで、プラットフォーム利用者の認知負荷を軽減
- アプリケーションライブラリ
- 新しいアプリケーションを素早くブートストラップする(稼働させる)ために、テンプレートのライブラリを用意
- セルフサービス UX
- 新しいアプリや機能の導入は、ツール、ポータル UI、またはこれら両方を通じたセルフサービス
- ガバナンスとガードレール
- コスト管理、セキュリティ、ガバナンスがプラットフォームに標準組み込み
プラットフォームエンジニアに課せられる 4 つの使命・ミッションとなります。 どれも必要不可欠な要素ですが、個人的には、特に『ガバナンスとガードレール』の整備というのが最も重要だと思っています。
なぜそう思うのかというと、この要素だけはサービス開発を進める上で最も厳かになりがちだからです。 例えば、プロビジョニングの自動化やアプリケーションライブラリは多くの組織で実践されており、これがなければ開発自体に支障を来たすため、比較的整備が行き届いていることは多いのではないでしょうか。 また、セルフサービス UX においても、サービス運用に伴う管理面や、フィーチャーフラグの切り替え等を行う上では整備されていることが多いと思います。
一方で、『コスト』、『セキュリティ』、『ガバナンス(開発ポリシ)』といった開発に伴う副次的な要素に関しては、リーダーや EM 等の上位レイヤのエンジニアは意識していても、プレイヤにとってはサービスに比べて優先度が低くなりがちです。
プラットフォームエンジニアは、これらの要素にも着目し、プラットフォームエンジニアリングの一環として舗装された道路を整備するために務めなければなりません。
Golden Path による生産性・安全性の向上
- Golden Path
- 迅速なプロジェクト開発に役立つコードと機能のテンプレート
- 開発(者)の生産性
- 速度 と 安全性の確保 のためのガードレール
- コードとしての自動ポリシ管理
- カナリアデプロイメント
カナリアデプロイメント
- ソフトウェアリリース戦略の一つ
- 新しいバージョンのアプリケーションやサービスを段階的に本番環境にリリースする手法
- この手法では、まずごく一部のユーザに新しいバージョンを提供し、問題がないことを確認した後に、徐々にその範囲を広げる
- 低リスク:初期の段階で新バージョンを限られたユーザに提供するため、問題が発生した場合の影響範囲が小さく抑えられる
- 迅速なフィードバック:新バージョンに対するユーザのフィードバックを早期に収集し、問題やバグを迅速に修正できる
- 段階的拡張:新バージョンが安定していることが確認できたら、徐々に提供範囲を広げていくことができる
先ほどから何度も登場している "舗装された道路" とは何なのか。
このセミナーでは、『迅速なプロジェクト開発に役立つコードと機能のテンプレート』と紹介されており、ゴールデンパス(Golden Path) と呼ばれています。
車に乗る時ガタガタの道では運転しずらいですよね。 アプリケーションの開発現場も同じで、開発と運用の DevOps サイクルが不整備な状態では安全に走行することはできませんし、そこにいる開発者も不快感を覚えます。

プラットフォームエンジニアリングはゴールデンパスを以て成立します。
組織に合わせた Golden Path の提供
- 組織やチームによって求める抽象度は異なるため、ユーザにヒアリングを行い適切な Golden Path を提供
- プラットフォーム上に同じようなサービスをいくつか稼働させるようになったとき
- 各チームと協力して共通パターン、効果的なパターンを突き詰める
- 成功を測定してイテレーション(反復)を回す
- 新サービス数等の定量的測定
- 社内開発者へのアンケート等の定性的測定
プラットフォームが具体的に何を指すのかは組織によって異なってきます。 サービスを創り出す上で市場調査をするのと同じように、プラットフォームエンジニアは開発者を対象として、課題やニーズをヒアリングします。 また、単に作って終わりではなく、展開とフィードバックのサイクルを回し、成果を定量的に測定できるようにします。 開発者生産性(Developer Productivity)の文脈と重複する部分もありますが、アンケート等の定性的なフィードバックも必要になります。
振り返ってみると、プラットフォームを作ったは良いが、実際にはほとんど使われておらず、ゾンビ化してメンテナンスコストだけが嵩み、後には技術負債として文鎮化する、といったことはないでしょうか。 プラットフォームエンジニアリングにおける、開発者へのヒアリングは、ゴールデンパスを整備したにも関わらず役に立たなかったという事態を極力無くすためです。
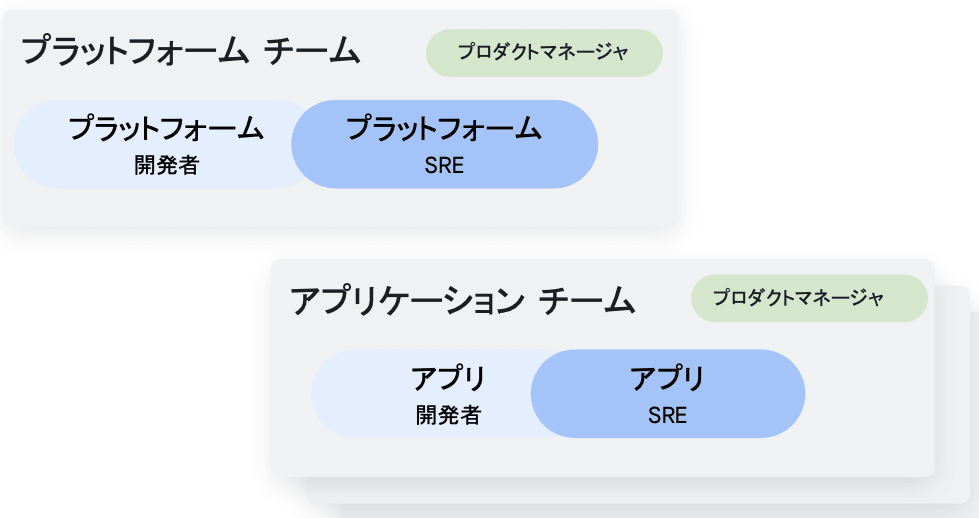
チームスコープでの管理(GKE Fleet)
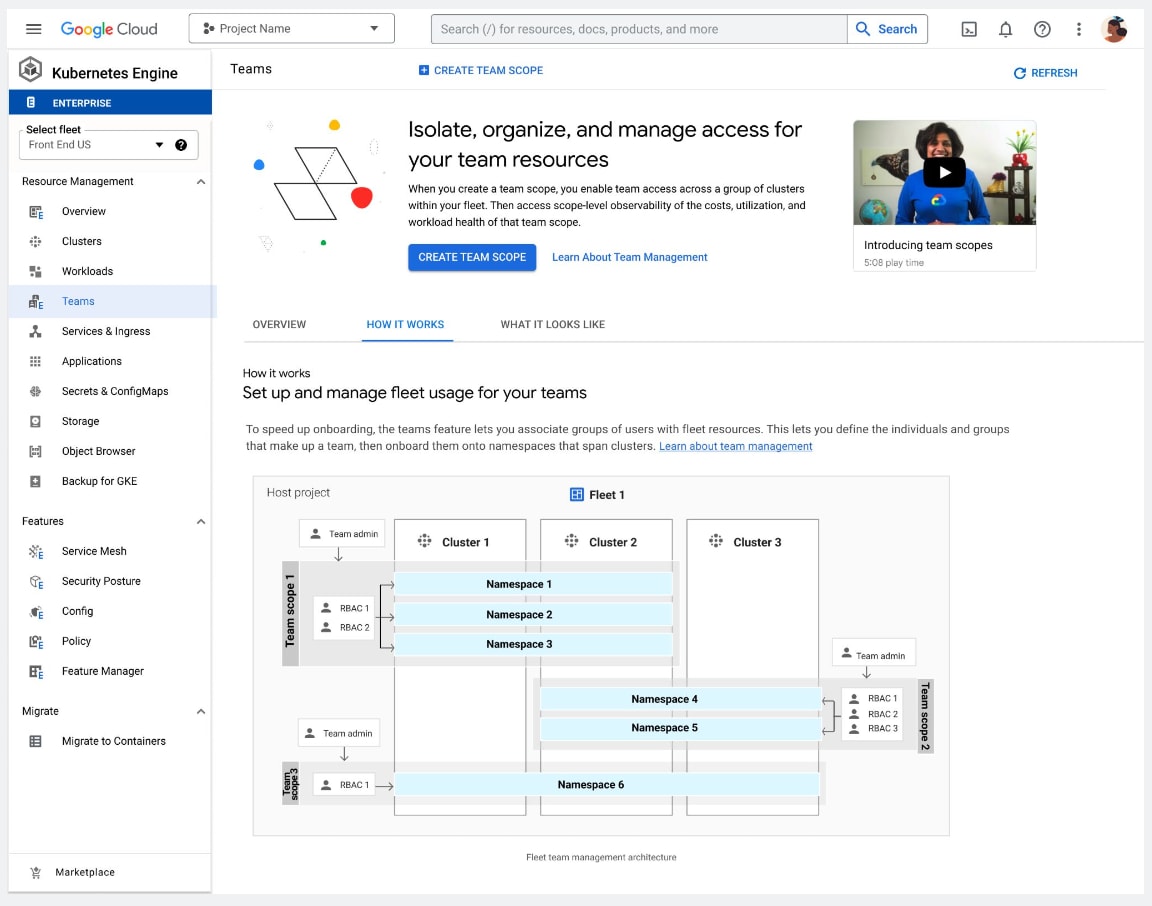
- 本番環境に対応したサービス
- アプリケーションチームの管理用
- チーム管理 API
- アクセス、クォータ、セキュリティ、ポリシのサポート
- チームのオンボーディングと可視性のための新しい UI
Fleet とは、複数の GKE クラスタと他のリソースを論理的に編成するための Google Cloud のコンセプトです。 Fleet を活用することによって、マルチクラスタ機能の使用と管理、複数のシステム間での一貫したポリシの適用が可能になります。
今回、ハンズオンで実際に触ってみましたが、ネームスペースよりも遥かに高度な制御が可能で、特にマイクロサービスと GKE を採用している開発組織にとっては非常に重宝する画期的なマルチテナント機能だと思います。
ただし、Fleet は、GKE Standard edition では単一の Fleet(通常のクラスタと同じ)のみしか提供されていないため、GKE Enterprise edition へのアップグレードが必要となります。高い...!
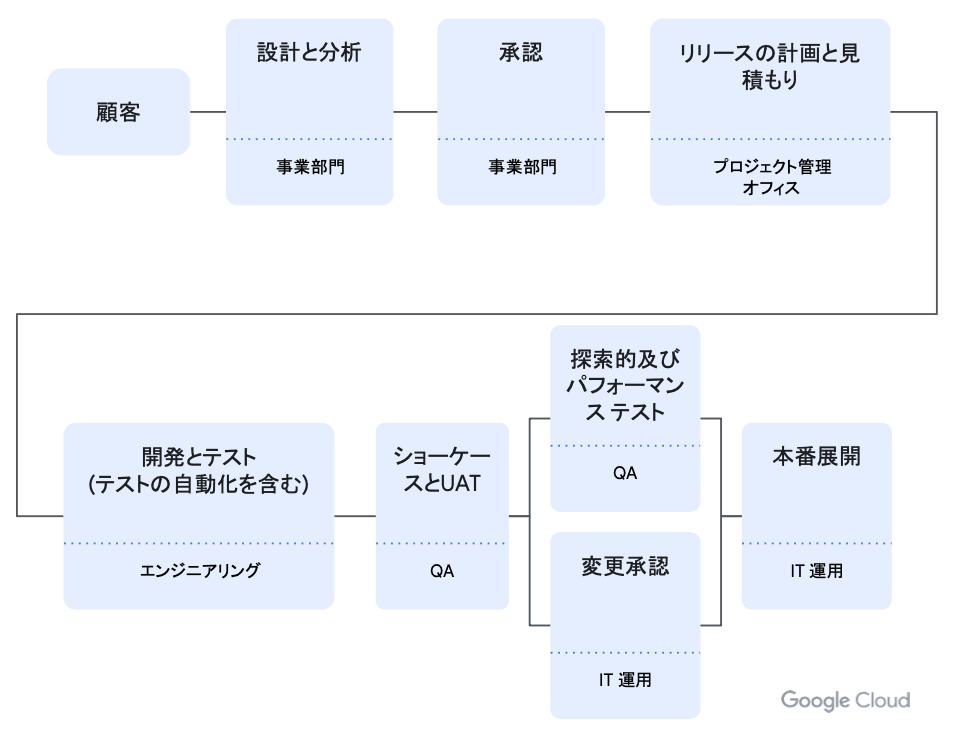
GCP 上での Platform Engineering 実装例
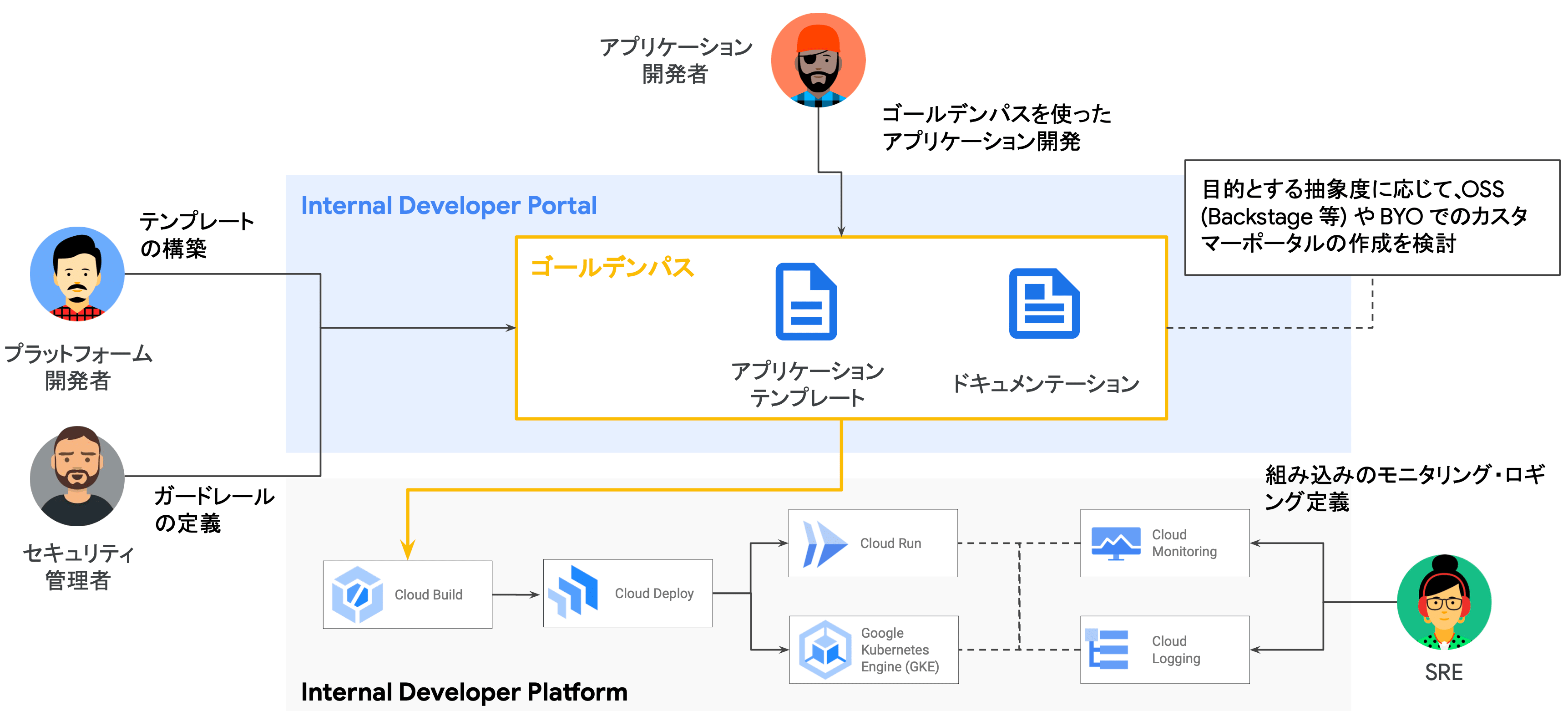
Google Cloud を活用した Platform Engineering の一例として、Code Build や Code Deploy(コードファミリの類)を用いたマネージドコンテナオーケストレーションプラットフォームへの CI/CD、Cloud Monitoring や Cloud Logging を活用したオブザーバビリティの整備が挙げられます。
図で紹介されているアプリケーションテンプレートやドキュメンテーションといったゴールデンパスを整備するツールの一つに、Cloud Workstations という Google Cloud のサービスを活用することができます。(後述)
Platform Engineering の実践
- ユーザ理解
- ユーザ(開発者)の需要、思考、傾向等を理解することが最初の一歩
- ユーザ(開発者)へのインタビュー
- プラットフォーム開発への参加
- プラットフォームをプロダクトとして扱う
- Platform as a Product
- プラットフォームを プロダクト、ユーザ(開発者)を 顧客として扱う
- プロダクトマネージャをアサイン
- ユーザの理解
- インタビュー
- ペルソナの設定
- ユーザストーリーの作成
- プラットフォームのユーザを顧客として捉え、プロダクトと同じように管理
- 適切な問題から開始
- ペルソナ(プロダクトを提供する対象者)の設定
- ユーザストーリーの作成
- ユーザ中心設計のプロダクト開発と同様にストーリー形式でバックログを管理
- Who / What / How の Acceptance Criteria(合否基準)を定義
- JIRA 等のチケットツールの活用
- ペルソナ(プロダクトを提供する対象者)の設定
ペルソナ設定の例:
【ニーズ】
- Taro(開発者のペルソナ)は、コードの変更があった場合に自動でビルドとテストが行われ、品質を保証しながら迅速に本番環境にデプロイできる CI/CD パイプラインを利用したい
【目的】
- 手動でのエラーを減らし、開発チームの生産性を向上させたいから
【Acceptance Criteria(合否基準)】
- 開発者がコードリポジトリに変更をコミットすると、自動でビルドが開始される。
- ビルドが成功すると、自動でユニットテストと統合テストが実行され、問題がないことが確認される。
- テストが成功すると、コードは自動でステージング環境にデプロイされ、最終承認後に本番環境へと自動でロールアウトされる。
実行可能な最小限のプラットフォーム(TVP:Thinnest Viable Platform)を採用
- 最小機能のプラットフォームを開発
- ユーザのフィードバックを受けた際に追加開発を行う
- 実行可能な 最小限のプラットフォーム(Thinnest Viable Platform)
- 完全なセルフサービスポータルの実現等、最初から巨大なものを作らない
- 組織によって価値となるものは異なる - 例:CI/CD パイプラインによるデプロイ
- 例:整備されたドキュメント群によるプラットフォームの活用方法
- 例:アプリケーションのテンプレート、ライブラリ、マニフェスト等の公開
- この中のいずれかだけでも良い
先でも述べた通り、プラットフォームエンジニアリングはユーザ・開発者へのヒアリングから始まります。 ペルソナを立て、適切な問題把握から開始し、Acceptance Criteria(合否基準)も設定します。 これが実施されていないと、後続の開発・整備・浸透のプロセスがあやふやになり、最終的に意味をなさないツールが誕生してしまう可能性があるからです。
また、サービスと同じくプラットフォームエンジニアリングでは、プラットフォームをプロダクトとして扱う Platform as a Product を実現します。 この文脈では、ユーザは開発者、プロダクトはプラットフォームとなり、ベストプラクティスに従えば、PM(Product Manager)もアサインすべきとされています。
プラットフォームの開発に当たってはいきなり大きなものを作るのではなく、最小限のプラットフォーム(TVP:Thinnest Viable Platform)原則 に基づき、フィードバックを受けながら段階的に成長させます。
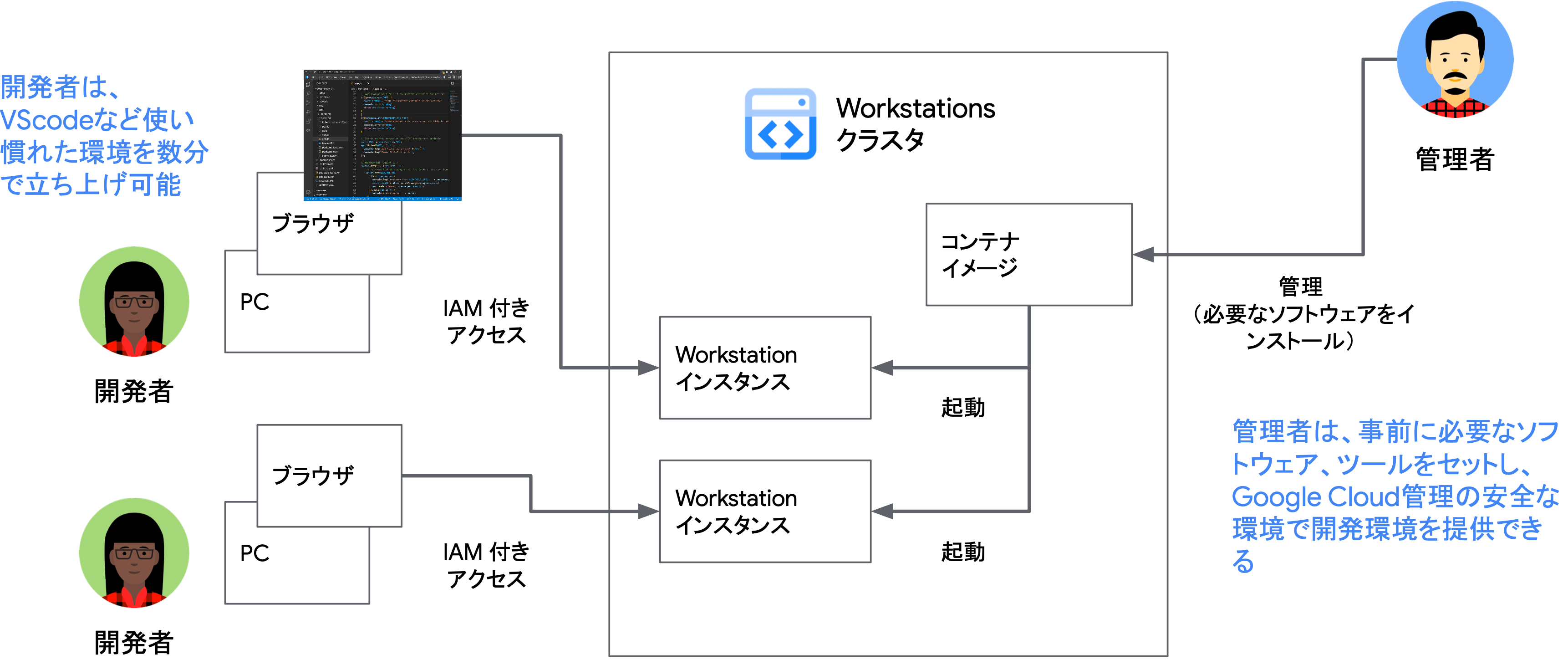
Google Cloud Workstations
- Google Cloud ユーザのためのマネージドな開発環境(VSCode のような IDE)
- 開発チームに共通する IDE 関連の課題(例)
- 開発環境のセットアップ
- 新/リモートメンバーの環境準備
- 開発メンバーが利用するハイスペックなマシンのコスト
- セキュリティ対策 / 情報流出を防ぐためのガードレール
- ローカルに保存されているソースコードの管理
- 開発者のローカル端末のセキュリティ対策
- 開発者の生産性
- プライベートなネットワーク環境で開発
- ビルドに時間がかかる
- アプリケーションが必要とする資材の複雑化
- 開発環境のセットアップ
- 開発環境の構築の迅速化 と セキュリティレベルの向上 を同時に実現
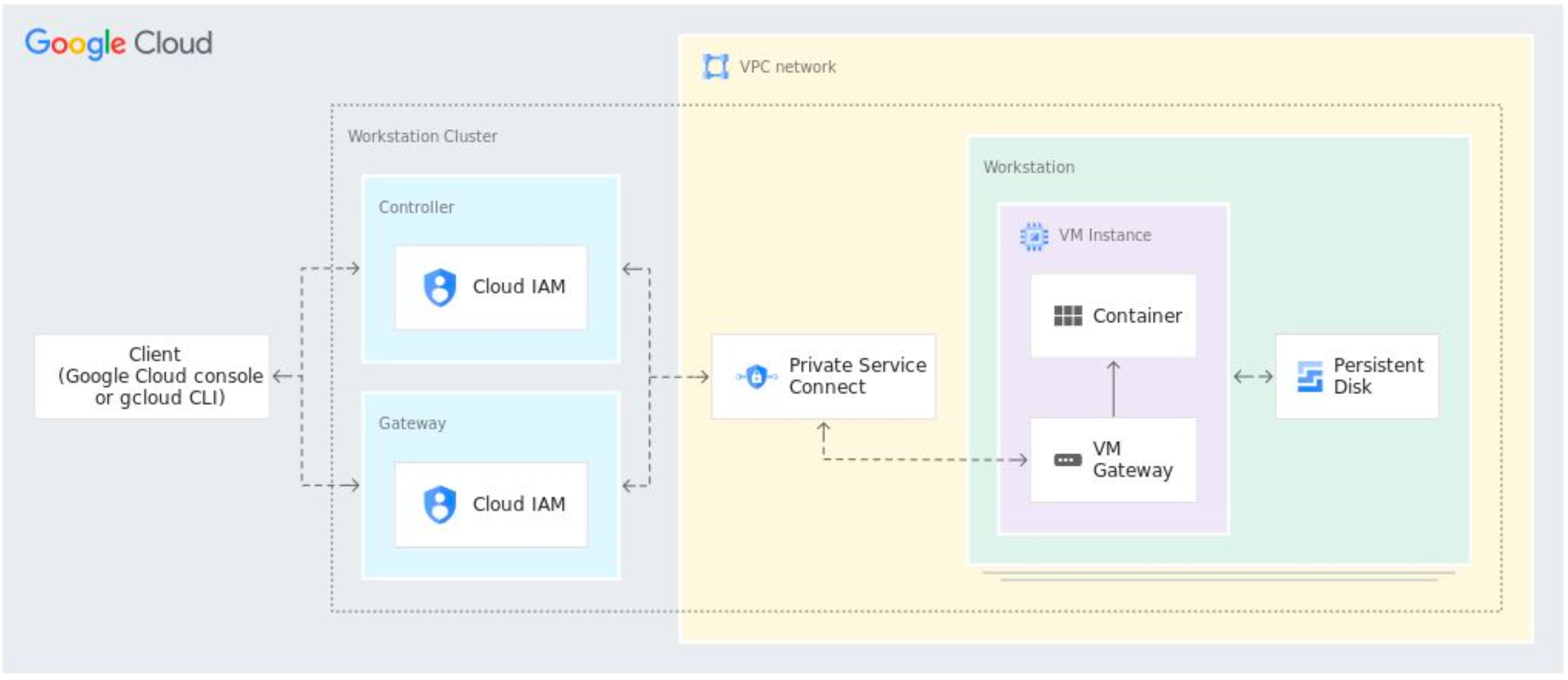
- アーキテクチャ
- ポイント
- エンタープライズ対応
- フルマネージド
- カスタム仮想マシン
- VPC サポート
- コンプライアンスをカバー
- セキュリティガードレール
- 厳選されたアクセスルール
- ロギング / 監査
- アップデート適用の強制
- 分離された開発環境
- カスタマイズ可能
- カスタムイメージ
- 複数のエディタ対応(IntelliJ, JupyterLab, ...etc.)
- ローカル / リモート IDE 連携
- サードパーティ DevOps ツールのサポート
- エンタープライズ対応
Cloud Workstations は Visual Studio Code やその他の IDE のような感覚で使用できるフルマネージドな統合開発プラットフォームツールです。 プラットフォームの管理者は、開発者が使用するソフトウェアやパッケージをコンテナイメージとして配布します。
Workstations クラスタに対して、開発に必要となるツール群がインストールされ、テンプレートに沿った開発を行うことができます。 また、必要に応じて、パッケージを含んだコンテナイメージを配布することで、冪等性を担保して開発環境を拡張することができます。
Workstations は Cloud IAM 等の IDaaS とも統合されており、開発者の権限を適切に管理することが可能となっています。
セキュリティやガバナンス等、より厳格化された組織であれば、内製 IDE から Workstations に移行することで、Google Cloud の統一化されたマネージドサービスの恩恵を享受することができます。
Day 1 まとめ
- Plaform Engineering
開発チームに 舗装された道路 を提供できるようにチームを強化し、プラットフィームをプロダクトとして提供 する
- Velocity(速度)と Stability(安全性)→ Golden Path(舗装された道)と Guardrail(防護壁)
速度を出すために "舗装された道路" を整備し、ガードレールを設けることで安全性を高める ユーザ(開発者)のニーズに合わせて プラットフォームが進化し続けられるようにする
Day 1 入門編では、主に "プラットフォームエンジニアリングとは" について学びました。
プラットフォームエンジニアリングをどう実現するのかは組織によって変わってくると思いますが、一環して、開発者が開発と運用のサイクルを滞りなく回すために舗装された道路を整備することが使命になります。
プラットフォームツールが直接的にサービスの収益になりうるかは、開発者が如何にしてそのツールを活用し、生産性を向上させられているかが定量的に測定できて初めて意味をなすものになります。 単に技術で攻めるのではなく、組織を俯瞰し、戦略的かつ計画的に推進していく必要があるため、非常に高度なエンジニアリング力が問われる世界だと思いました。
GKE で始める Platform Engineering - 実践編
本ハンズオンセッションでは Google Kubernetes Engine(GKE)を基盤とした開発者向けプラットフォーム開発の実践的な手法を学ぶことができます。 GKE 上に構築した開発者向けプラットフォームの CI/CD パイプラインやモニタリングダッシュボードの実装、また GKE Enterprise の機能を活用したマルチテナント管理手法をハンズオン形式で習得します。
Day 2 では、DORA(DevOps Research and Assessment)や DevOps、CI/CD 等、Developer Productivity の側面からもプラットフォームエンジニアリングを学びました。 またラボでは、GKE をはじめとし CI/CD パイプラインやモニタリングの整備といった、GCP を用いた基本的な開発者向けプラットフォームの構築を実践しました。 CI/CD パイプラインには、Code Build と Code Deploy を使用し、マルチテナントベースのオブザーバビリティには Cloud Logging と Cloud Monitoring を使用しました。
DORA:DevOps Research and Assessment
- 2014 年より DevOps という軸で
- 学術的な統計解析手法を用いて 組織やチームを成功に導く能力やプラクティスを研究
- 能力やプラクティスから組織のパフォーマンスを予測して DevOps に関する調査・研究 をするチーム
- 実践から期待できる 成果 と、その成果に大きく寄与する 要因を分析
- DORA
- 2023 State of DevOps Report
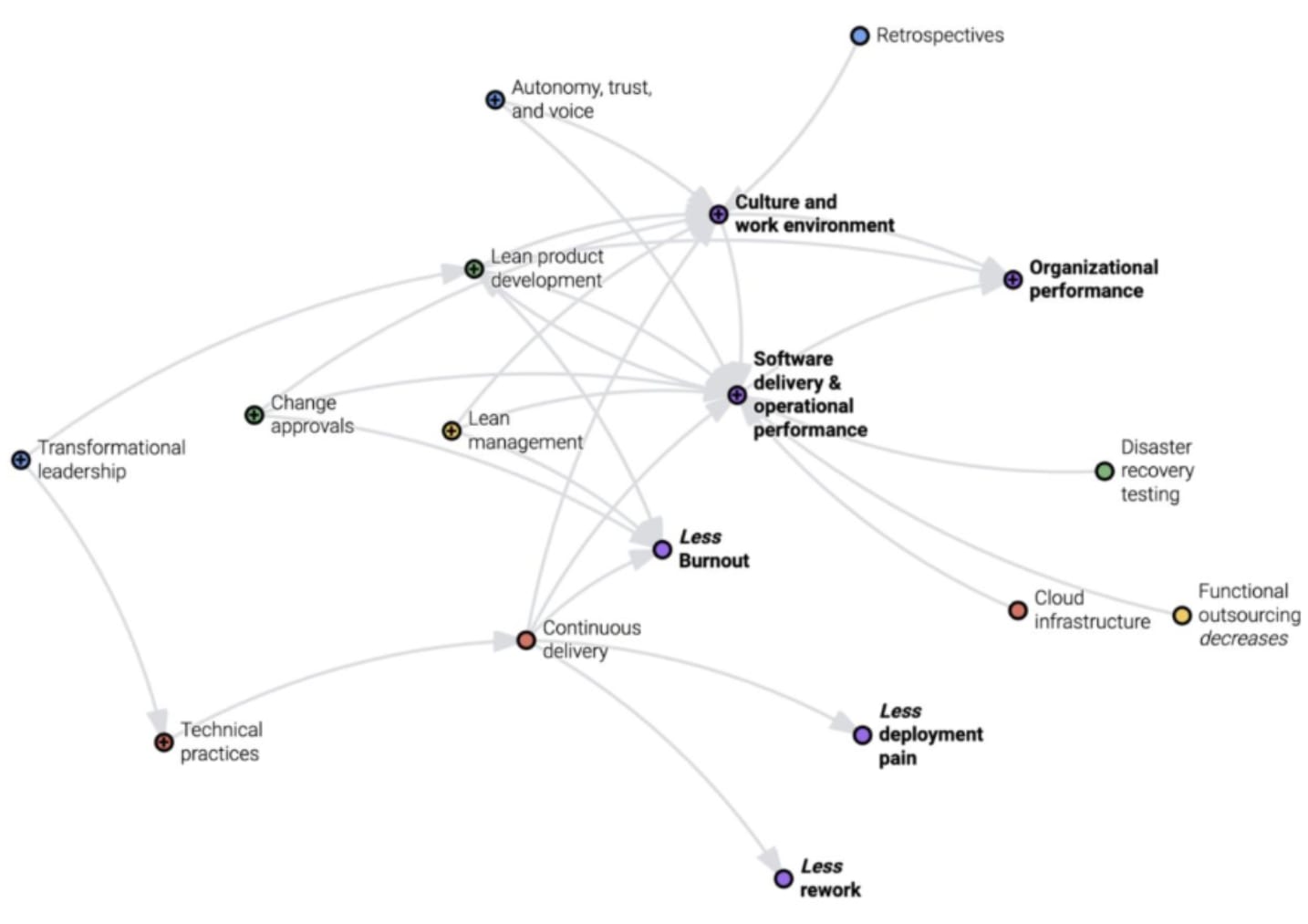
DORA(DevOps Research and Assessment)とは、ソフトウェア開発や運用に関するパフォーマンスを評価するための指標やベストプラクティスを提供する組織および、その研究に基づくフレームワークを指します。 DORA は、Google Cloud に属するチームによって設立され、DevOps の効果を高めるための実証済みの方法論を研究しています。
特に有名なのは DORA メトリクス(= Four Keys)と呼ばれる、ソフトウェア開発チームのパフォーマンスを測定するための 4 つの主要指標です。
これらの指標を用いることで、開発チームがどの程度効率的か、また柔軟性があるのかを定量的に把握することができます。
DORA 4 つの指標 - Four Keys
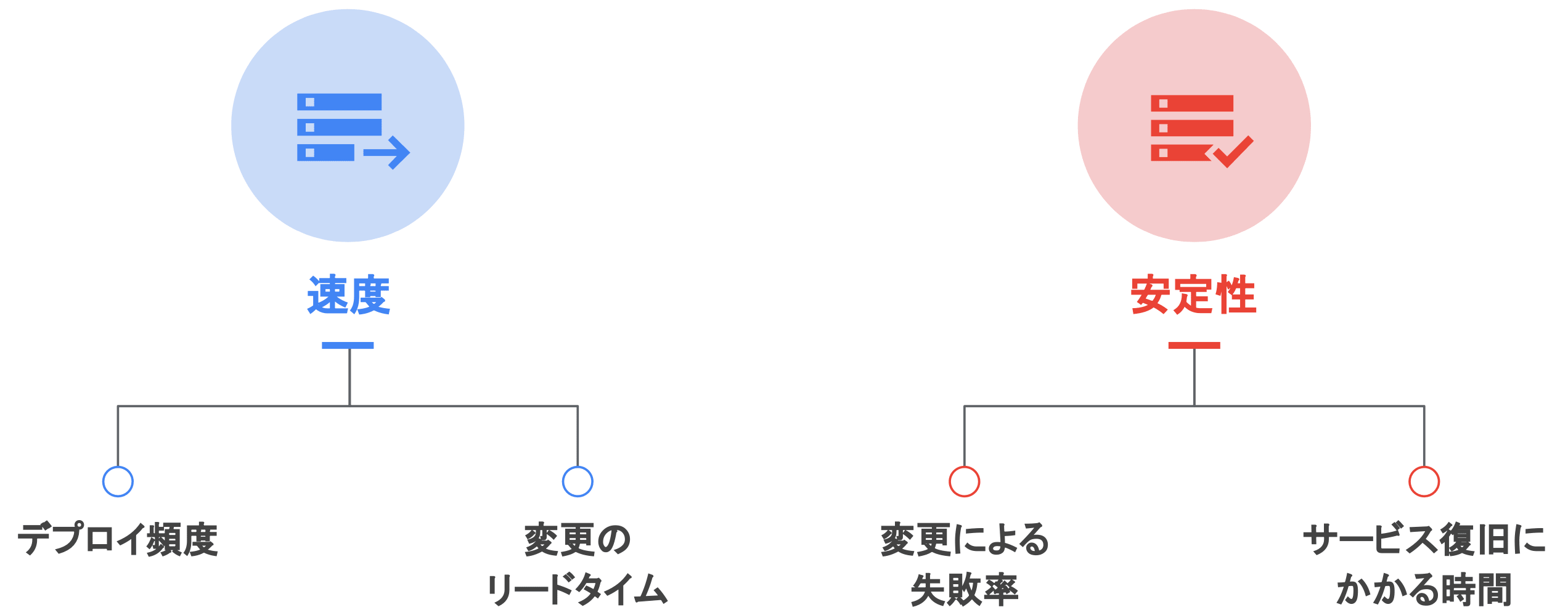
DORA の 4 つの指標は Four Keys として知られており、ソフトウェアのデリバリと運用パフォーマンスは次の指標で観測することができる。
- 速度
- 変更のリードタイム(Lead Time for Changes)
- デプロイ頻度(Deployment Frequency)
- 安定性
- サービス復旧にかかる時間(Time to Restore Service)
- 変更による失敗率(Change Failure Rate)
- (信頼性)
DORA の 4 つの指標は大きく 『速度』 と 『安定性』 の 2 つに分類されます。 開発・運用サイクルにおいて速度は重要な指標ですが、速度だけを重視するあまり安定性を損なっては意味がありません。 デプロイや新機能を追加した際は、変更による影響(障害等)が発生することは少なくありません。 指標の中に『変更による失敗率』と『障害からの復旧時間』を含めることで、速度とともに安定性も両立して担保することが重要となります。
CI/CD
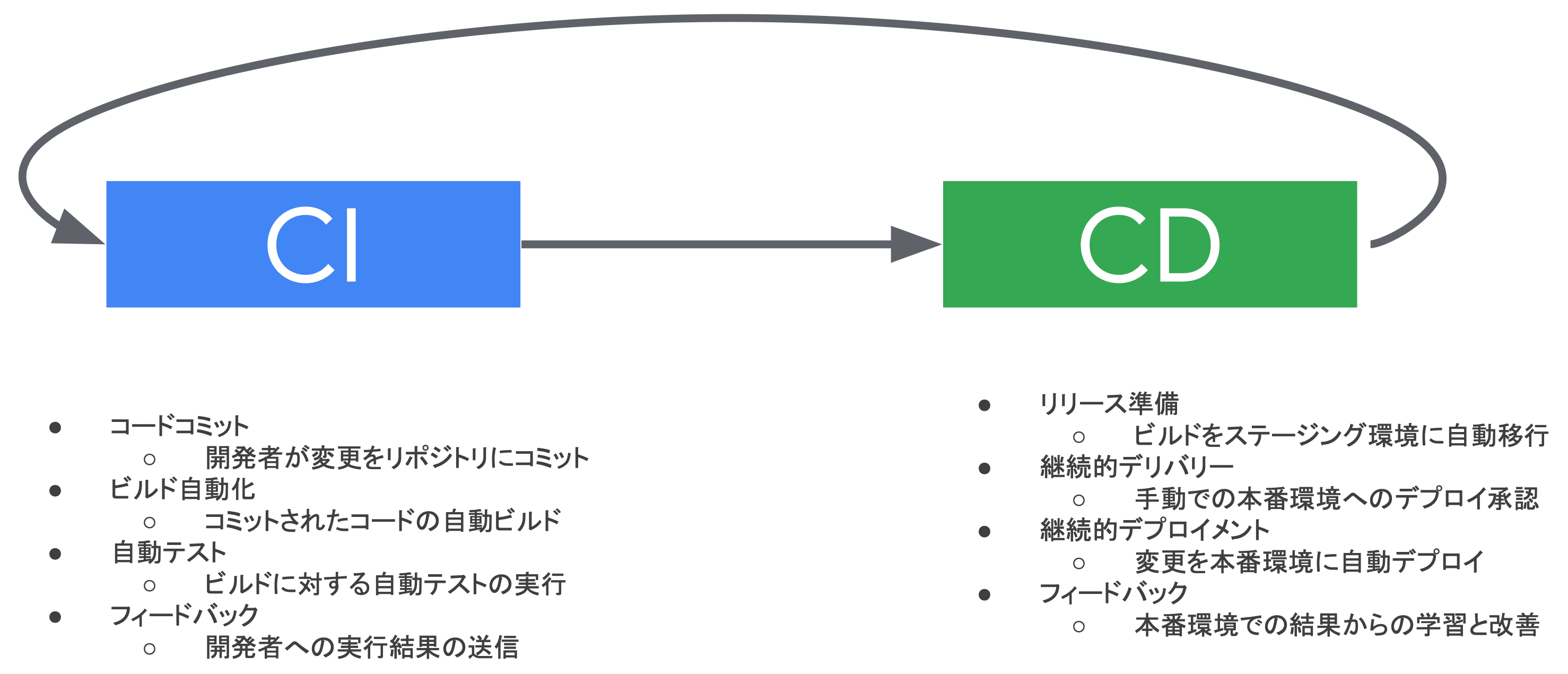
CI:Continuous Integration(継続的インテグレーション)
- 開発プロセスにおいて、チームメンバーが頻繁に(一日に数回以上)コード変更をメインリポジトリに統合する慣行
- 主な目的は、ソフトウェアの品質を向上させ、リリースプロセスを加速すること
- コードの変更がリポジトリにプッシュされる度に自動化されたビルドとテストが行われ、問題を早期に発見し修正することが可能となる
CD:Continuous Delivery(継続的デリバリ)
- ソフトウェアをリリース可能な状態に保ち、リリースプロセスを自動化する慣行
- 継続的デリバリでは、ビルド、テスト、リリースプロセスが自動化され、最終的なリリースの決定は人間が行うもの
CD:Continuous Deployment(継続的デプロイメント)
- 継続的デリバリをさらに一歩進めたもので、変更が自動的に本番環境にデプロイされるプロセス
- この場合、テストをパスしたビルドは、人間の介入なしに自動的に本番環境にリリースされる
Continuous Delivery と Continuous Deployment の相違点
特徴 Continuous Delivery(継続的デリバリ) Continuous Deployment(継続的デプロイメント) デプロイのタイミング 本番環境へのリリースは手動で行われる コードの変更が自動的に本番環境にリリースされる 手動介入の有無 手動の承認プロセスが含まれる すべてのプロセスが完全に自動化されている リスク管理 手動介入によりリスクが減少 リリースサイクルが短縮されることで問題の早期発見と解決が可能 CI/CD はソフトウェア開発の慣行であり、特に Kubernetes ベースの開発において重要
ゴールデンパスを整備する上で、CI/CD はほぼ必須です。 逆に、CI/CD が無い環境では、宣言的な構成に基づく運用が困難となったり、デプロイの属人化が発生したり、障害時の原因究明プロセスが複雑化したりと、非常に多くの問題が発生してきます。
GCP における CI/CD パイプラインの例
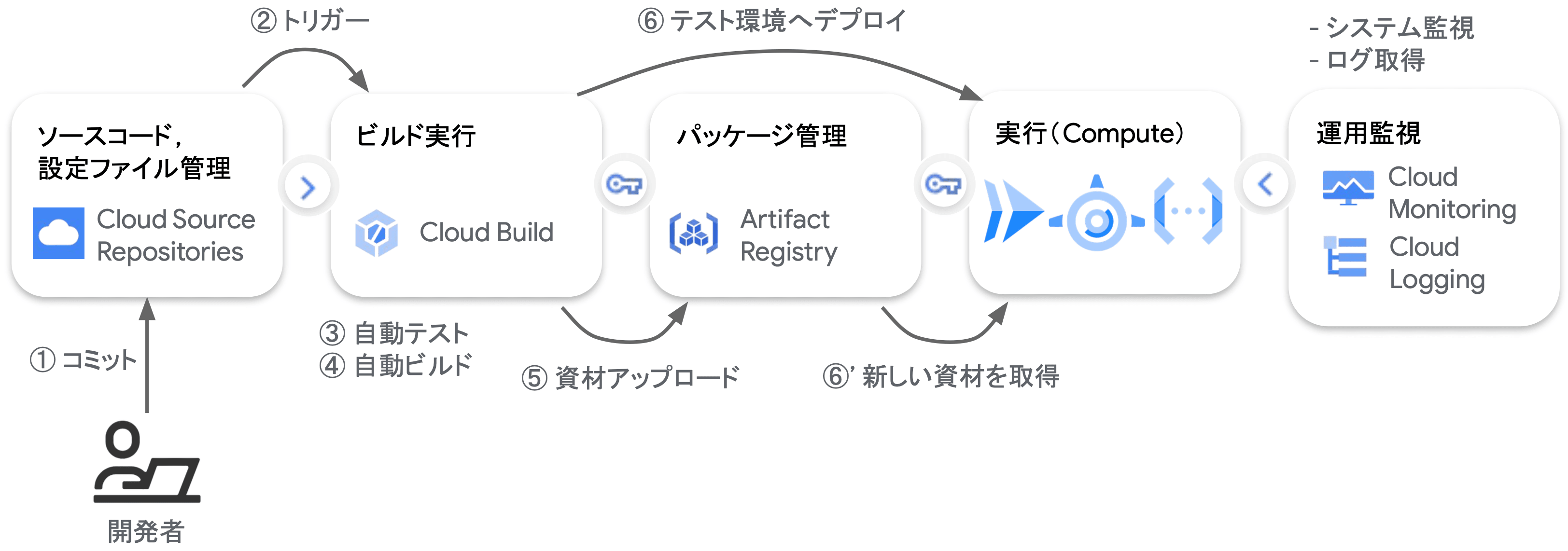
GCP のマネージドサービスを用いた CI/CD パイプラインの構築には、Code Build や Code Deploy、またコンテナイメージやアーティファクトを世代管理する Google Artifact Registry(GAR)を用いることができます。
CI と CD の分離
- CI(続的インテグレーション)/ CD(継続的デリバリ)を分離して実装することで既存課題の解決、または継続的な改善に繋がる
- ロールアウト / ロールバックにかかるリードタイムの短縮
- より柔軟で一貫性のある成果物の管理
- 要件に応じ、柔軟に選べるデプロイ手段
- リリース履歴等 DevOps 指標の可視化
- 適切な粒度 & 最小権限の原則による権限・監査設定
ここで、CI と CD の分離は、具体的に CI と CD のツールを分離する ことを意味しています。 CI プロセスが自動的に CD に直結している場合、リリースタイミングの制御が難しくなります。 例えば、デプロイウィンドウを限定している組織や、リリース前に Approval が必要なケースでは、CI と CD の分離がないと、調整やレビュープロセスが適切に挟み込まれず、リリースが予定外のタイミングで行われる可能性が出てきます。 また、Four Keys をはじめリリースに関連するメトリクス収集時の柔軟さが損なわれる可能性ががあります。
CD における、Continuous Delivery(継続的デリバリ)と Continuous Deployment(継続的デプロイメント) のとの最も大きな違いは、デプロイのタイミングで開発者が介入するか否か にあります。 前者はデプロイに伴う承認プロセス(Approval)を挟みますが、後者は全てのプロセスが完全に自動化されています。
GitOps
- インフラストラクチャやアプリケーション構成において、GitHub を唯一の情報源(SSOT:Single Source Of Truth)として活用し、デプロイやインフラ管理を自動化
- 透明性、追跡可能性、デプロイメント精度が向上することで、開発効率の大幅な改善が見込まれる
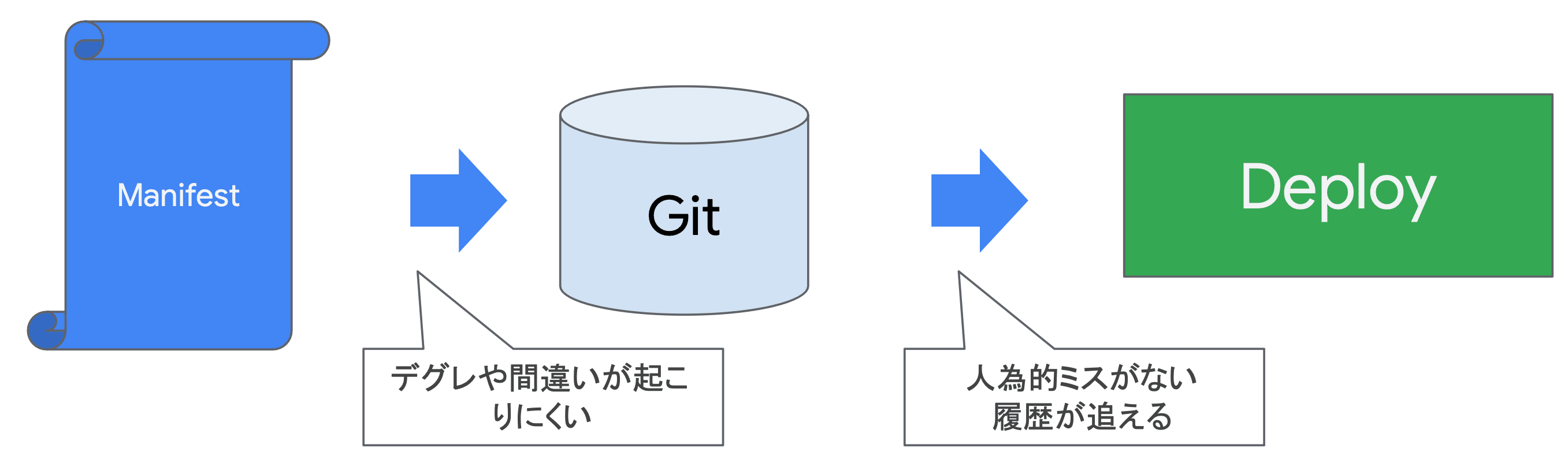
デグレ(Degradation: 品質低下)
- 機能の追加や変更のために稼働中のシステムを修正した際に、それまで動作したものが動かなくなってしまうことによって発生するトラブル
宣言的な構成に基づいた運用を実現するためには、GitHub にアプリケーションコードやインフラストラクチャコードを集約し、唯一の情報源とします。 これにより、複数の開発者がローカルからコードを変更したとしても、常に GitHub のリビジョンブランチ(リリースブランチ)に揃えることができます。 これが、GitHub を用いた Operation(GitOps)です。
GitOps における CI と CD の分離
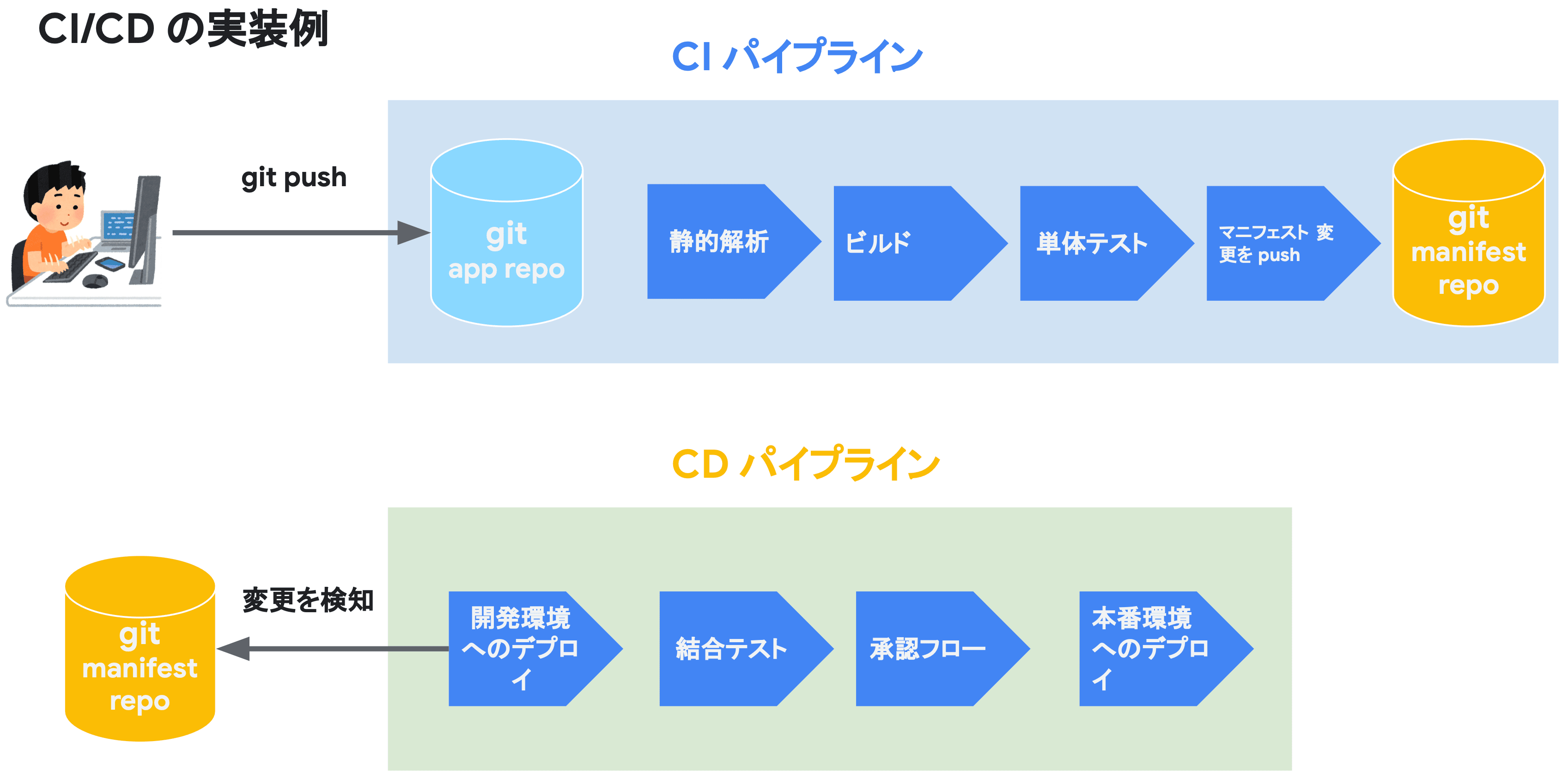
- CI
- 開発者はコードをリポジトリにプッシュする
- CI ツールは自動的にコードのテストとビルドを実行する
- ビルドによって得られる、構成ファイルやコンテナイメージをリポジトリに保存する
- CD
- GitOps では、リポジトリに保存された構成情報が実際のシステムに反映される
- CD ツールはリポジトリの変更を監視し、変更があれば自動的にデプロイプロセスを開始する
GitOps における CI と CD の分離では、開発者は PR をリビジョンにマージする部分までが含まれます。 CD プロセスは、リビジョンをポーリングし、変更差分がある際に、ワークロードを更新します。
例えば、GitHub Actions を CI ツール、PipeCD を CD ツールとして使用する場合、
- 開発者はアプリケーションコードを変更して PR を作成(インテグレーションテストもここで実行される)
- Approve を受けてリビジョンブランチにマージ
ここまでが CI プロセス。
- PipeCD EventWatcher が変更を検出して、対象となるコンテナイメージを取得
- リビジョンのマニフェストに基づいて、Pod をローリングアップデート
ここまでが CD プロセス。
といったような CI/CD 分離が挙げられます。
CI と CD の分離によるメリット・デメリット
- メリット
- 権限とアクセス制御が正確に行われる
- リポジトリ毎の可読性とメンテナンス性の向上
- ビルドとデプロイを独立して実行可能
- デメリット
- リポジトリの複数利用による維持コストの増加
- ツール管理や自動化に伴う対応(運用)コスト
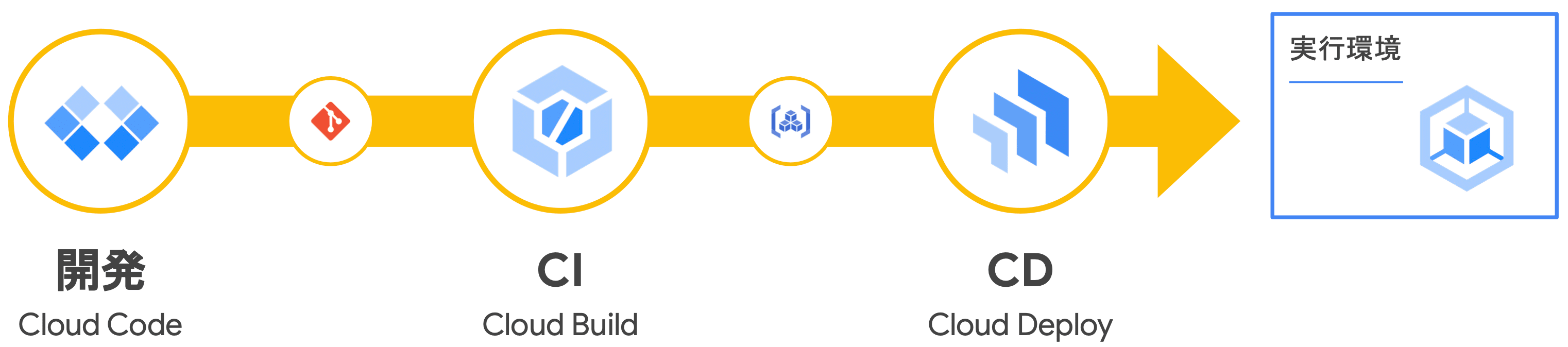
GCP のマネージドサービス
- 基本的な CI/CD の流れ
- Google Cloud を活用したサプライチェーンマネジメントの例
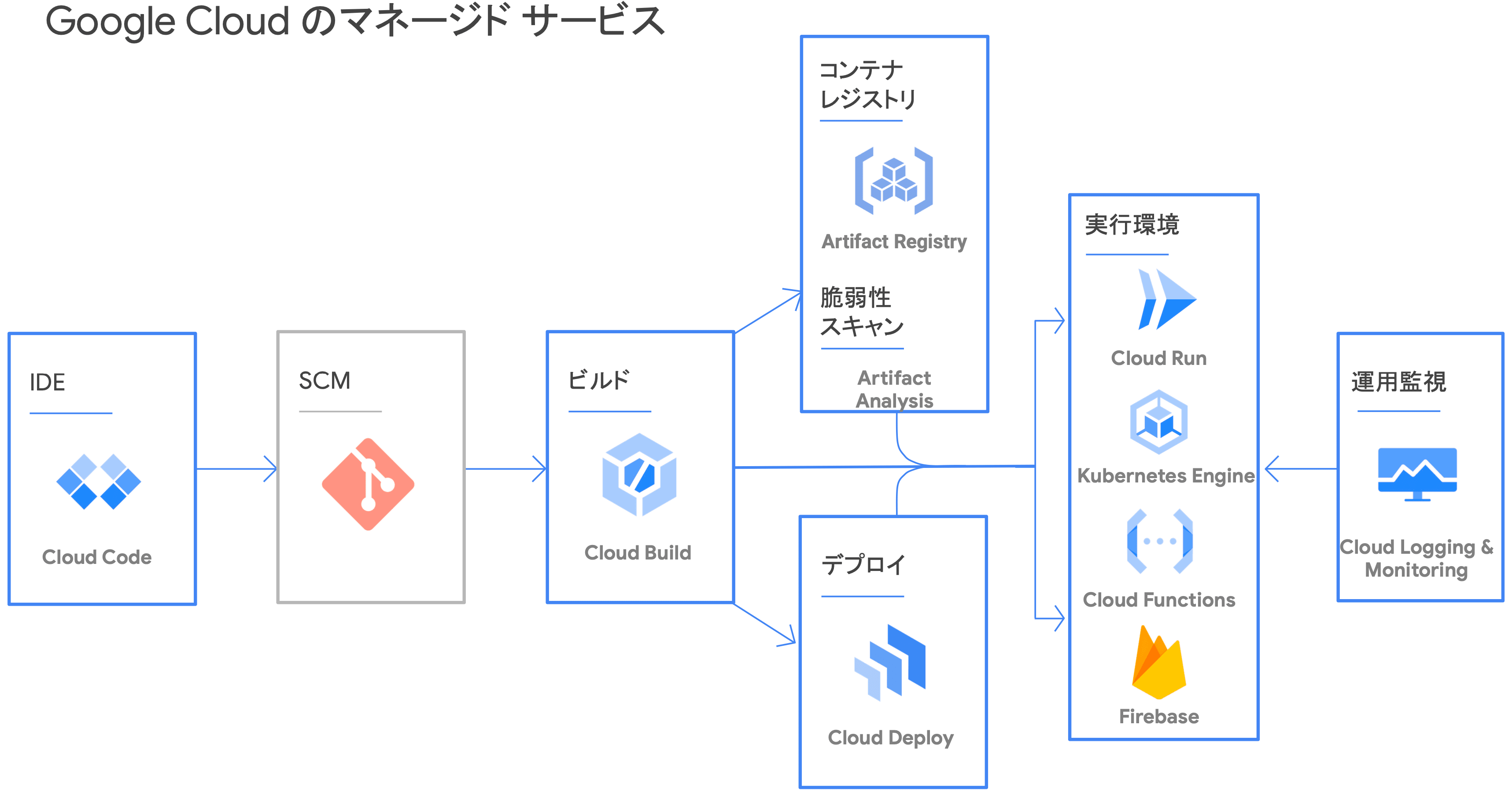
Google Cloud では、例えば、Cloud Code で記述したコードを Code Build でビルド、GAR にプッシュし、Code Deploy が対象のコンテナイメージを取得してオーケストレーションツール(Cloud Run, GKE, Firebase, ...etc.)にデプロイするようなサプライチェーンマネジメントが挙げられます。
Cloud Build
- Cloud Build
- 開発者フレンドリ
- CSR(Cloud Source Repositories)、GitHub、Bitbucket 等の変更をトリガに
- 柔軟なビルドステップ
- あらゆる CLI ツールをビルドステップとして組み込むことが可能
- フルマネージド CI プラットフォーム
- 開発者自身(我々が)VM を用意したりキャパシティの管理をする必要がない
- ビルドステップとして テスト・ビルド等、柔軟に CI/CD プロセスを実行可能
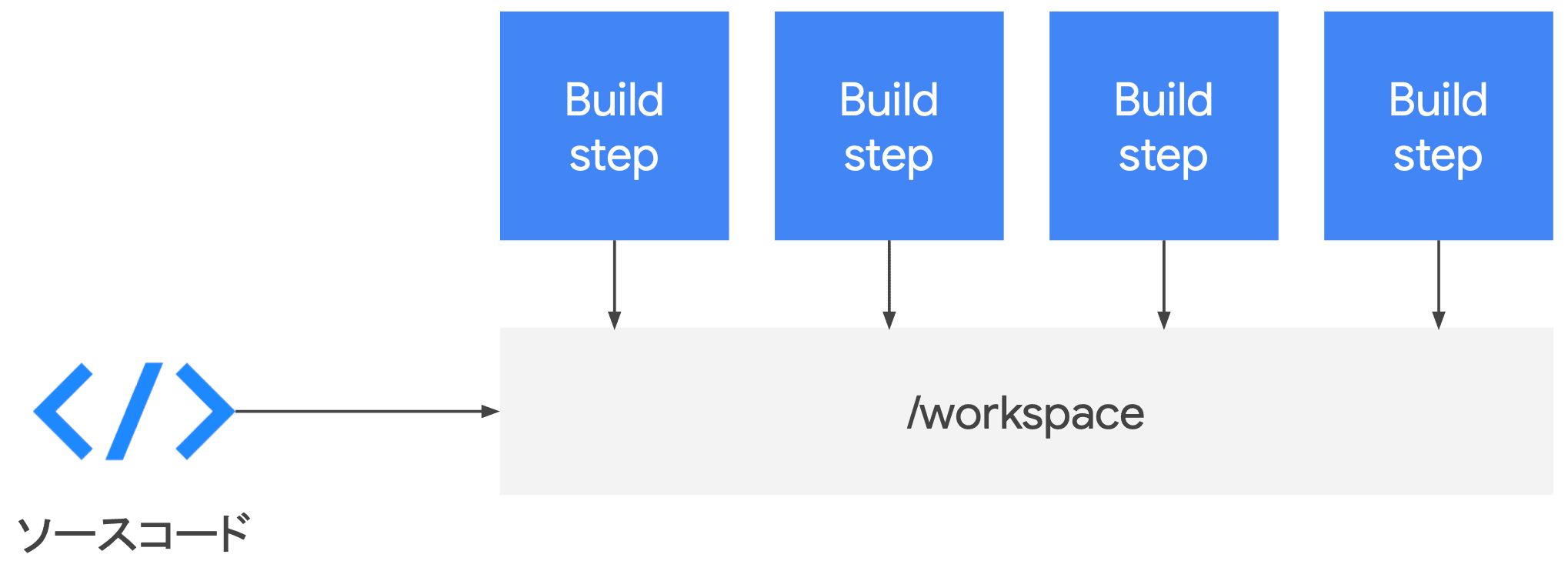
- テスト
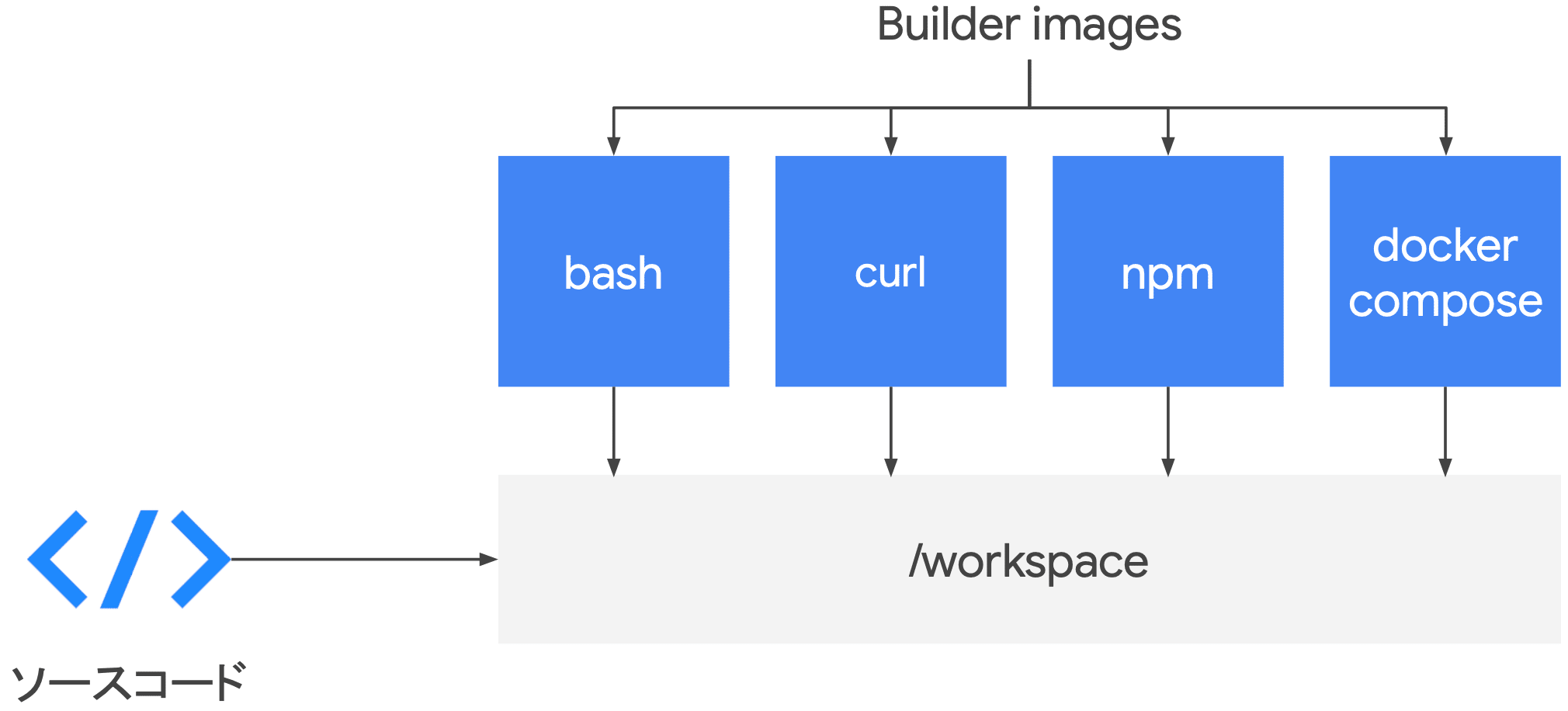
- ビルドと保存
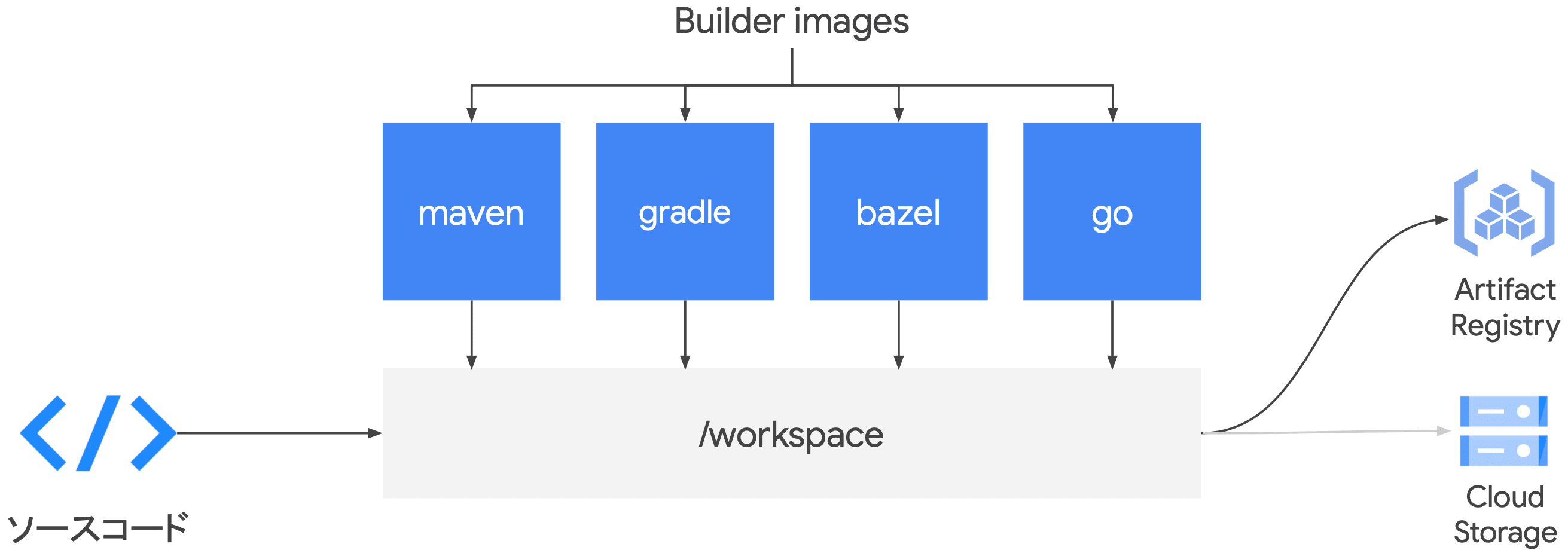
Code Deploy
- Cloud Deploy
- 継続的デリバリ(CD)に特化したマネージドサービス
- CD のための各種機能をフルマネージドで提供
- CI はこれまでのパイプラインで実施して、Cloud Deploy 自体はデプロイのみを担当
- 成果物の厳密な管理
- リリースコンテンツを事前にまとめ、環境依存の無い一貫性のある成果物管理
- 重要指標(メトリクス)の可視化
- CI/CD プロセスそのものの改善を促す指標を可視化
- DORA 4 指標の "デプロイ頻度" と "デプロイ時失敗率" を可視化可能
- デプロイしたい単位(製品やサービス)毎に、デプロイ先の環境、デプロイ順序、デプロイ方法を制御可能
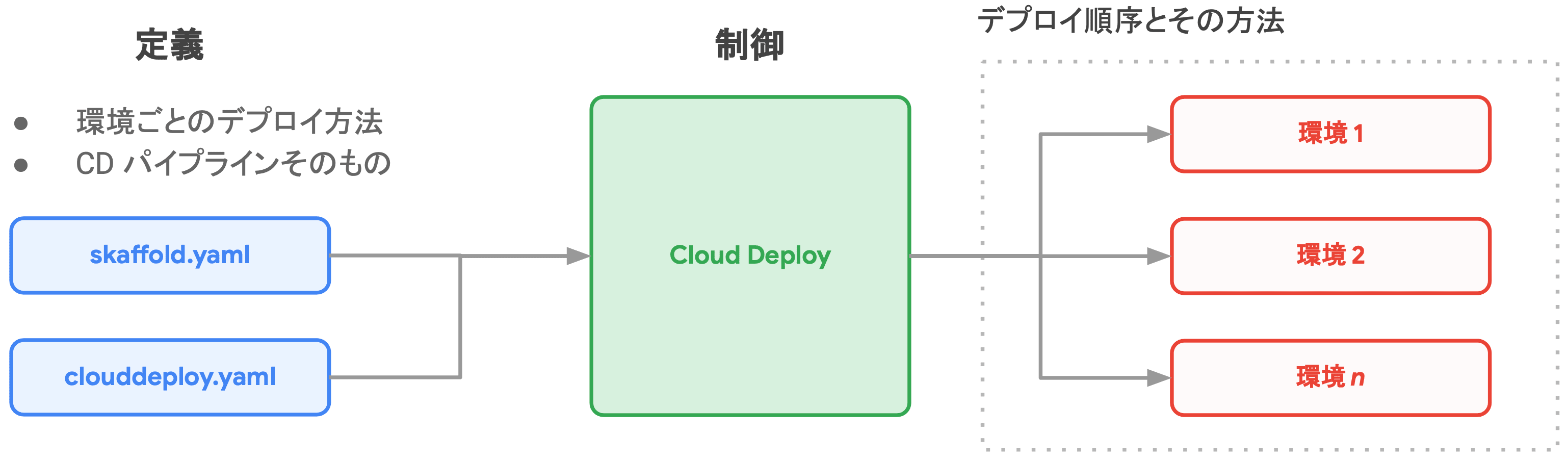
Cloud Deploy によるデプロイの流れ
- 予め パイプライン として定義した各 ターゲット に対して、成果物を リリース としてまとめ、順に ロールアウト する
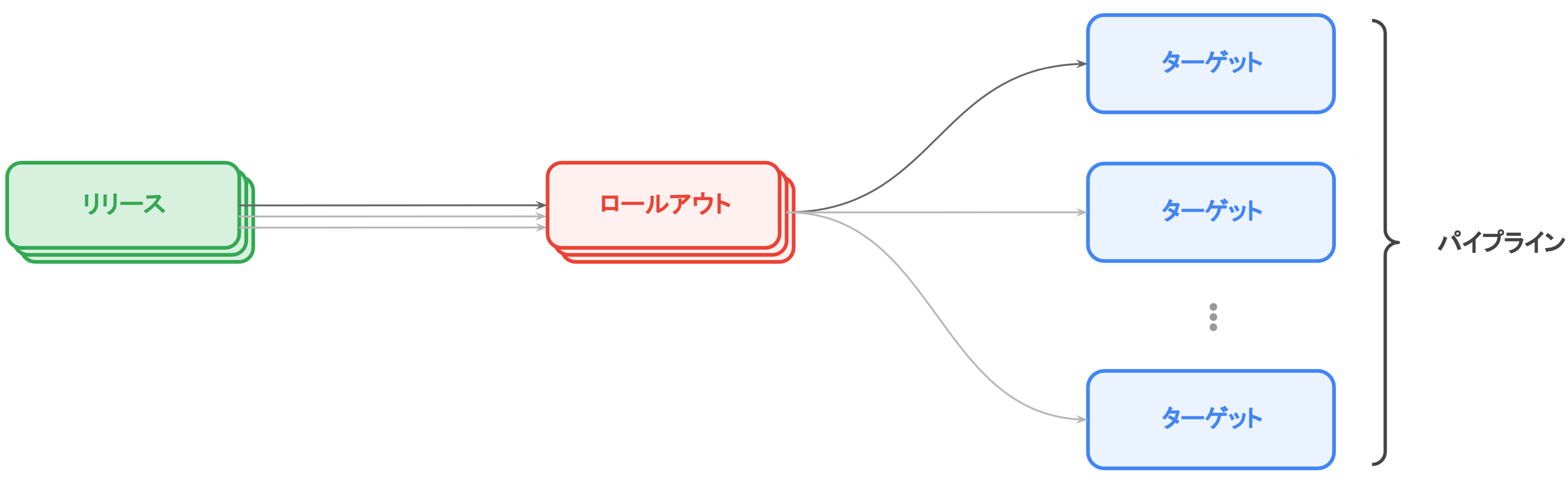
- パイプラインとターゲット
- デプロイ先の環境を "ターゲット" と呼ぶ
- 各ターゲットに、どのような順序で、どのようにデプロイするかを "パイプライン" として定義する

- リリース
- ビルドしたイメージを同時にデプロイしたい単位(リリース)にまとめる
- 各環境で、どのリリースバージョンが稼働しているかを確認できる
- 特定のリリースバージョンがどの環境で稼働しているのかも確認できる
- ロールアウト
- リリースをターゲットにロールアウトする度に作られるリソース
- 初回リリース作成時には、すぐに最初のターゲットにロールアウトされる
- 2 つ目以降のターゲットに対しては、プロモーション(GCP 独自の機能) することで同一のりリースがロールアウトされる
- 例:Dev 環境に導入したリリースを、Prd 環境にもそのままリリース(プロモーション)する
実際にハンズオンでは Cloud Deploy によるプロモーション機能を利用してみました。 前で述べた GKE Fleet と統合することで、開発から本番までのパイプラインを非常にシームレスに結合・制御することができる印象でした。 特に、ステージング環境では動いていたのに、全く同じ環境を模倣しているはずの本番環境ではうまく動かない(主に人的ミス)といった事態を、プロモーション機能は改善してくれるのではなかろうかと思います。
デプロイフローの例
- ① ローカル開発
- Skaffold を使用することで、ローカル開発でホットリロードしながらデバッグすることが可能
- ローカル開発:ローカル環境において、ファイルの変更をトリガにビルド・プッシュ・デプロイまでを自動化してくれる
- 本番:CI に組み込むことでデプロイが簡素化される
- ② コードレビュー
- feature ブランチへプッシュして PR を作成し、自動テスト結果とともにコードレビューを依頼
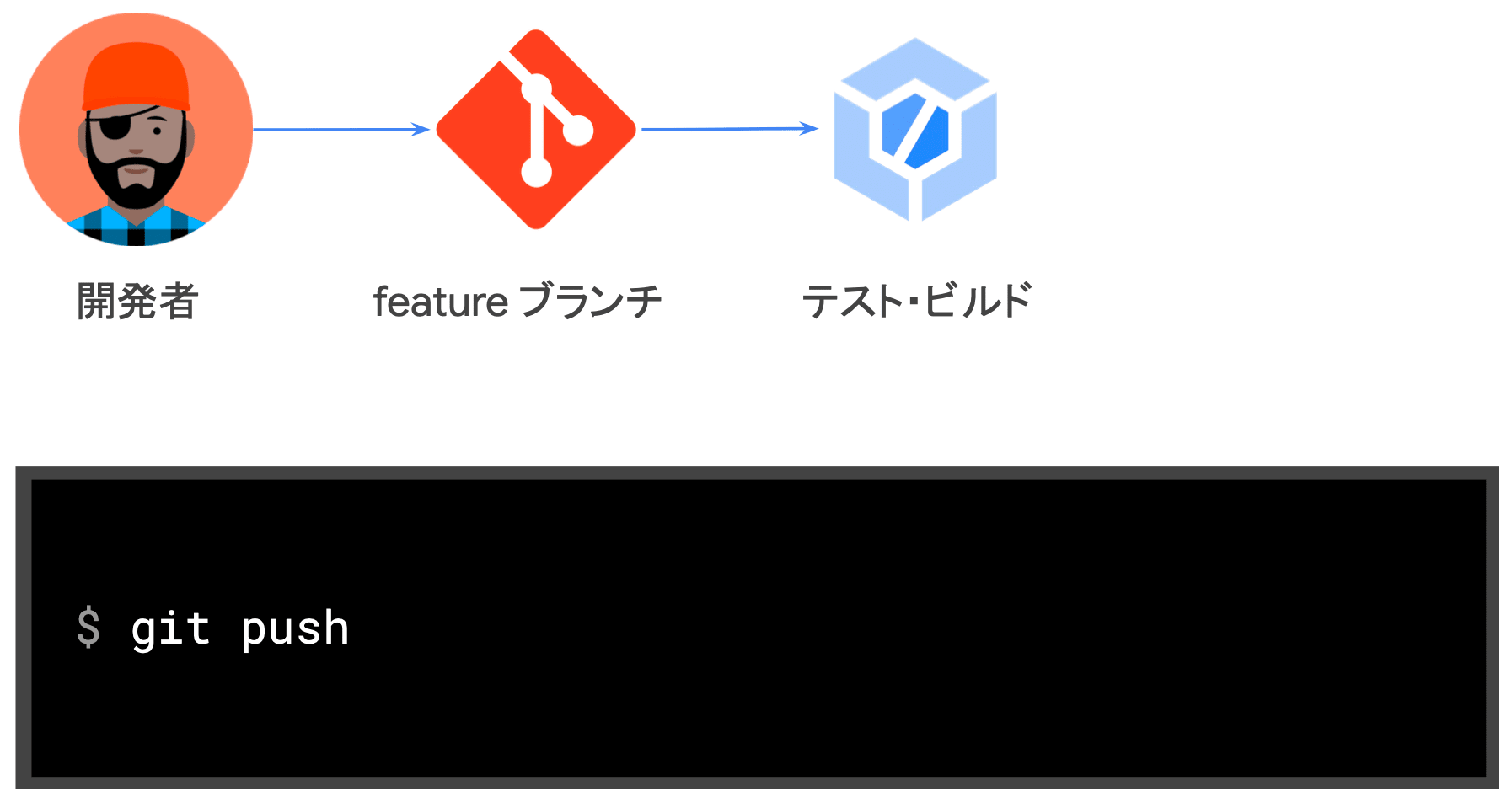
- feature ブランチへプッシュして PR を作成し、自動テスト結果とともにコードレビューを依頼
- ③ ロールアウト
- コードをリビジョンブランチにマージ
- コンテナをビルド・プッシュして、Cloud Deploy にリリース対象をまとめ、開発環境へロールアウト

- ④ 評価環境へのプロモーション
- 開発環境での(自動)テストが問題なければ(Pub/Sub 経由のトリガで)そのまま自動的に評価環境へ"開発環境と同一のリリース対象" をプロモーション
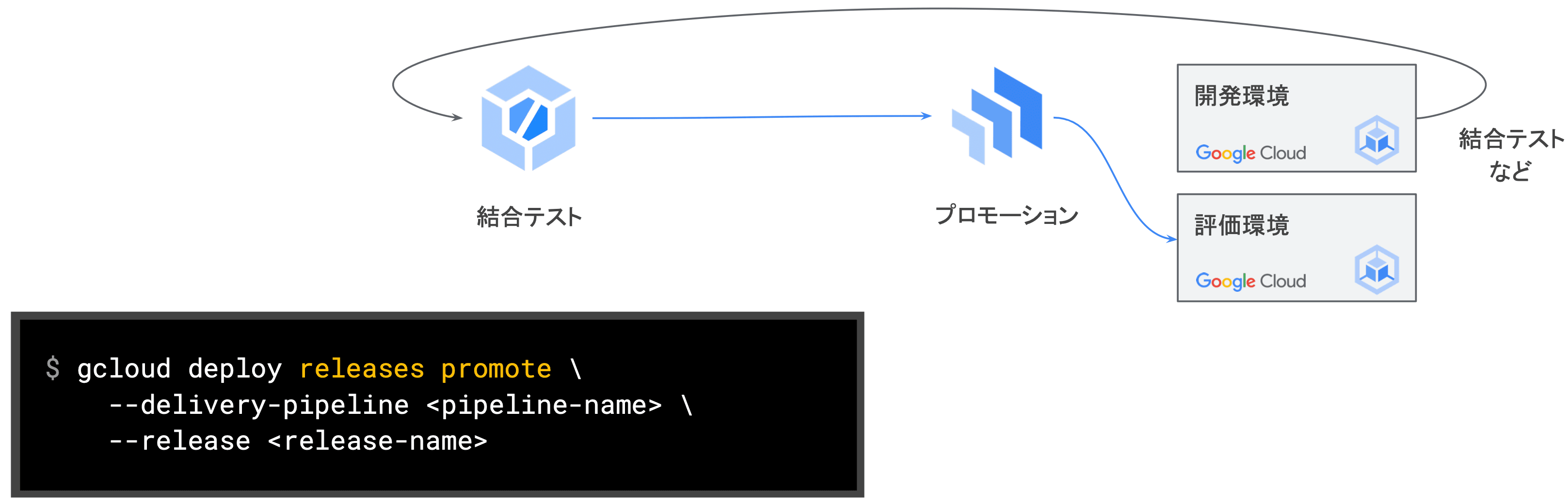
- 開発環境での(自動)テストが問題なければ(Pub/Sub 経由のトリガで)そのまま自動的に評価環境へ"開発環境と同一のリリース対象" をプロモーション
- ⑤ 本番環境へのプロモーション
- 評価環境でも問題なければ、管理者の承認を得て、本番環境へプロモーション
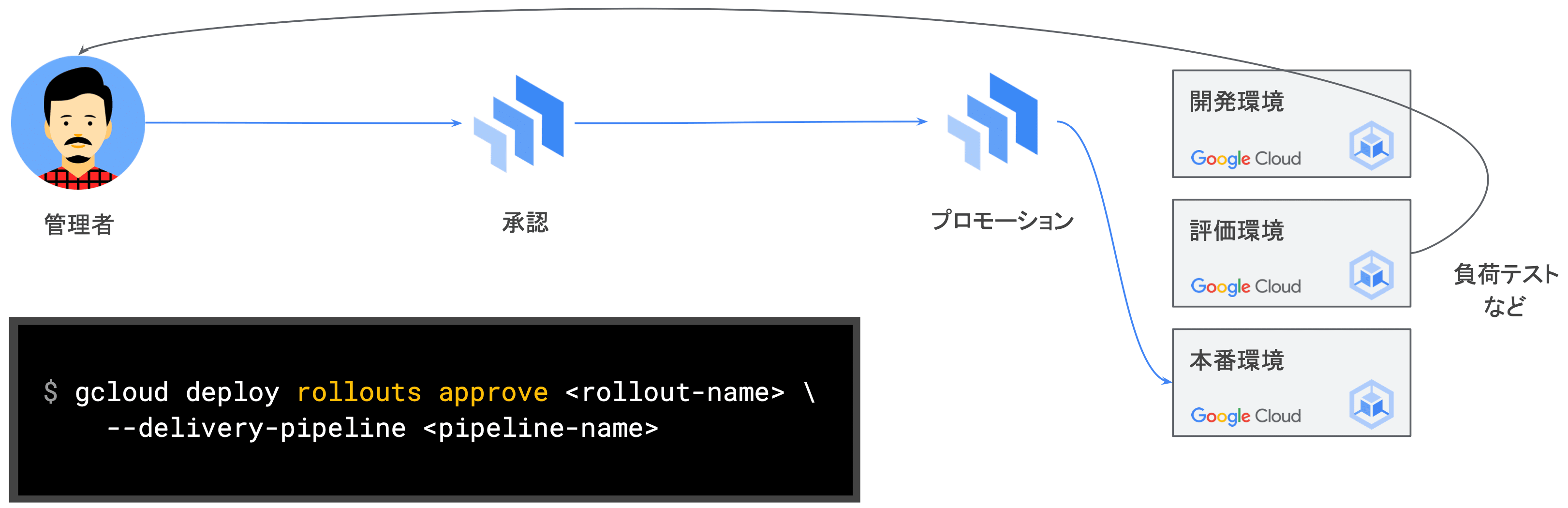
- 評価環境でも問題なければ、管理者の承認を得て、本番環境へプロモーション
- ⑥ ロールバック
- 本番環境から何らかの不具合が通知された場合は、直前のリリースをロールバック
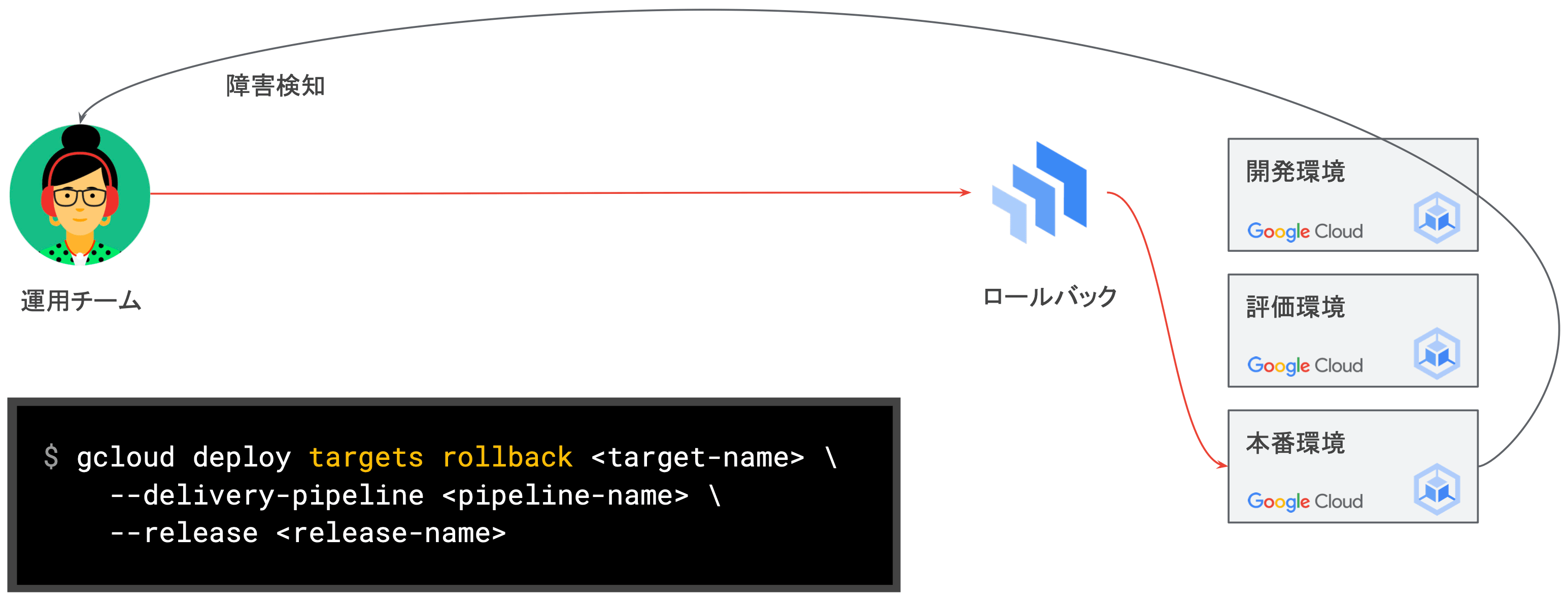
- 本番環境から何らかの不具合が通知された場合は、直前のリリースをロールバック
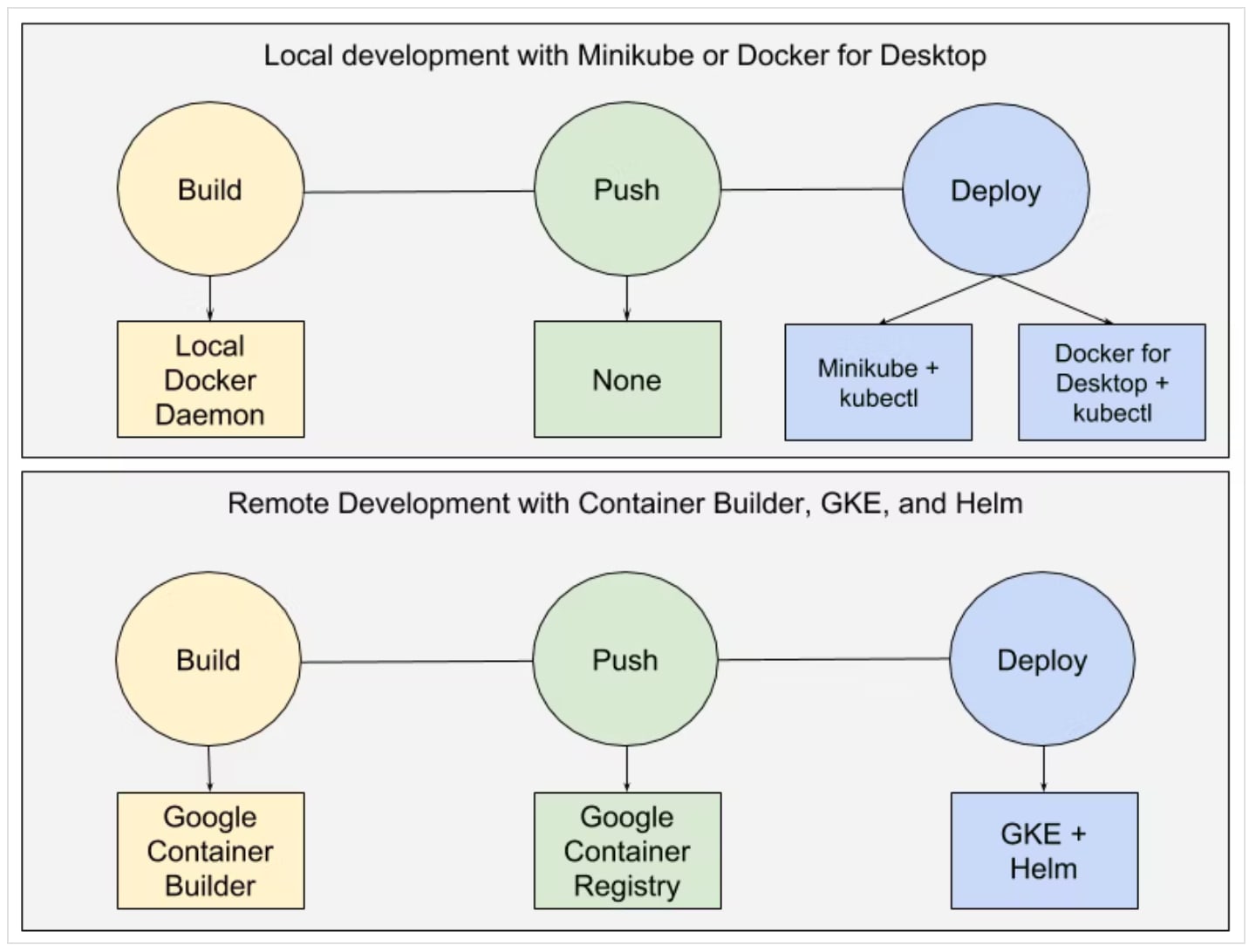
Skaffold
- コンテナを利用して開発で困るのが、少しの変更であってもビルドしてデプロイをしなければならないというストレス
- 変更を行って、その image を build して、deployment を更新するのが面倒
- 例:docker compose 等を使用した開発では VolumeMount したローカルファイルを使用できるが、本番環境では使用できない...
- Google 公式なので自作ビルドツールよりは安心
- skaffold を起動した上でローカルのファイルを変更すると、ホットリロードによって kind のリソースを自動的に更新してくれる
- Kubernetes だけではなく、CloudRun でも利用できる
GCP におけるオブザーバビリティ
- モニタリング
- Cloud Monitoring
- ロギング
- Cloud Logging
- Cloud Error Reporting
- APM(Application Performance Metrics)
- Cloud Profiler
- Cloud Trace
Cloud Logging
- Google Cloud のすべのログを集約する SaaS
- 収集されるログ
- Google Cloud の操作ログ
- データアクセのログ
- サービス固のログ
- fluentbit ベースのログ収集エージェント
- GKE、GAE では、エージェントがすでに VM イメージに含まれている
- 1 の手順で Compute Engine Linux VM 全体にインストールできる
- コンポーネント

Google Cloud でプロビジョニングされるインスタンスには、基本的に fluentbit ベースのログ収集エージェントがインストールされています。 Cloud Logging のログルータを用いることで任意の宛先にログをルーティングすることができます。 また、不要なログは log sink exclusions 等でフィルタリングすることもできます。
Cloud Logging のアーキテクチャ
_Required- 管理アクティビティログ、システムイベントログ、アクセス透過性ログで構成
- 400 日間保持され、変更不可
- 無料
_Default_Requiredバケットによって取り込まれないログエントリで構成- 保存期間はデフォルト 30 日間
- 変更可能
- 費用:取り込み量、ストレージ
- 無効化と変更が可能
User-created- ユーザの必要に応じてカスタマイズされたログバケット
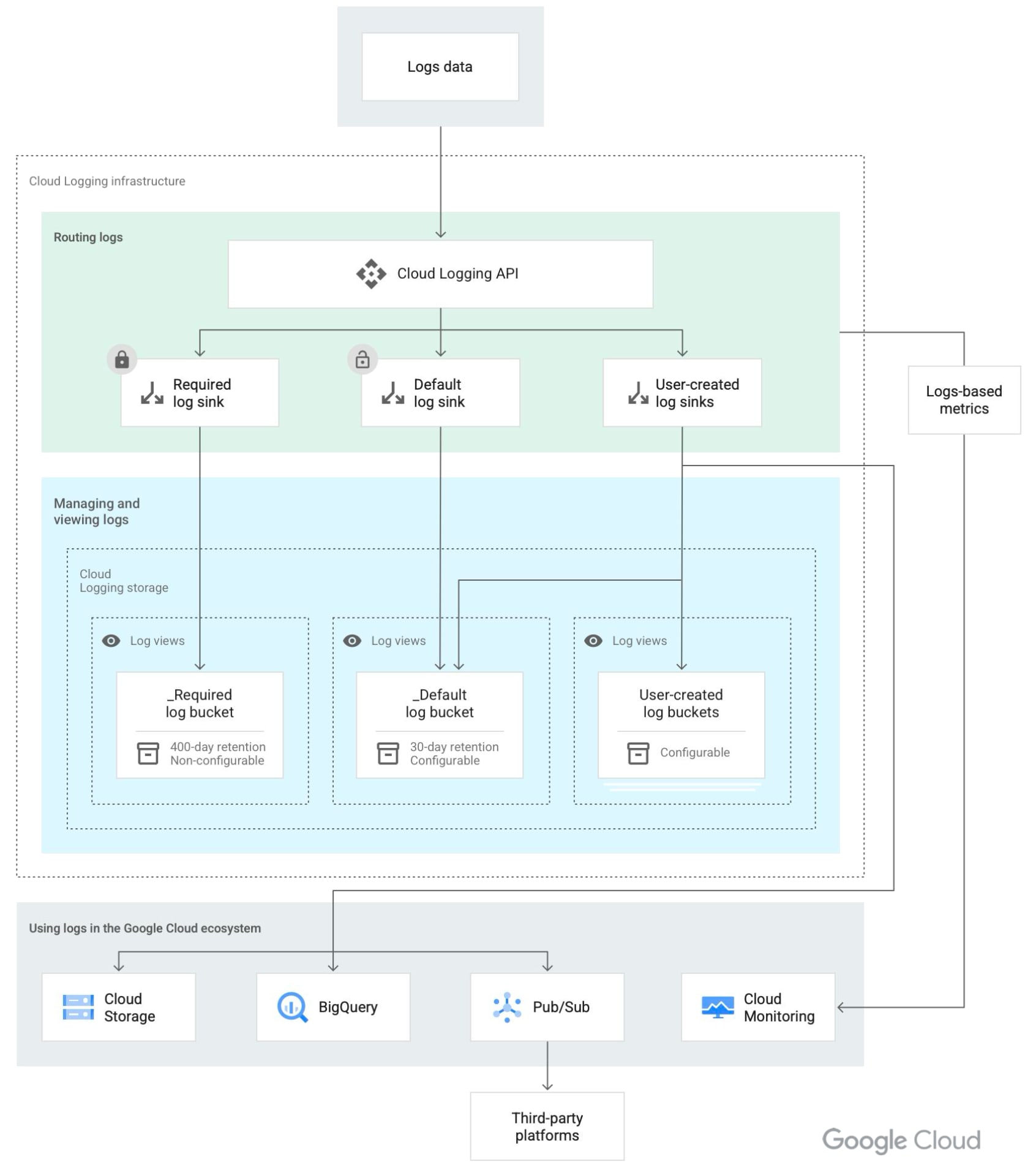
- ユーザの必要に応じてカスタマイズされたログバケット
GKE のロギング
- GKE はデフォルトで以下のログを Cloud Logging に収集
- 各コンテナの標準出力及び標準エラー出力
- システムログ(kubelet, docker, containerd 等)
- クラスタのイベントログ(監査ログを含む)
- Cloud Logging に収集するログをシステムログのみにすることも可能
- 収集したログから Log-based メトリクスの作成
- 収集したログを Cloud Storage, BigQuery, Cloud Pub/Sub へエクスポート可能
監査ログ(Audit ログ)
- システムやアプリケーションにおいて、重要な操作やイベントを記録するためのログ
- ユーザの操作やシステムイベント、セキュリティ関連のアクションログが含まれる
- 監査ログは、一般的にコンプライアンスやセキュリティ、トラブルシューティングの目的で使用される
GKE のログ転送の仕組み(デフォルト構成)
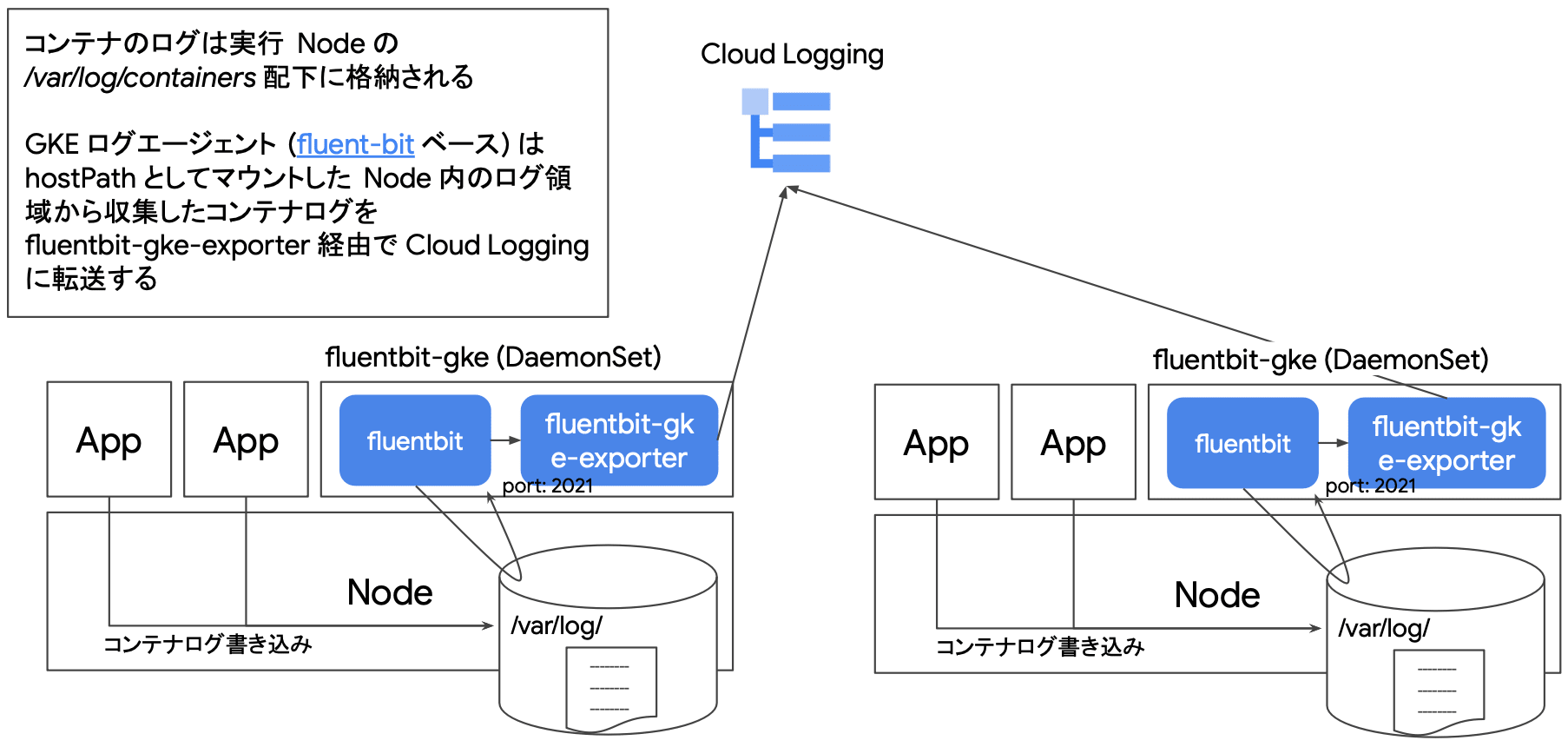
GKE ノードには fluentbit(fluentbit-gke)が kube-system にインストールされており、絶えずクラスタのログを Cloud Logging に流しています。 具体的には、コンテナが実行されているノードの /var/log/containers 配下にログが集約され、fluentbit が hostPath としてマウントしたノード内のログ情報を fluentbit-gke-exporter 経由で Cloud Logging にルーティングしてくれています。 fluentbit-gke および fluentbit-gke-exporter はいずれも DaemonSet で管理されるため、ノード毎に最低 1 Pod 起動します。
Fleet ロギング(GKE Enterprise のみ)
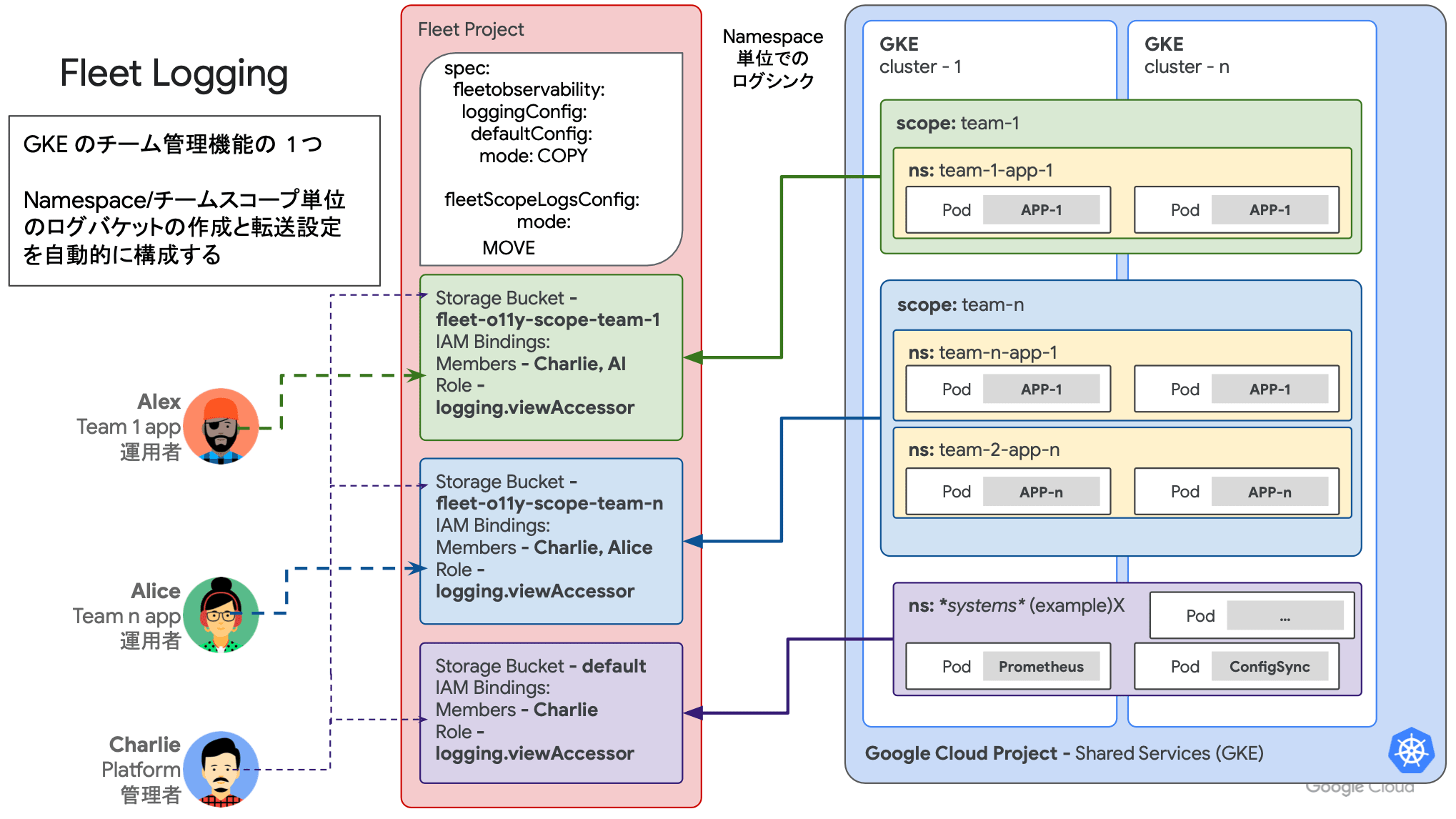
GKE Enterprise edition の Fleet では、より高度なログ収集機構が備わっています。 Fleet のロギングでは、ネームスペースおよびチームスコープ(Fleet)単位でログバケットの作成とルーティングが自動的に構成されます。
クラスタのログを Cloud Logging に流すだけでなく、それらを任意のスコープ毎に分類して管理することができます。
モニタリング
- GKE はデフォルトで Node / Pod のメトリクスを収集
- 収集したメトリクスは Cloud Monitoring に送られる
- CPU 使用率
- メモリ使用率
- ストレージ使用率
- ネットワーク使用率
- リスタート回数(Pod, コンテナ)
- ...etc.
- アプリケーションのメトリクスを GMP(Google Managed Prometheus)へ連携することも可能
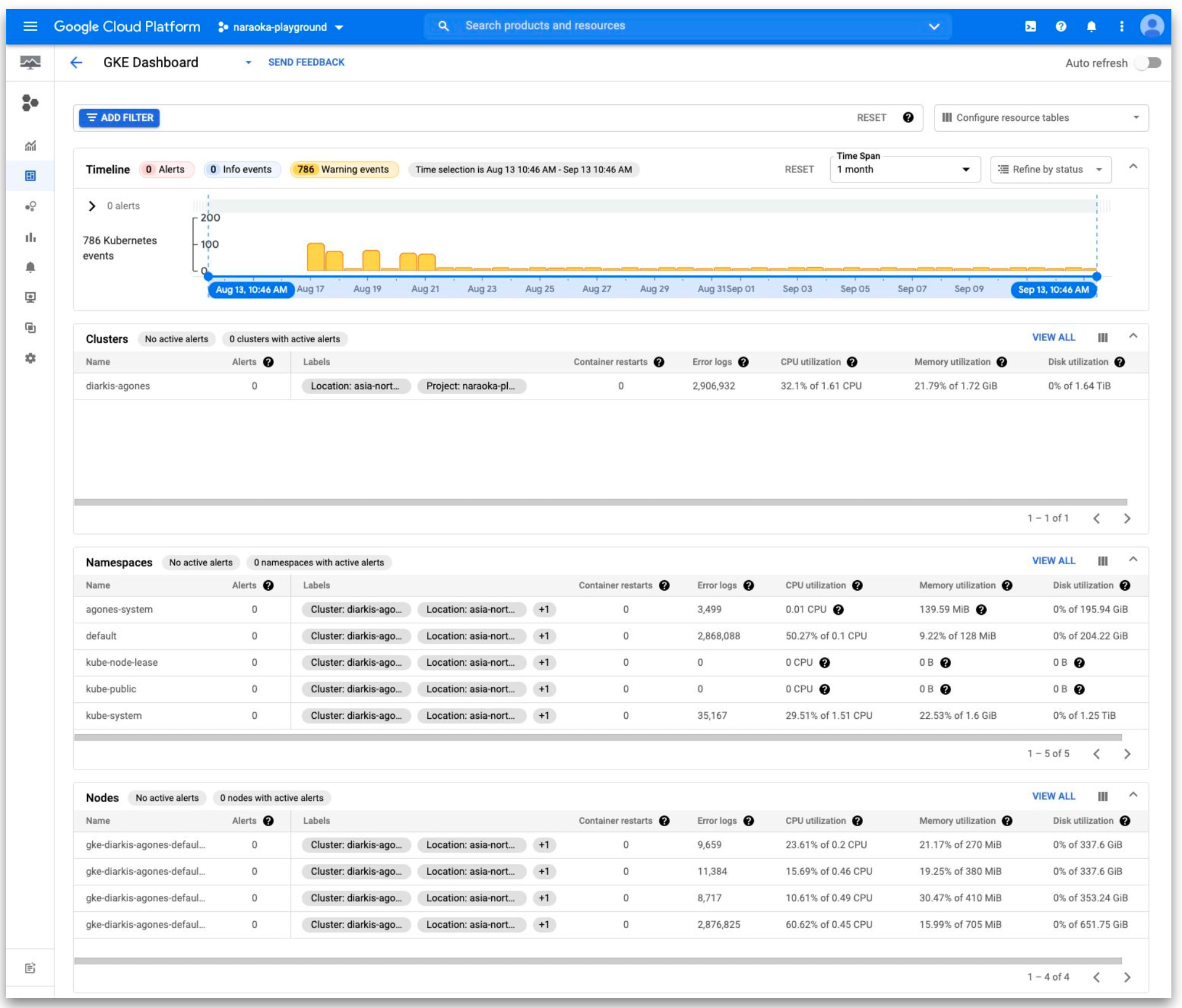
ワークロードメトリクス
- kube-state-metrics の自動収集をサポート
- Unhealthy な状態のワークロードを可視化可能
- Node にスケジュール不可
- CrashLoopBackOff 状態
- Readiness Check に失敗
- HPA のスケール上限に到達
- ...etc.
- ワークロードメトリクスの収集には GMP の有効化が必要
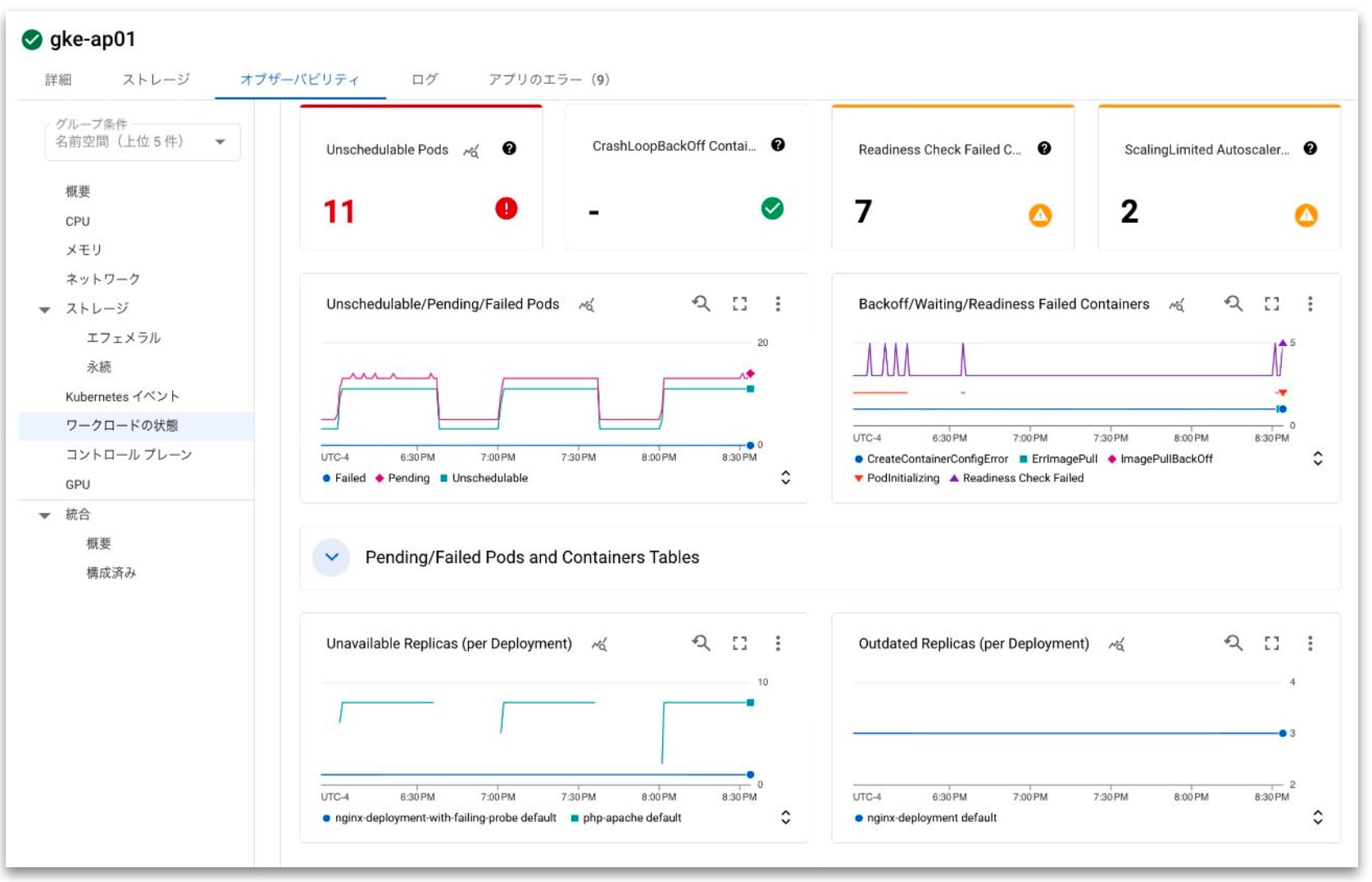
GMP:Google Managed Prometheus
GMP の特長
- 運用負荷の低減
- フルマネージドなデータストア / コレクタを活用することで運用負荷を低減
- 貴重なエンジニアリングリソースをコア業務に集中
- 複数環境の統合監視
- 複数クラスタ / プロジェクトを一元的にモニタリング
- オンプレミス・他社クラウド上のワークロードからもメトリクスを収集可能
- 既存監視ツールの有効活用
- Grafana / Alertmanager 等、既存の Prometheus エコシステムを活用可能
- 既存の運用体制は変えずに、ストレージのみを GCP マネージドサービスに移行可能
GKE クラスタで GMP を有効にすると、GCP マネージドサービスとして提供されている Prometheus を利用することができます。 GMP を有効化すると、gmp-public や gmp-system としたネームスペースが作成され、Prometheus がデプロイされます。 GMP をインストールしておくことで、ワークロードのメトリクスを自動的に Cloud Monitoring に流してくれます。
また、Grafana や Alertmanager 等、標準的な Prometheus エコシステムとも統合することが可能で、既存の運用体制は変えずに、ストレージのみを GCP マネージドサービスに移行したりといった使い方もできます。
クエリ
- PromQL(Prometheus Query Language), MQL(Monitoring Query Language)をサポート
- 最大 1,000 の GCP プロジェクトをグローバルな 1 データソースとして監視可能
- クエリ実行時にプロジェクトのグループに読み取り権限を設定可能(指標スコープ を利用)
- Query using Grafana
Day 2 まとめ
Day 2 実践編では、実際に手を動かして "GCP を活用したゴールデンパスの整備" をハンズオンで学びました。 今回は、GKE をベースに CI/CD の構築からオブザーバビリティの整備といった最も基本的なプラクティスを実践しました。
昨今では CNCF 傘下のプロダクトや各種 OSS も充実しており、非常に高機能なエコシステムを構築することが可能ですが、Google Cloud では各ソリューションを組み合わせることで、統合的な運用環境を構築できるようになっており、非常に便利だと思いました。 ただし、開発組織によっては痒い所に手が届かない可能性はあるので、特長や、メリット・デメリットを押さえて適切に導入を検討することが重要になってくると思います。
GKE で始める Platform Engineering - セキュリティガードレール編
本ハンズオンセッションでは Google Kubernetes Engine(GKE)を基盤とした開発者向けプラットフォームにセキュリティガードレールを導入する実践的な手法を学ぶことができます。 自社の要件に合った安全なプラットフォームを GKE 上で構築するための実装方法をハンズオン形式で習得します。 ※本セッションは「GKE で始める Platform Engineering - 入門編」受講済みの方を対象としています。
Day 3 では、プラットフォームエンジニアリングにおけるゴールデンパスに加え、もう一つの重要な要素である "ガードレール" にフォーカスした内容となっていました。
ここでは、GKE の運用における潜在的なセキュリティリスクの理解、および開発者向けプラットフォームにおける安全性を確保する手法やソリューションについて学びました。
クラウド活用におけるガードレールの必要性
- クラウド活用が進み環境の規模が大きく複雑になってくると、すべての環境で適切なセキュリティを担保することが困難となる
- 開発における自由度やスケーラビリティを落とさず、セキュリティリスクを低減するためには、マニュアルによる運用ではなく自動化された仕組みが必要
開発規模が拡大にするにつれて潜在的なセキュリティリスクは発生しがちです。 プラットフォームエンジニアリングでは、ゴールデンパスを整備するだけでなく開発の安全性を確保するガードレールも必要となります。
ガードレールの整備方法も、組織形態やサービスによって異なりますが、一環してマニュアル作業や "秘伝のタレ" を極力撤廃し、自動化されたプラクティスをプラットフォームに組み込むことが重要となります。
開発者に求められる安全なプラットフォーム
- セキュリティは重要だがセキュアな環境を維持するためには様々なレイヤの考慮が必要となり、開発者の認知負荷増大に繋がる可能性がある
- また、必要以上に制限の強い環境は開発の生産性を下げる要因となる
- 開発の生産性を妨げない形で、「このプラットフォームを使えば簡単に自社要件に合ったセキュリティレベルが保たれる」 という状況を作ることが理想
- プラットフォーム開発者は自ら提供するプラットフォームのセキュリティリスクを適切に把握した上で要件に合った対策をとる必要がある
ガードレールの整備において、生産性と安全性のバランスを如何にして調整するかは非常に難しいポイントだと思います。 いわゆる、利便性とセキュリティのトレード・オフというやつです。
開発者の生産性を担保し、セキュリティを強化していくためには、開発組織全体を俯瞰し、どのレイヤにどういったセキュリティリスクが介在するのかを適切に洗い出す必要があります。 即座に対応しなければならないものから、中長期的な目線でプラットフォームを整備し、開発者が自律してセキュリティを確保できるような仕組み作りまで、ロードマップの設定や定期的な見直しが重要です。
Kubernetes(GKE)環境に潜むリスクの把握
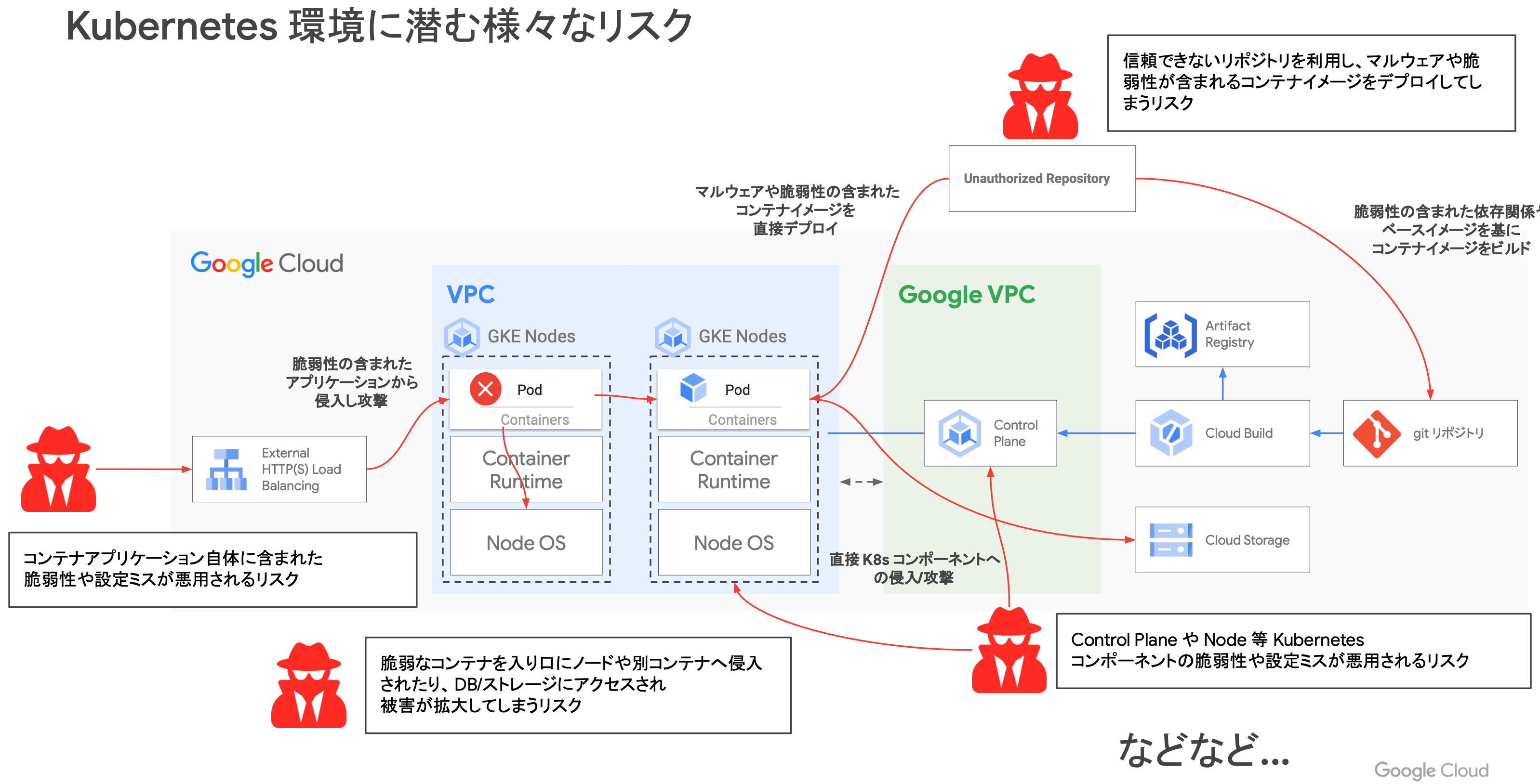
- コンテナアプリケーション自体に含まれた脆弱性や設定ミス
- 脆弱性の含まれたアプリケーションから侵入して攻撃される可能性
- 脆弱なコンテナを侵入路としてノードや他コンテナへ不正にアクセスされる
- 信頼できないレジストリからの Pull することで脆弱性(マルウェア)が含まれるコンテナイメージをデプロイしてしまう可能性
- Kubernetes のシステムコンポーネント(Control-Plane / Data-Plane)そのものの脆弱性や設定ミスが悪用されるリスク
Kubernetes は多くのコンポーネントで構成されており、それらは密に絡み合っています。 クラスタの管理者は、不正なオペレーションからコンポーネント自体の脆弱性まで、ありとあらゆるリスクを想定する必要があります。
ここでは主に、リクエストの流入から実際に処理するコンテナまでの経路上にどのようなセキュリティリスクが潜んでいるのかが紹介されています。
不正なプログラムが仕込まれたコンテナをデプロイしてしまうと、クラスタネットワークを通じて他のワークロードにもアクセスすることができてしまいます。 そのため、デプロイするイメージにマルウェアが含まれていないか、信頼されたリポジトリから Pull されたものであるかを判断する仕組みを確保しておくことは非常に重要です。
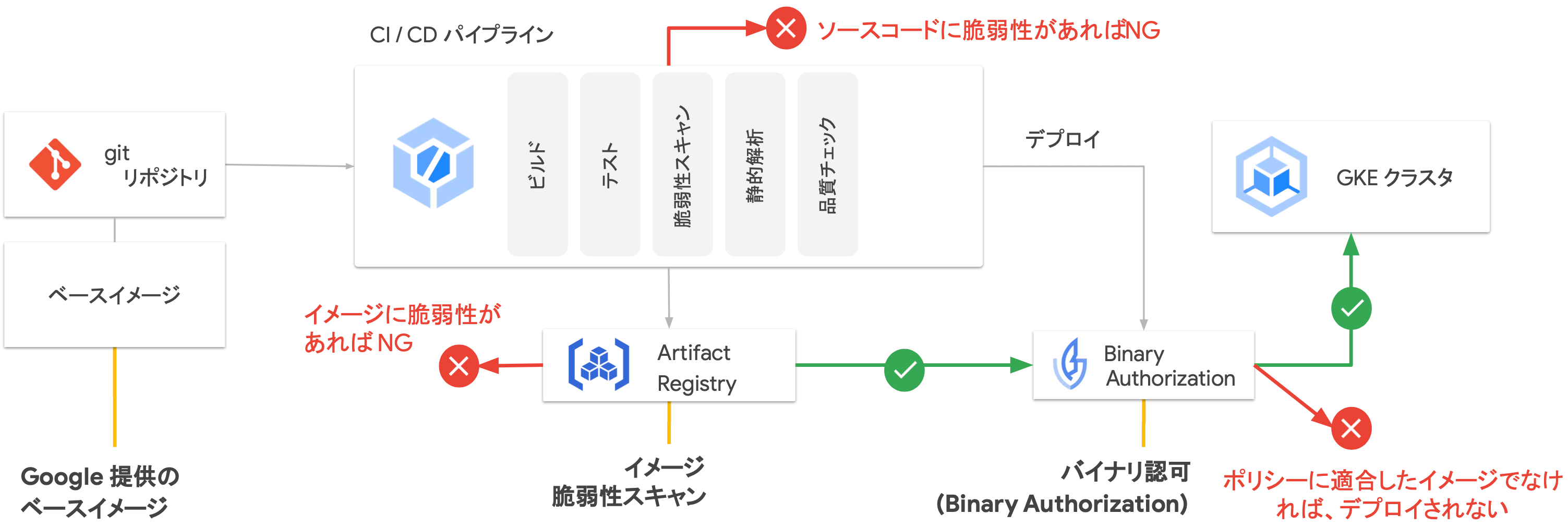
コンテナイメージ脆弱性への対策
- アプリケーション脆弱性への対策
- WAF や静的解析ツール等の導入
- セキュアな CI/CD パイプラインの提供
- CI/CD パイプライン内でのコンテナイメージのスキャン、静的解析の実行
- 実行環境上での継続的な脆弱性スキャン
- CI/CD パイプラインを経由せずデプロイされたアプリケーションの脆弱性スキャン
- デプロイ後に発見された脆弱性の検知
- 信頼できるアーティファクトのデプロイを保証
- CI/CD をバイパスさせない、信頼できないコンテナイメージをデプロイさせない
不正なコンテナイメージのデプロイを回避する策として、上記のような手法が挙げられます。 例えば、静的解析ツールによるイメージのスキャンや、CI/CD パイプライン上での脆弱性検出・ブロック等、開発から本番環境への適用に至るまでに様々な対策を取る必要があります。
サプライチェーンに潜む脆弱性
- サプライチェーン
- 開発者がソフトウェアを作り、それをエンドユーザが使うまでの一連の流れ

- 開発者がソフトウェアを作り、それをエンドユーザが使うまでの一連の流れ
- サプライチェーン攻撃
- サプライチェーンが依存するソフトウェアや外部サービスに対する攻撃
- OSS や外部サービスへの依存度が高まる昨今、対策が難しい攻撃の一つ
- Software supply chain threats

CI/CD パイプラインから視野をさらに広げ、開発(生産)からエンドユーザへの提供(消費)に至るまでの一連のプロセスは サプライチェーン(供給の連鎖) と呼ばれます。 アプリケーション開発のサプライチェーンにはいくつものセキュリティリスクが存在します。
OSS はソースコードが膨大であったり、頻繁なメンテナンスが発生するため、コードの全体を理解したり、常にそれらの変更を追従したりするのは非常に困難です。 そのため、昨今ではサプライチェーンに組み込まれた OSS の脆弱性を突き、サービス全体への影響を狙う サプライチェーン攻撃 が急増しています。
Log4Shell
- 2021 年に発生
- Log4j でリモートから任意のコードが実行できるようになってしまう脆弱性
- 悪用されるとランサムウェアへの感染や情報漏洩、侵入拡大等が起きる可能性がある
Log4Shell(Log4j Shell)は、2021 年 12 月に CVE-2021-44228 として公表された Apache Log4j ライブラリにおける深刻なリモートコード実行(RCE:Remote Code Execution)脆弱性です。 この脆弱性は、Log4j の不適切なログ処理により、悪意のある攻撃者がサーバ上で任意のコードを実行できてしまう重大なセキュリティ問題を引き起こします。
Log4Shell は Log4j v2.0 から v2.14.1 に存在し、広範囲にわたるシステムやアプリケーションに利用されていたため、世界中で非常に大きな影響を及ぼしました。
サプライチェーン攻撃に対する課題
- OSS 利用の急増
- ほどんど全ての商用コードベースは OSS に依存
- 未知のコントリビュータやサプライチェーンの拡大
- デプロイ頻度の増加
- モダンなソフトウェアスタックやプロセスは、デプロイの規模や頻度が増加している
- 自動化をしない限り、セキュリティへの対策はそのペースに追従できない(人の手では限界がある)
- 多様な攻撃ベクトル
- 複数の攻撃ベクトルを組み合わせることで、解決がより困難となる
- どの程度の危険に晒されたのかを把握することが難しい
- 標準化 / ツール
- 新たな標準が必要
- 市場には未だエンタープライズで利用できるエンドツーエンドのプロダクトやソリューションが無い
サプライチェーン攻撃の原因の多くは OSS に潜んでいます。 昨今では多様なサービスアーキテクチャを構築する中で、全てのコンポーネントを自社開発している組織は極めて少なく、OSS に依存することが大半です。 運用に伴うありとあらゆるツールを人の手で検査していくのは現実的でないため、セキュリティ監査のプロセスを如何に自動化していくかが重要なポイントとなります。
Software Delivery Shield
ソフトウェアの開発とデリバリに関係するコード、人、システム、プロセス全体でソフトウェアサプライチェーンを保護する GCP マネージドサービス
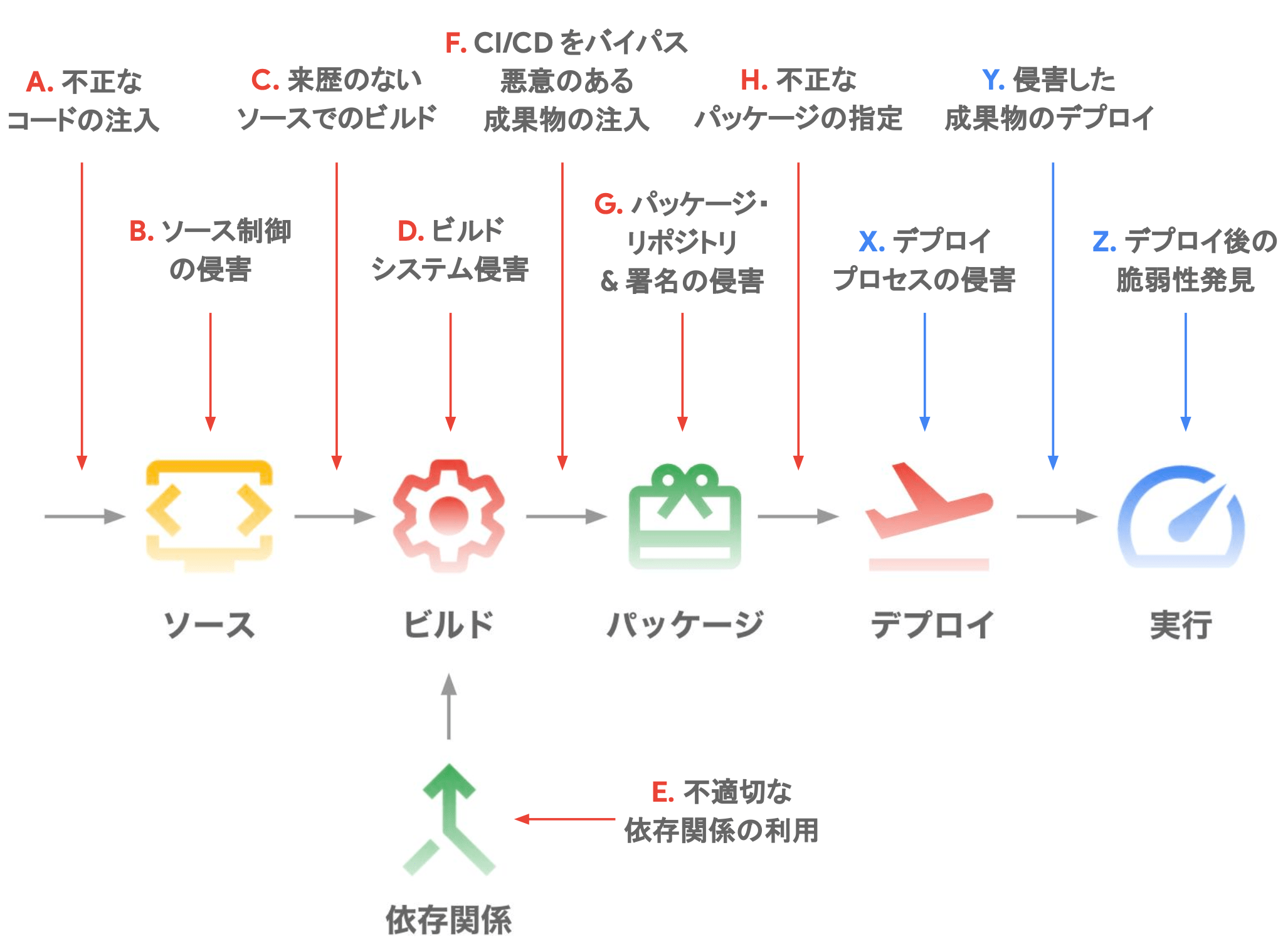
A - H:SLSA(Supply chain Levels for Software Artifacts)X - Z:Software Delivery Shield- で独自に脅威を定義して対策を実施
5 つの分野に分けて対策を実装
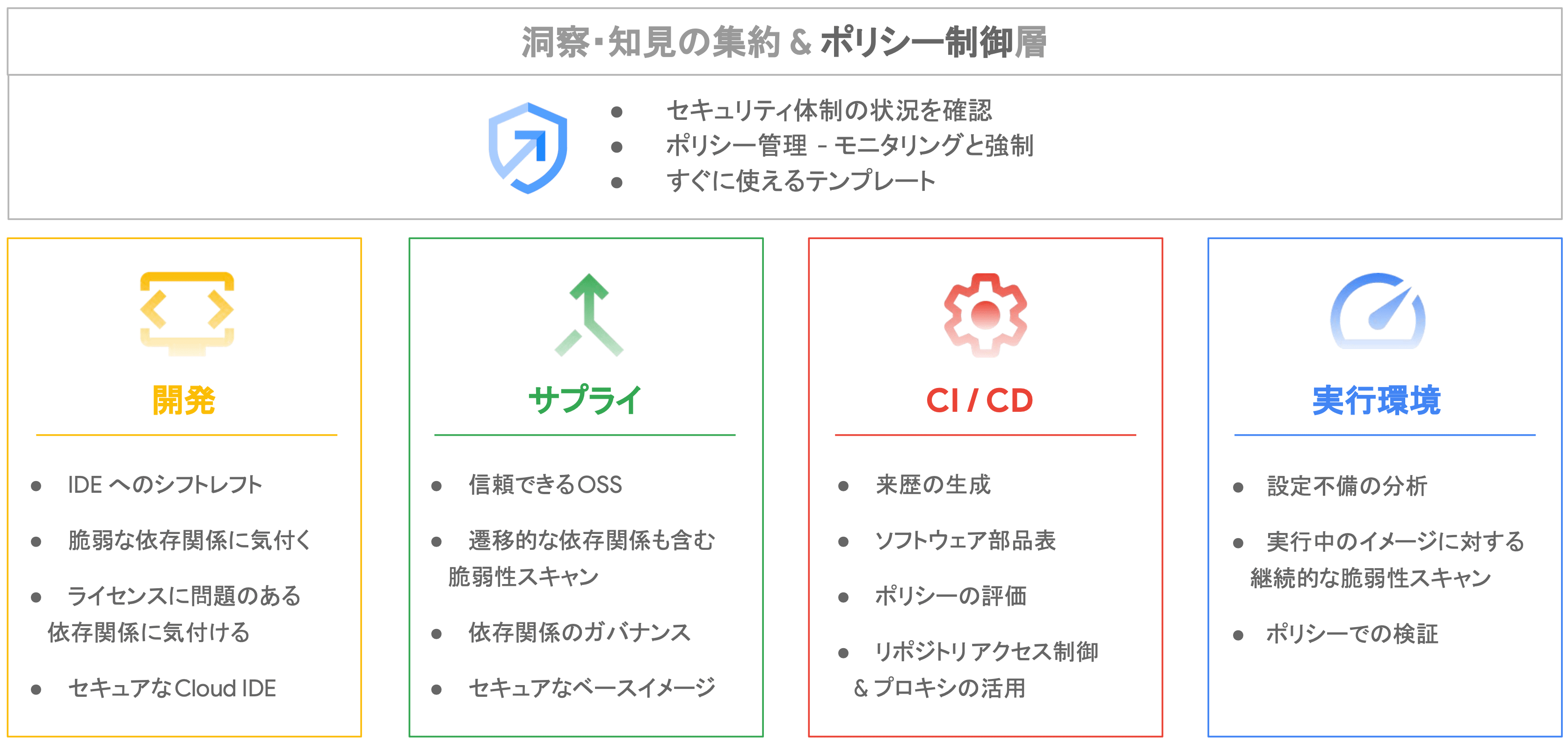
- 開発:ソース
- サプライ:依存関係
- CI/CD:ビルド・パッケージ・デプロイ
- 実行環境
- ポリシ
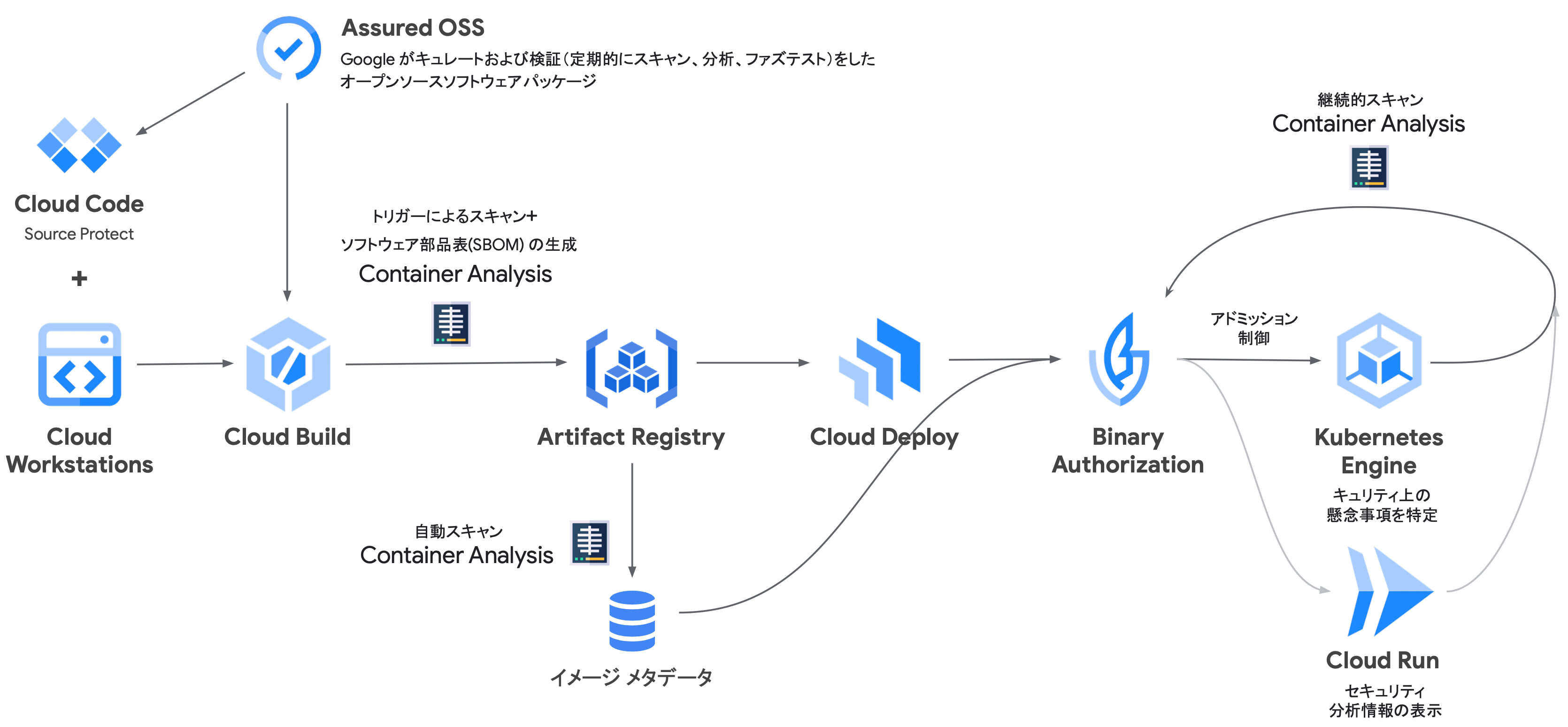
Software Delivery Shield を構成する GCP のサービス群
Software Delivery Shield の利点
- 認知
- 全体的な態勢を深く理解して信頼を積み重ねる
- 対策
- Google のベストプラクティスに基づいて修正
- セキュリティのベストプラクティスをプロセスに組み込める
- 自動化
- 自動化とポリシを通じて持続可能な方法で安全基準を設定
- 監査
- 情報に基づいた意思決定を行い、組織のコンプライアンスとセキュリティ体制を検証できる
- 認知
SLSA レベル 1(ビルドパイプラインの定義)
- ソフトウェアアーティファクトがビルドパイプライン経由で生成されたことを示す
- 最初のステップとして、基本的なビルド定義が求められる
SLSA レベル 2(ビルドパイプラインのセキュリティ強化)
- レベル 1 の要件に加えて、ビルドサービスが信頼できる方法で実行されることを保証
- 改ざん防止のための少なくとも信頼されたソースの使用等が含まれる
SLSA レベル 3(ソースとビルドの検証)
- レベル 2 の要件に加えて、ビルドプロセスとツールチェーンが厳密に管理され、セキュリティが強化されることを求める
- ビルドがすべての入力データの完全性と信頼性を検証することを含む
SLSA レベル 4(エンドツーエンドのセキュリティ)
- レベル 3 の要件に加えて、最高レベルのセキュリティ標準を満たす必要がある
- ビルド環境が完全に隔離され、厳密な監査と制御が行われることを保証
SLSA(Supply chain Levels for Software Artifacts) とは、Google が主導で開発し、2021 年に公開されたソフトウェアサプライチェーンのセキュリティと完全性を保証するためのフレームワークです。 ソフトウェアの開発からリリースまでの過程でセキュリティリスクを減らすために、ベストプラクティスとなる基準を提供しています。 SLSA は、レベル 1 からレベル 4 までの 4 段階 で構成されており、各レベルはセキュリティと完全性に対する要求の厳しさに応じて異なります。
GCP では、サプライチェーン攻撃に対し、SLSA と Google Cloud の Software Delivery Shield というソリューションを用いることで『開発』『サプライ』『CI/CD』『実行環境』と、これら 4 つを統括する『ポリシ制御層』の 5 つの分野に分けてセキュリティ対策を実施することができます。
依存関係とアーティファクトのセキュリティ改善
- Assured Open Source Software
- Artifact Registry & Container Analysis
- 250 を超える Java と Python のキュレートおよび検証済みパッケージ(特定の基準に基づいて選ばれ、評価され、整理されたソフトウェアパッケージ)の提供
- 各種リポジトリの利用
- Private repos
- Remote repos:upstream の依存関係をキャッシュし、脆弱性もスキャン
- Virtual repos:一つのエンドポイントで Private と Remote を検索順序つきで統合
- Maven と Go の脆弱性スキャン
- ソフトウェア部品表(SBOM:Software Bill of Materials)生成
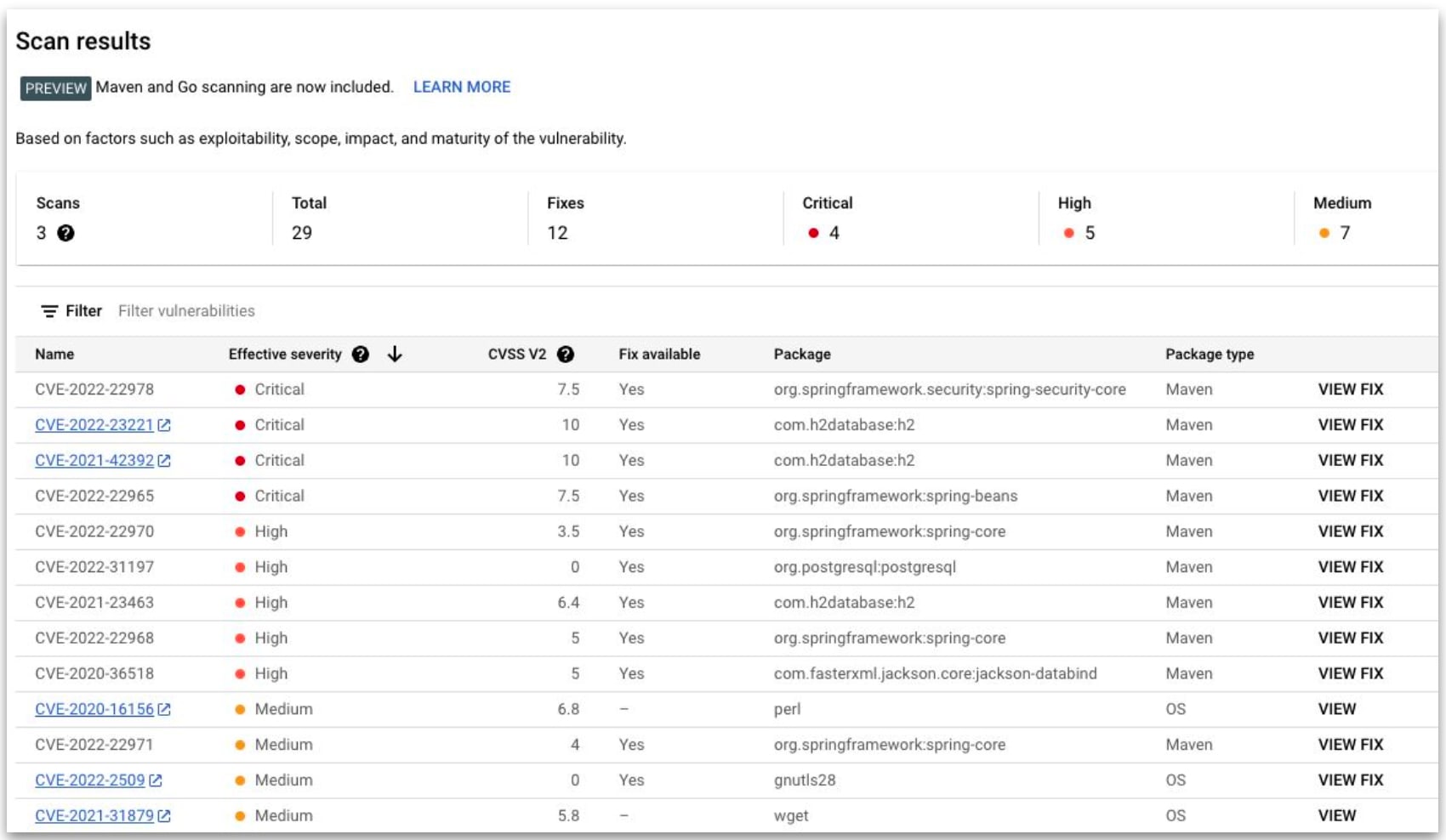
- SBOM の生成
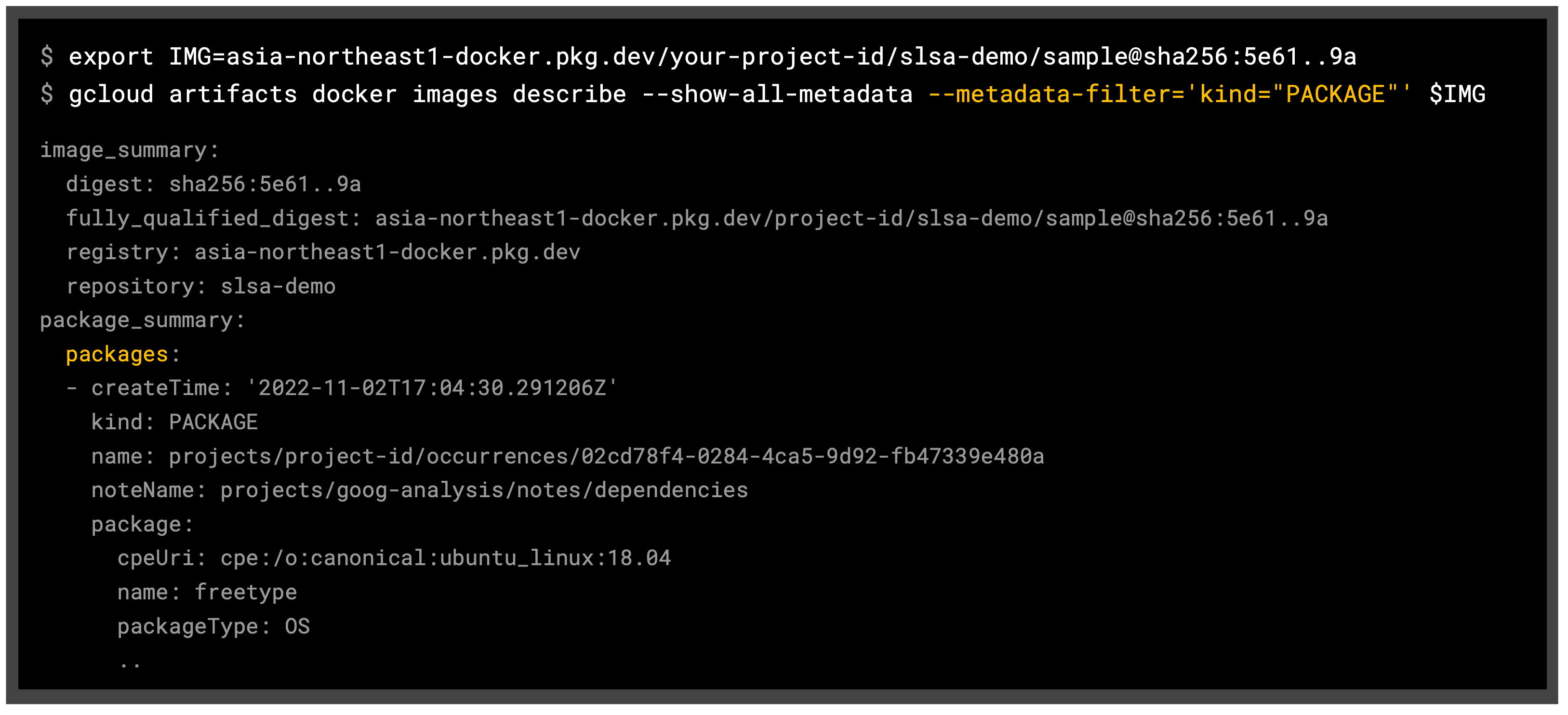
SBOM(Software Bill of Materials) とは、製品に含むソフトウェアを構成するコンポーネントや互いの依存関係、ライセンスデータ等をリスト化した一覧表です。 主に、OSS のライセンス管理や脆弱性の管理、ソフトウェアサプライチェーンのリスク管理等の用途で利用されます。
GCP では、Assured Open Source Software と Artifact Registry の Container Analysis という機能を用いることで、SBOM を作成することができます。 Container Analysis には、Artifact Registry に対する Automatic scanning(Container Scanning API)と、Artifact Registry およびローカルイメージに対する Manual scanning(On-Demand Scanning API)があります。
実行時のセキュリティ分析
- GKE security posture
- GKE:継続的な実行時脆弱性・設定スキャン
- Cloud Run security insights
- Cloud Run:セキュリティ分析情報の表示
- 可視化指標
- ターゲットレベル
- 脆弱性
- ビルド来歴
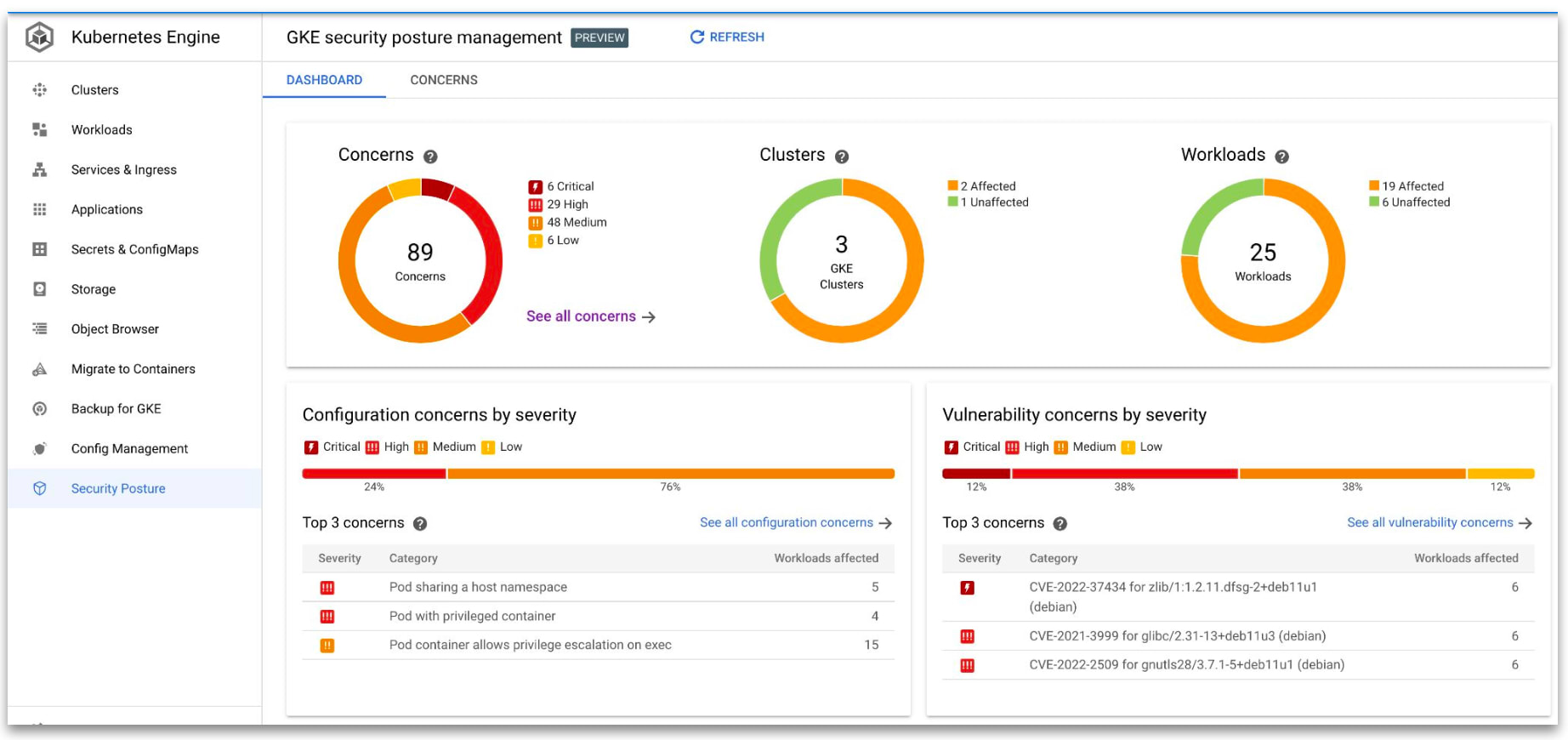
GCP の主要なコンテナオーケストレーションツールである GKE と Cloud Run には、それぞれ GKE security posture と Cloud Run security insights という脆弱性スキャンツールが用意されています。 これらのソリューションを用いることで、システムの潜在的な脅威をセキュリティポスチャダッシュボードから確認することができます。
GKE Fleet Rollout Sequencing
- GKE クラスタにおいて Fleet で編成されたロールアウト順序でオートアップグレードする仕組み
- アップグレードするクラスタを環境毎にグルーピング
- 依存関係を持たせることで段階的なオートアップグレードが可能に
- 例:開発環境 → ステージング環境 → 本番環境

- About cluster upgrades with rollout sequencing - Qualify upgrades across environments
クラスタアップグレードと脆弱性情報の自動通知
- Pub/Sub を用いてクラスタ構成に関連するイベント情報を通知
- 任意の Pub/Sub トピックに対し、アップグレードや脆弱性に関する通知メッセージを送信
- SecurityBulletinEvent
- クラスタに影響のる脆弱性情報を通知
- UpgradeAvailableEvent
- 新バージョンが利用可能になった時に通知
- マイナーバージョン:2-4 週間前
- パッチバージョン:1 週間前
- UpgradeEvent
- アップグレードが開始されると通知(自動、手動問わず)
- Types of upgrade notifications

- GKE release schedule
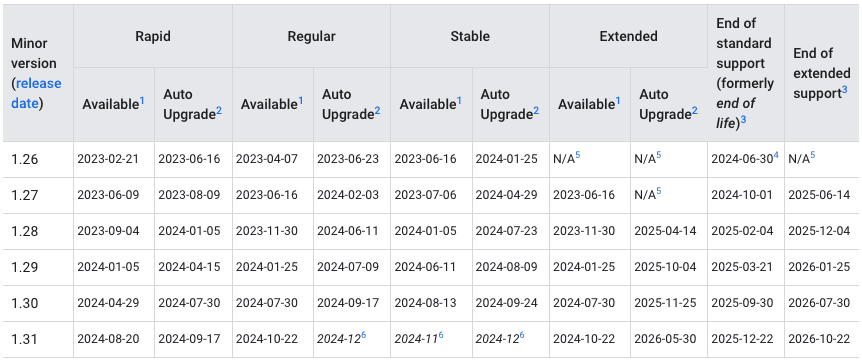
Kubernetes は約 3 - 4 ヶ月毎、年に約 3 回と、非常に早いスピードでマイナーバージョン(v1.28 → v1.29)のアップグレードが入ります。 これらのアップグレードには、セキュリティパッチや既存 API の廃止といった重要な変更も含まれているためバージョン追従を心がけなければなりません。
また、GKE 等のマネージド Kubernetes では EOL に加え、サポート期間についても考慮する必要があるため、クラスタの管理者はアップグレードのタイミングを常に把握することが重要となります。
GCP では、GKE と PubSub を組み合わせることで、クラスタのアップグレードや脆弱性情報のイベントを通知することができます。
ワークロード構成スキャン
- ワークロードの構成を自動的にスキャンして Kubernetes のベストプラクティスに沿っていない、潜在的なリスクがあるワークロードを報告
- 発見された懸念事項は Cloud Console ダッシュボード や Cloud Logging のログエントリから確認可能
- 検知するリスクの例
- ホストの Namespace 共有
- 特権コンテナの利用
runAsNonRoot(コンテナのプロセスが root で動いてるかを確認する機能)が有効になっていない- 権限昇格が可能になっている
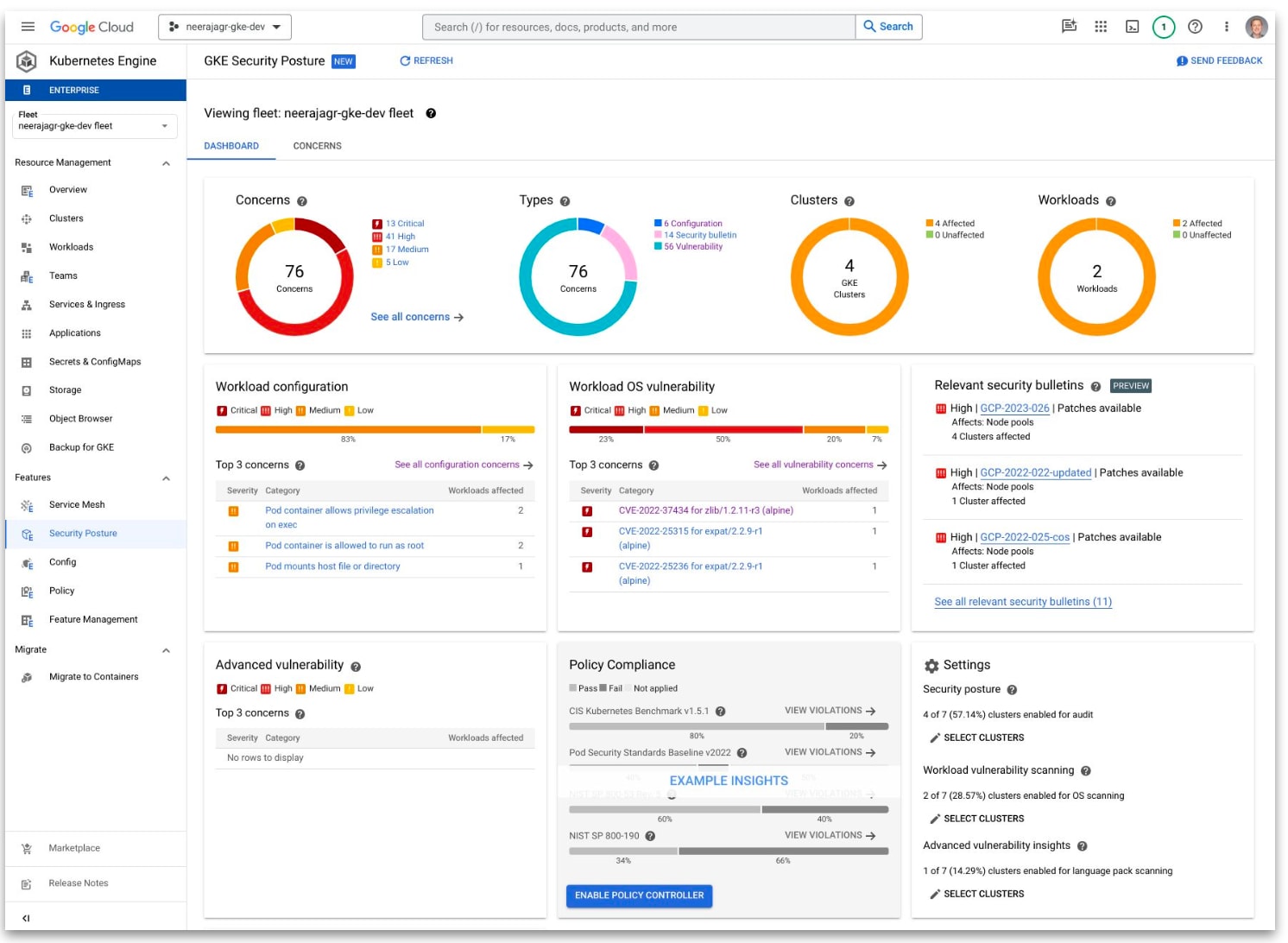
GKE には、Kubernetes の ベストプラクティス に反しているワークロードを自動的に検出、ダッシュボードに可視化してくれる機能が備わっています。 個々のコンポーネントを精査するのは非常に骨が折れる上、ポリシを都度整備してセキュリティ監査を実施するのは非常に大変ですが、GKE ではこれらの機能がマネージドに組み込まれているため非常に便利です。
GKE Sandbox
- gVisor(軽量な User-space Kernel)による Isolation により 信頼できないワークロードからホストカーネルを保護
- gVisor の位置付け
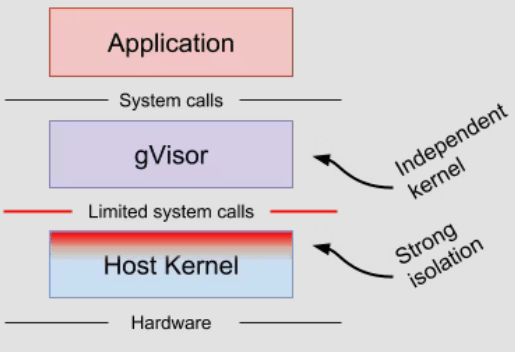
- https://github.com/google/gvisor
- Docker アプリケーションからのシステムコールを gVisor が一度受け取り、それをホストカーネルに渡す
- VM 上にあるコンテナが対象で、コンテナ毎に軽量カーネルを構築
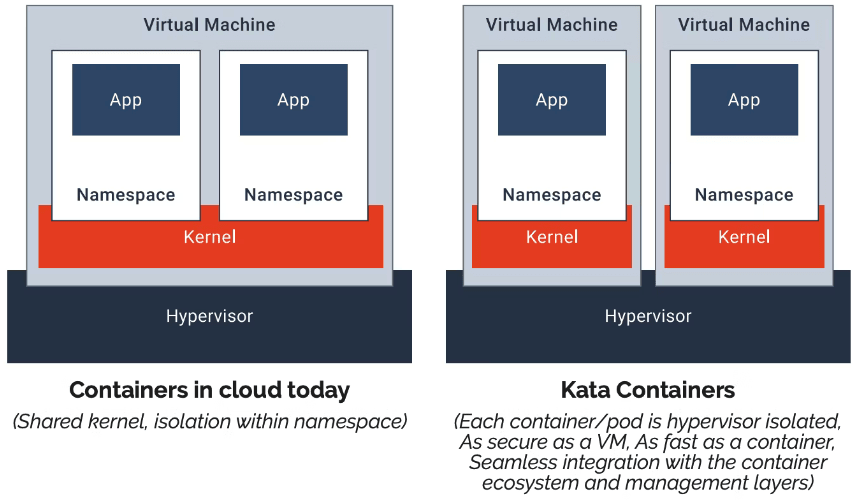
- 軽量カーネル無しのコンテナと同程度のパフォーマンス(
< 100ms boot time)を発揮できる [参考]
- gVisor の位置付け
- コンテナからの syscall をインターセプトして、ホストカーネルへの直接アクセスを制限
- ホストアクセスを強く制限することによりホストへのエスケープリスクを低減し、他コンテナ / テナント環境での影響を極小化
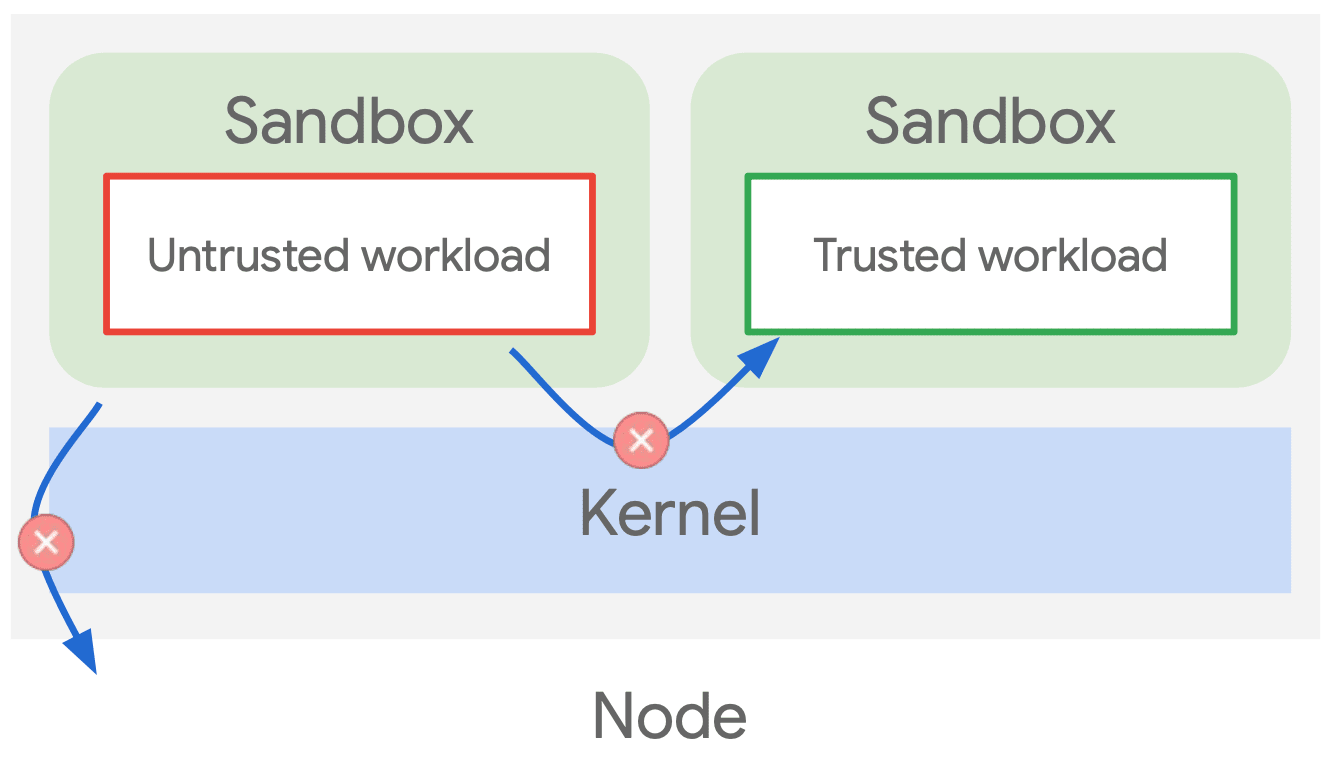
Data-Plane のセキュリティ対策には、gVisor を GKE Sandbox 機構として使用することができます。 gVisor は、ユーザ空間とカーネル空間の中間に位置し、ユーザ空間アプリケーションからのシステムコールを、一度 gVisor でフックしてからカーネルイベントを発行します。 この仕組みにより、カーネルに対する操作を制御し、GKE Data-Plane を保護します。
また、gVisor がユーザ空間からのリクエストをフック・処理した場合でも、軽量カーネル無しのコンテナと同程度のパフォーマンスを発揮できるとされています。
Container-Optimized OS(COS)
- コンテナ化されたアプリケーションの実行のみをサポート
- Google Kubernetes Engine において、デフォルトでノードに使用される OS イメージ
- コンテナ実行に最適化されたセキュアかつ軽量な OS
- 高速な起動
- 最低限のプロセスのみ動作
- 読み取り専用のルートファイルシステム
- セキュリティが強化されたカーネル
- サービス Listen ポートの最小化
- ...etc.
- COS を利用することにより、アタックサーフェス(サイバー攻撃の対象となりうる IT 資産や攻撃点および攻撃経路) を小さくすることが可能
- Container-Optimized OS Overview
Container-Optimized OS(COS)は、コンテナの実行に対して最適化された Compute Engine VM 用の OS イメージです。 COS は、Google によってオープンソースの Chromium OS プロジェクトに基づいて維持・管理されています。 また、COS はコンテナを実行するのに必要最低限の機能のみを備えているため、アタックサーフェス を小さくすることができます。
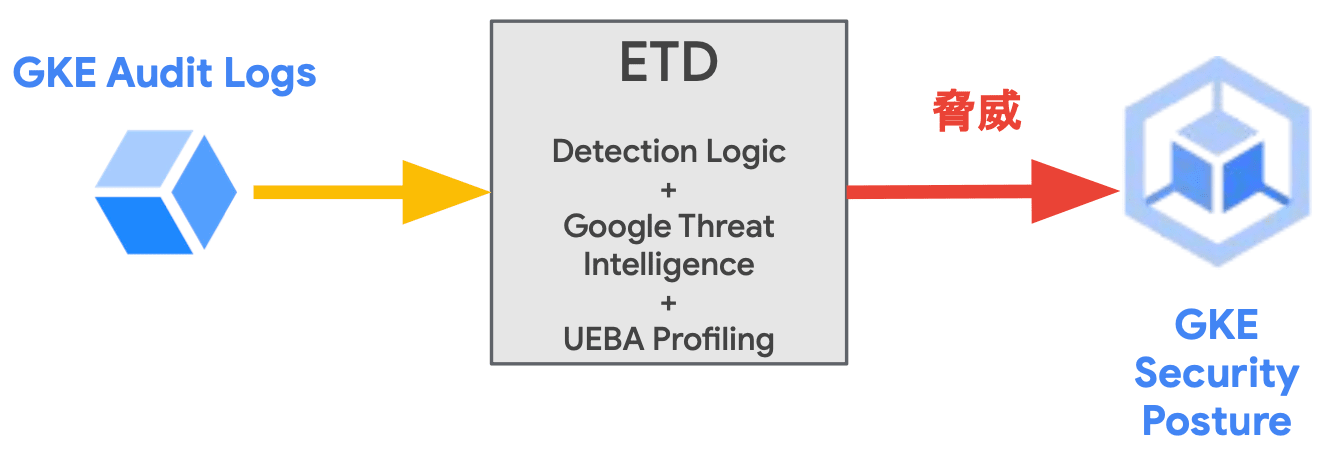
GKE Threat Detection
- GKE の監査ログを基に GKE クラスタ上の脅威を検出
- 複数クラスタ環境に継続的にスキャンを実行してアクティブな脅威を迅速に検出
- RBAC の変更や特権コンテナのデプロイ等のイベントを検出
- 検出された脅威は MITRE ATT & CK フレームワーク より分類される
- Security Command Center Premium Tier でも脅威情報の確認が可能
MITRE ATT & CK フレームワーク(MITRE Adversarial Tactics, Techniques, and Common Knowledge Framework)
- サイバー攻撃の戦術(Tactics)、技術(Techniques)、および一般的な知識(Common Knowledge)を体系的に整理・提供するための包括的なナレッジベース
- サイバー攻撃者の行動を理解し、防御策を強化するためのツールとして広く使用される
GKE Threat Detection(GKE の脅威検出機構)は、GKE Enterprise edition でのみ利用が可能な高度なセキュリティポスチャダッシュボードです GKE クラスタが Fleet に登録されると、GKE Threat Detection は、Cloud Logging の GKE 監査ログをクラスタとワークロードの脅威に関する事前定義ルールのセットと比較して評価します。 この時、脅威が検出されると、ダッシュボードに検出結果が表示され、脅威の説明、潜在的な影響、脅威を緩和するための推奨アクションを確認することができます。
Security Command Center(SCC)
- 実行中システムへの脅威を検出
- よくある脅威を広く検知
- 頻出の攻撃に対しては検出器をプリセット
- Added Binary Executed
- New Library Linked
- Reverse Shell
- ...etc.
- 頻出の攻撃に対しては検出器をプリセット
- GCP マネージドサービスとの統合
- SCC に結果を表示
- 各種イベントは Operations へ
- Cloud security and risk management for multi-cloud environments
Security Command Center(SCC)は、Google Cloud 上で使用しているサービスの脆弱性や脅威となりうる設定を検知することができる最も基本的なサービスです。 検知された脆弱性や脅威は、Google Cloud のダッシュボードに表示したり、Pub/Sub を用いて任意のツールにメッセージをパブリッシュすることができます。
ただし、SCC は Google Cloud の組織単位で有効にできるサービスであるため、Google Cloud プロジェクトのみを使用しているユーザは利用することができません。
Container Threat Detection(KTD)
- SCC の Premium Tier を利用している場合のみ使用可能
- Container Threat Detection は複数の検出機能 / 分析ツールおよび API で構成
- 動作情報(COS のカーネルモジュールに関する変更)を収集するためには GKE クラスタのノードには最新の COS が必要
- データとコンテナを識別し、DaemonSet を経由してデータが送られる
- カーネルと Detector Service のすべてのデータはエフェメラルで永続化されない
- 検出されたものは SCC と Cloud Logging へ自動的に書き込まれる
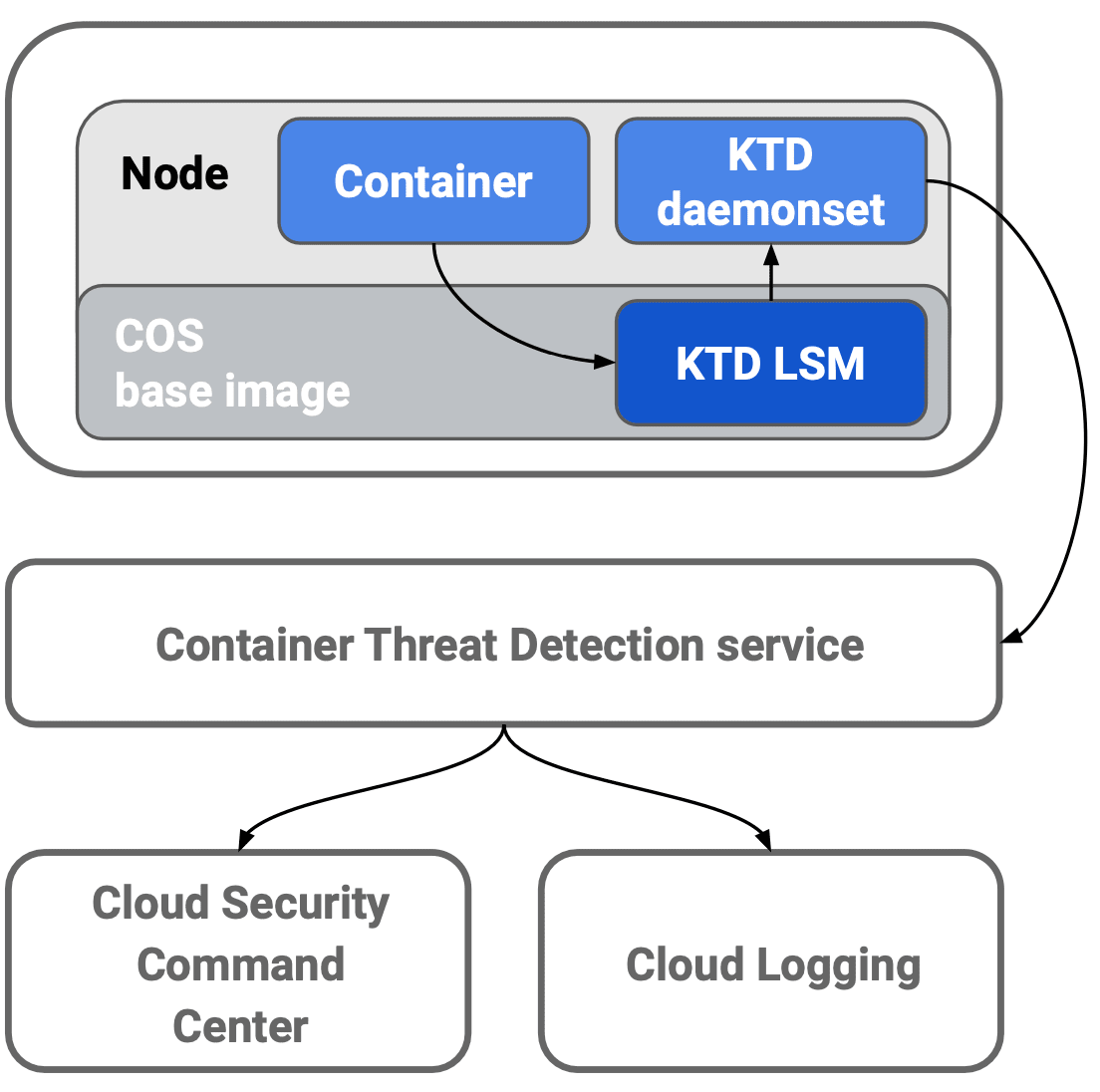
- LSM(Linux Security Module):Linux Kernel への変更を検知
- Container Threat Detection overview
Container Threat Detection(KTD)は COS ノードイメージの状態を継続的にモニタリングする SCC Premium Tier の組み込みサービスです。 KTD はリモートアクセスを試みてすべての変更を評価し、リアルタイムにコンテナランタイム攻撃を検出します。 また、検出された脅威は、SCC や Cloud Logging でアラートを表示することができます。
KTD は不審なバイナリやライブラリ等の検出機能も備えており、内部的には自然言語処理(NLP:Natural Language Processing)を用いて悪意のある bash スクリプトを検出しているようです。
ハンズオン
ハンズオンセッションでは主に CI/CD パイプラインにおけるコンテナイメージの脆弱性診断を実施しました。
- 脆弱性スキャン:CI/CD パイプライン内でコンテナイメージ脆弱性スキャンを自動実行
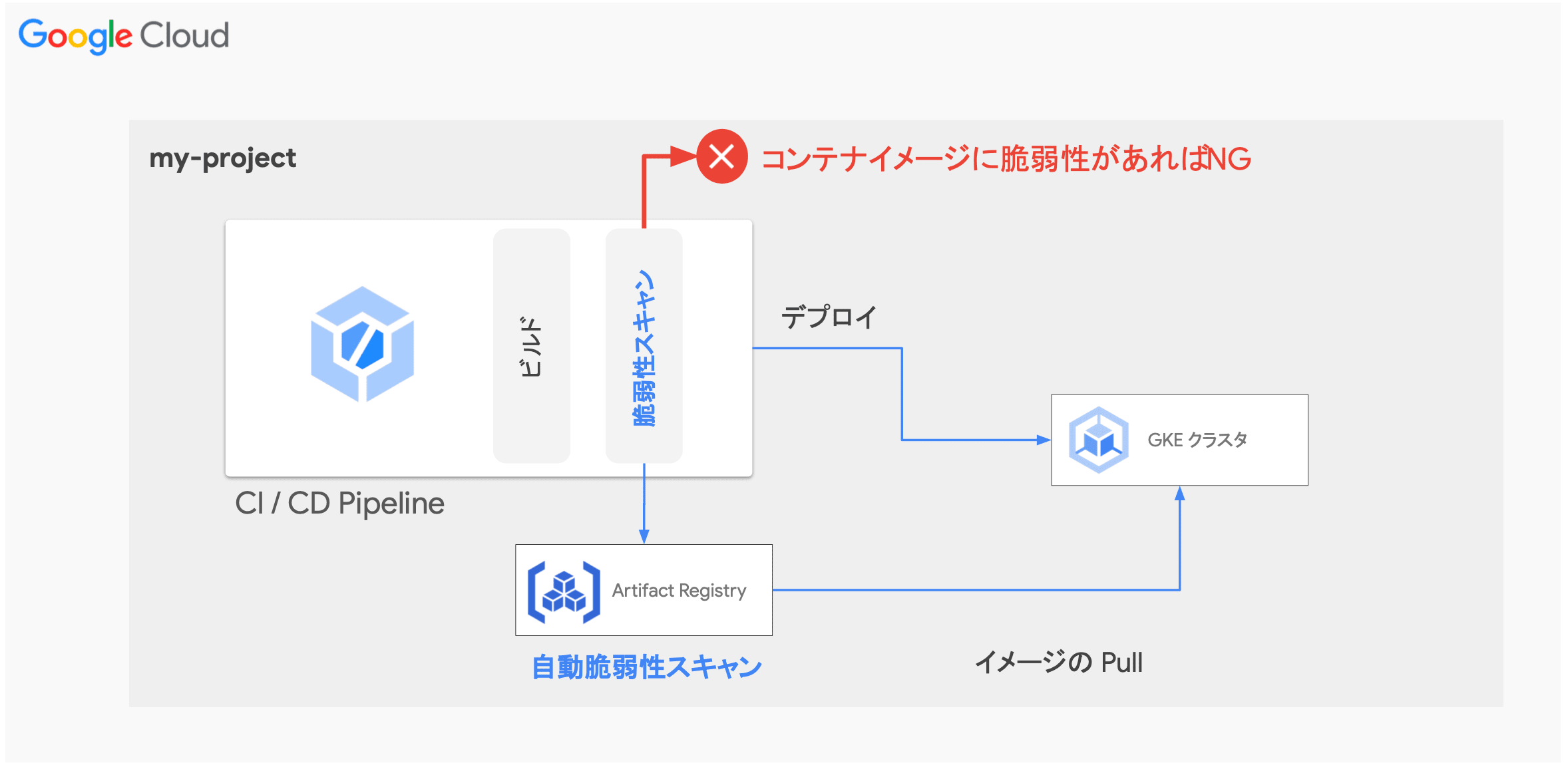
- 継続的脆弱性スキャン:GKE 上で実行されているイメージの脆弱性スキャン
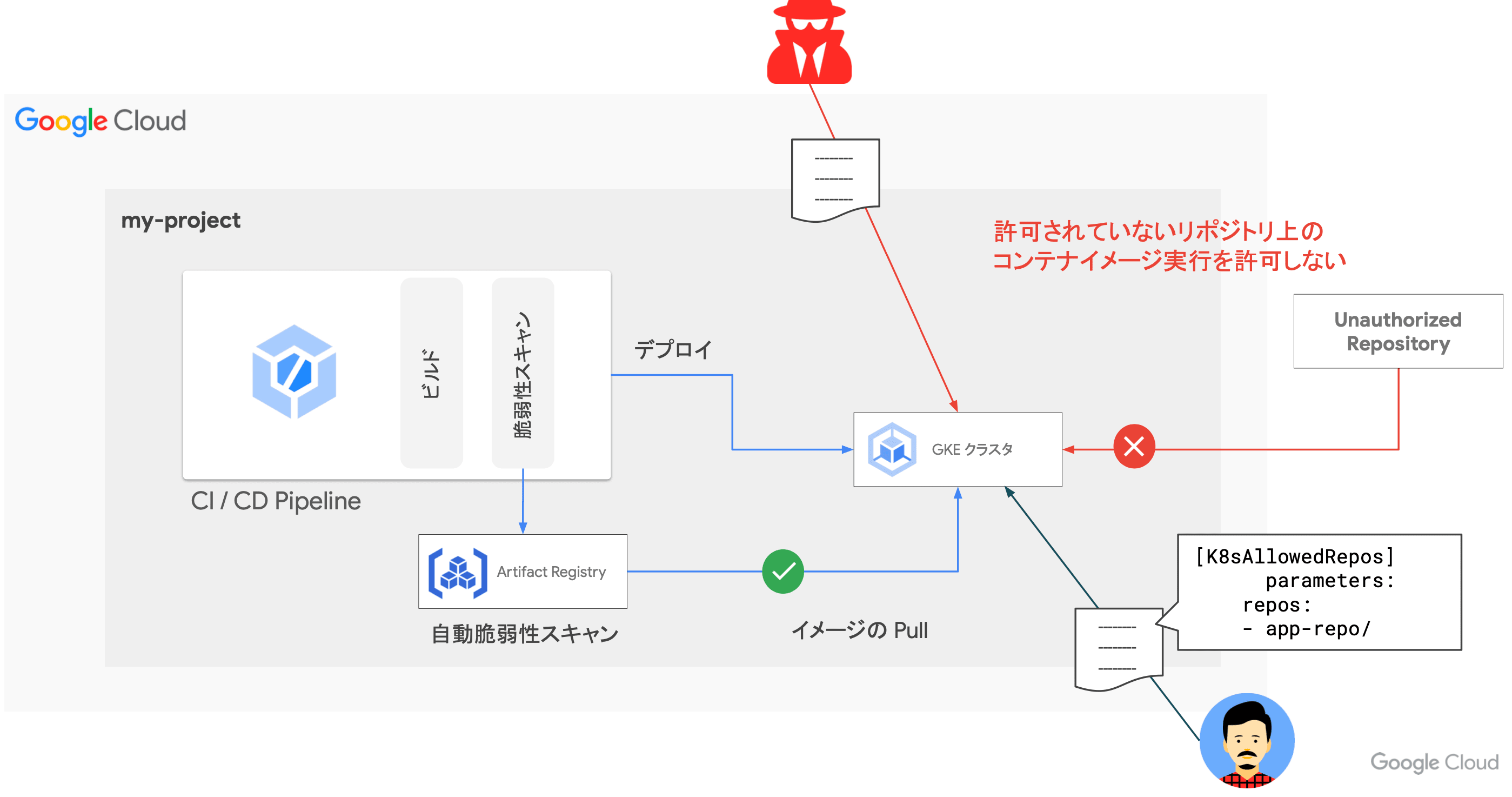
- Policy Controller:許可されたリポジトリ上のイメージのみデプロイを許可

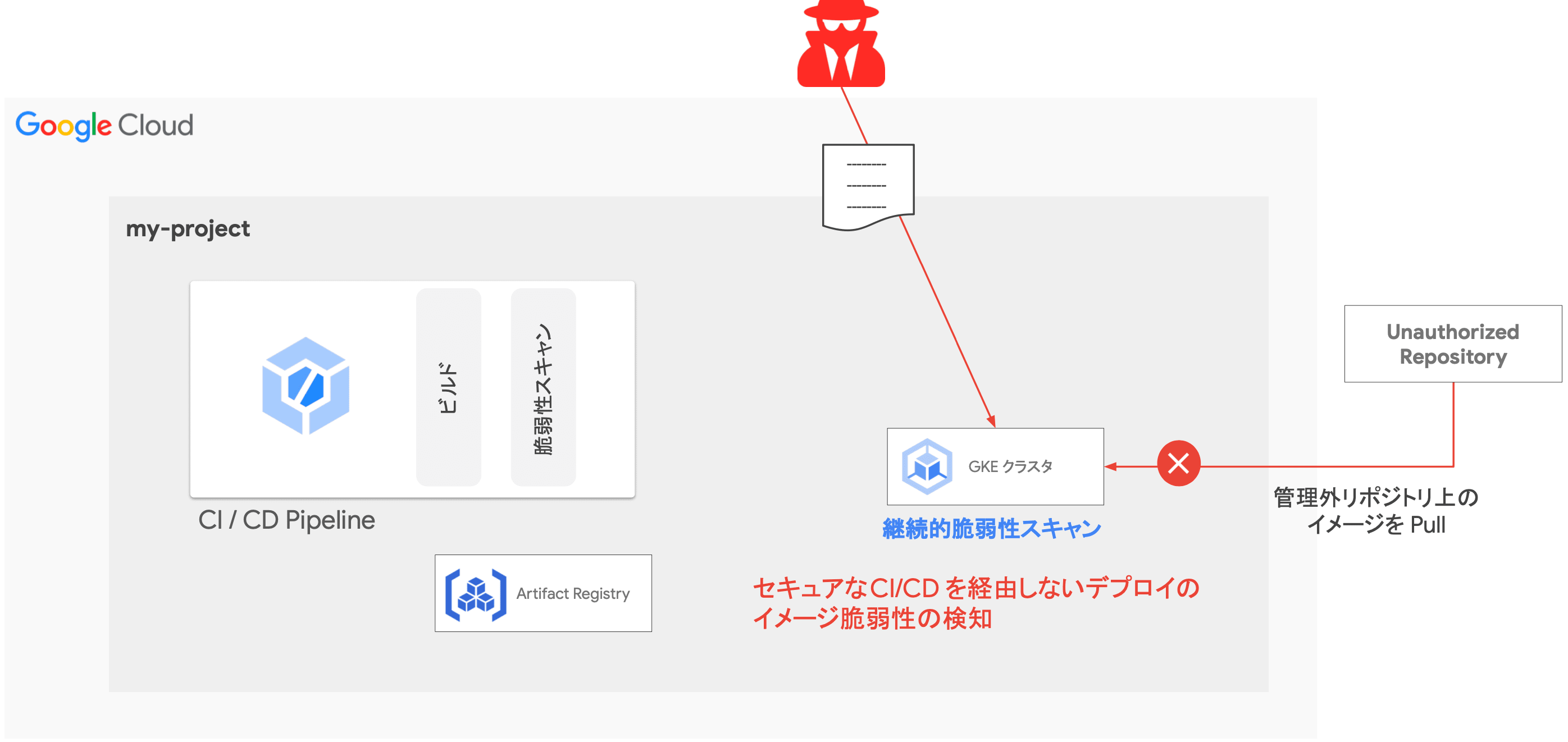
また、クラスタに脆弱性を含んだ Pod をデプロイしてダッシュボードから脅威レベルを確認しました。
- 不適切な設定の Pod の検知
- クラスタ全体にセキュリティガードレールを敷き、不適切な設定のコンテナデプロイを防止する
- 例:
/のホストパスを Pod にマウントしようとした場合に、Policy によりブロックする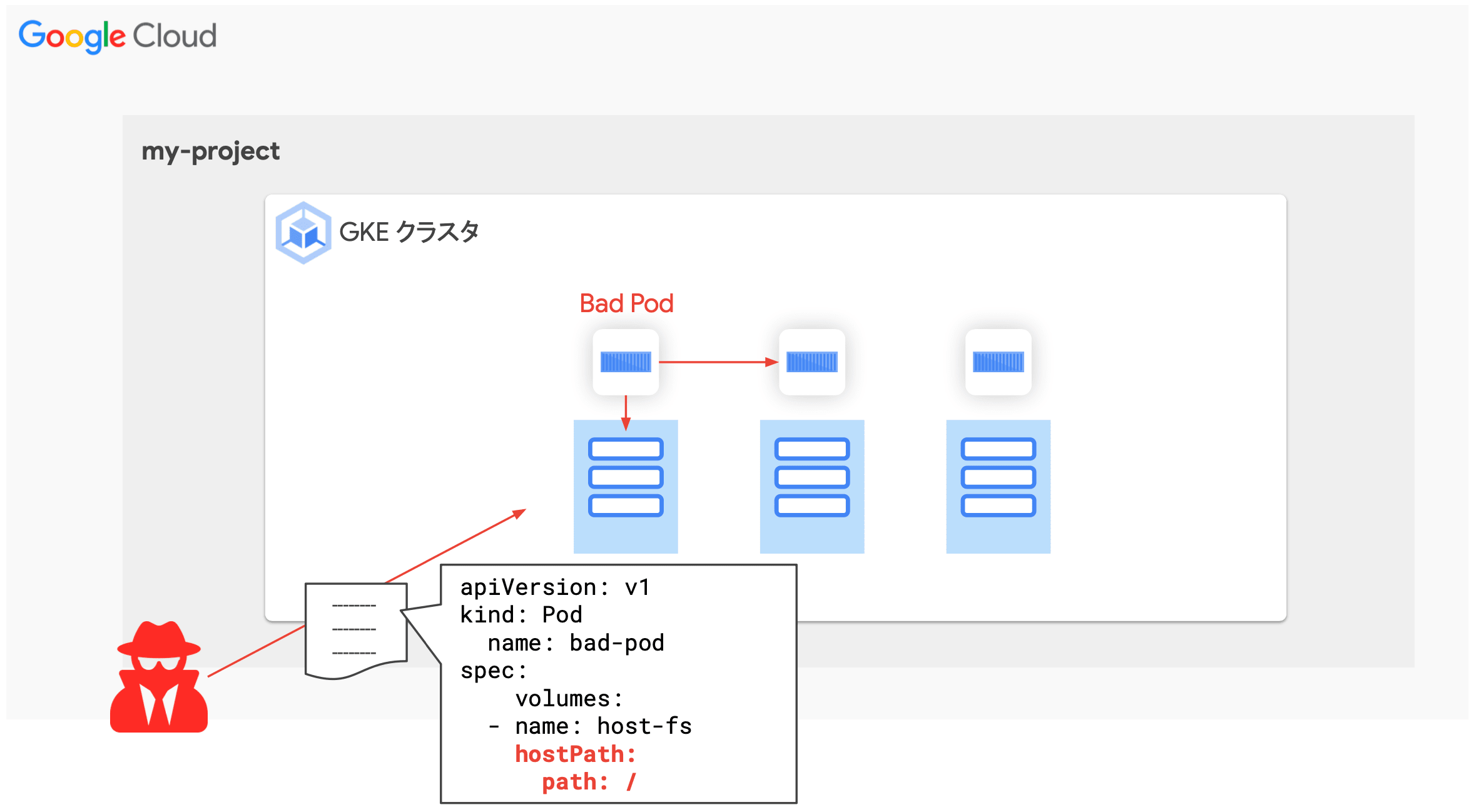
- Policy Controller による不適切な設定のコンテナデプロイの防止
- 信頼されていないレジストリから Pull したイメージに対して脆弱性検知を実施
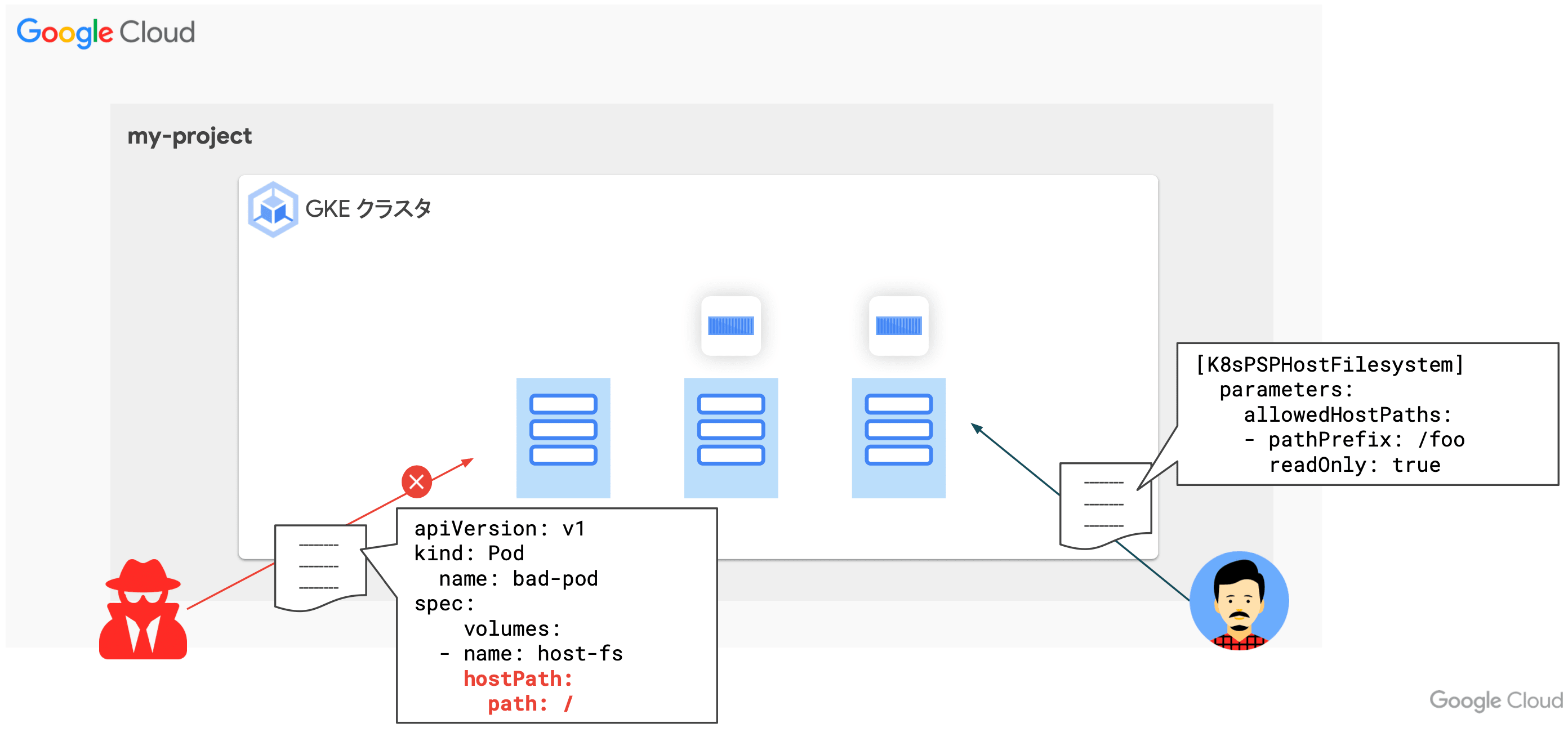
- 信頼されていないレジストリから Pull したイメージに対して脆弱性検知を実施
CiliumClusterwideNetworkPolicyリソースによるネットワークレベルでの制御- クラスタ全体の Network Policy を設定し、不要な通信の発生を防ぐ
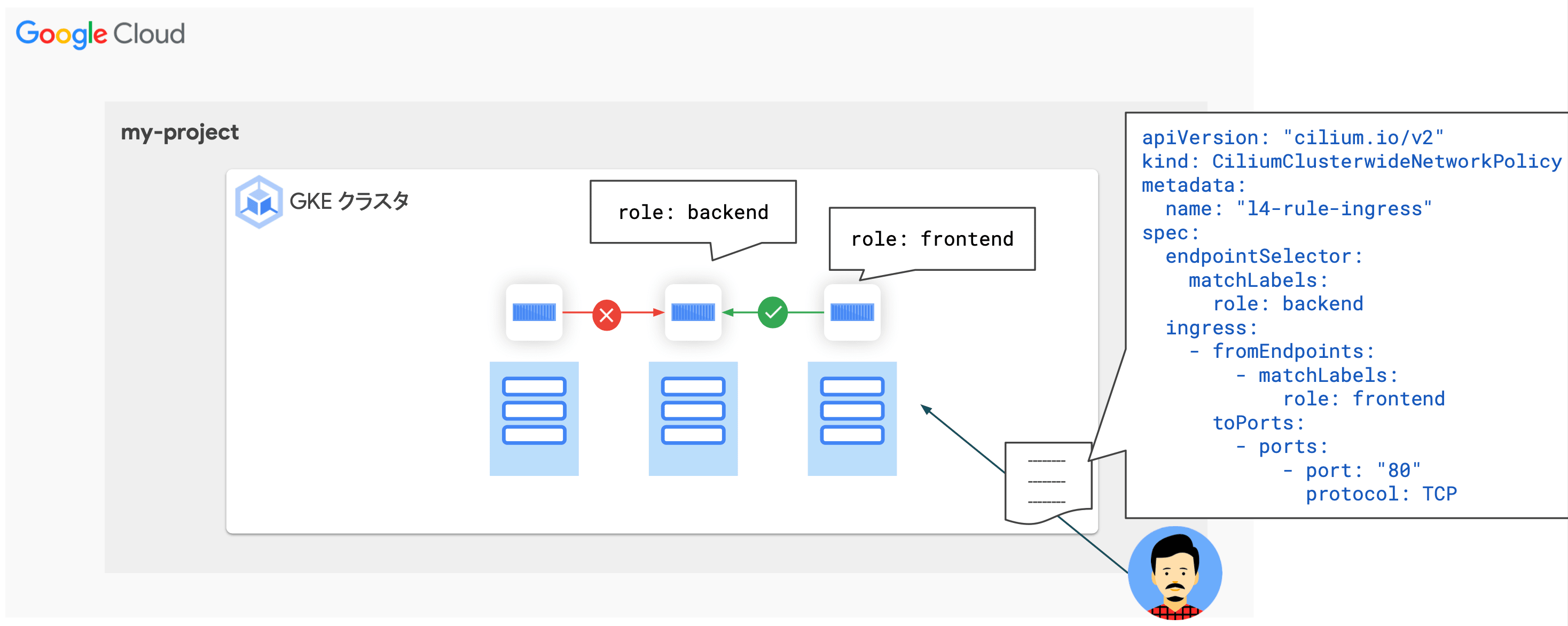
- クラスタ全体の Network Policy を設定し、不要な通信の発生を防ぐ
- ハンズオンでの確認
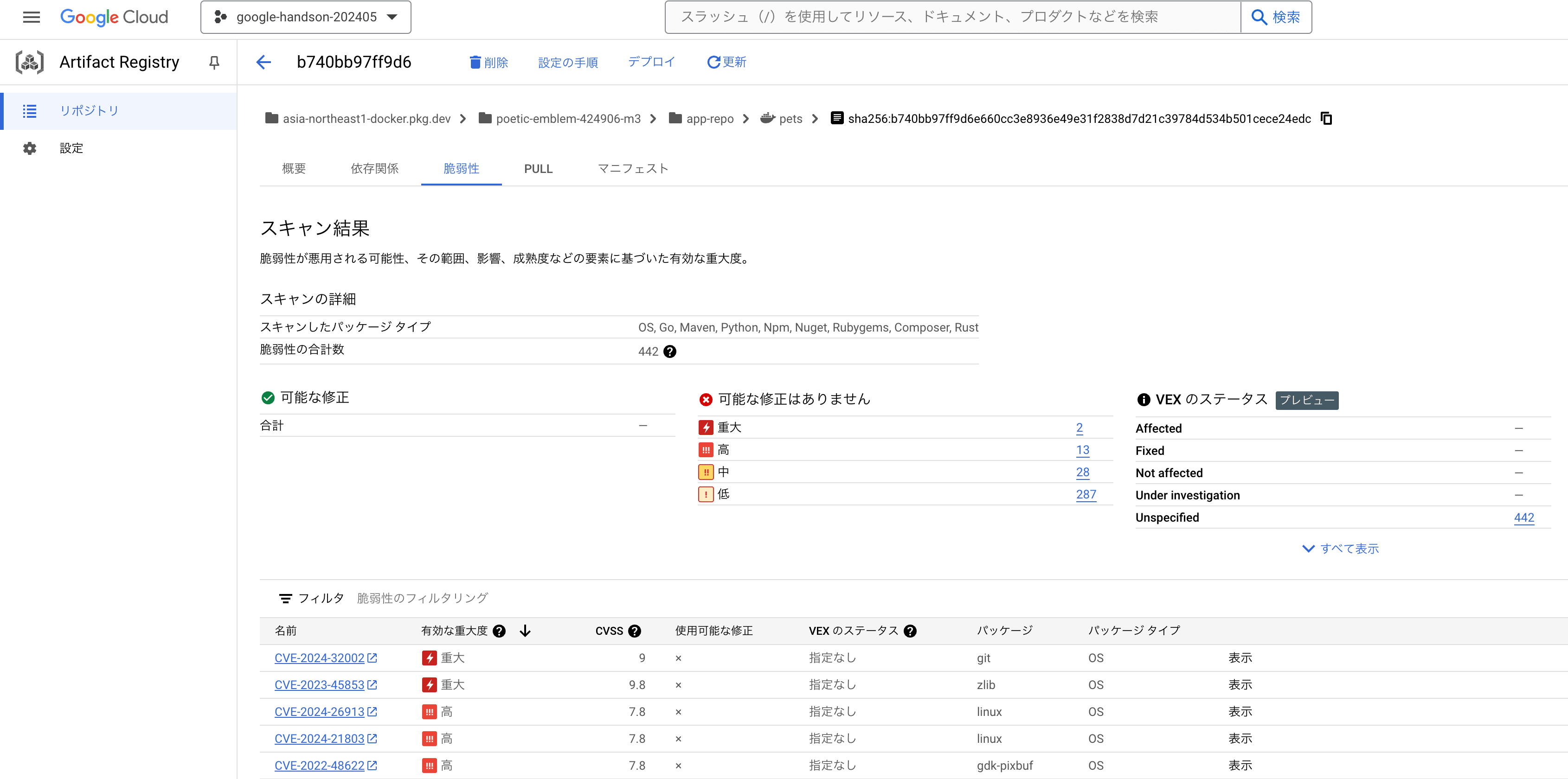
- 【Artifact Registry】Pod の脆弱性診断(スキャン)結果を確認できる
- 【Artifact Registry】CVE に基づき懸念されるセキュリティ事項を確認できる
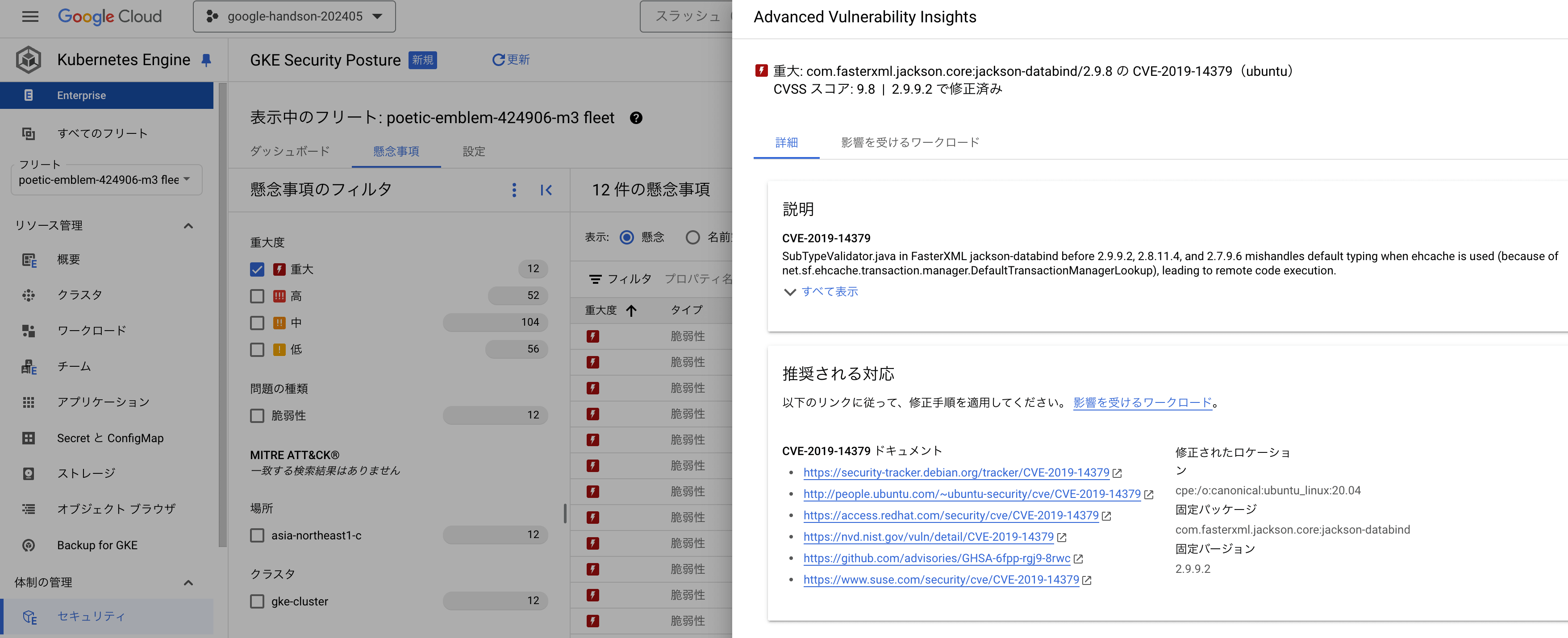
- 【Artifact Registry】Pod のリスクを説明し、具体的な対応案を確認できる
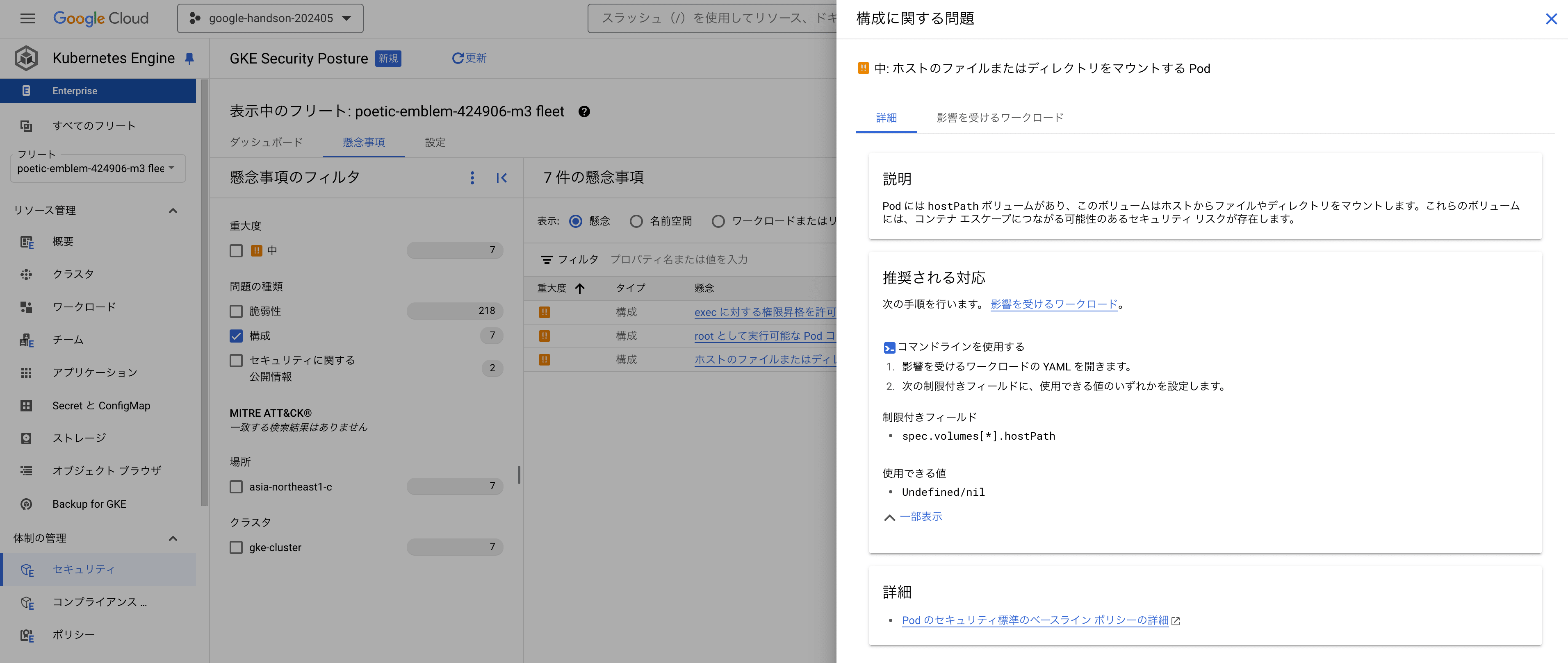
- 【Artifact Registry】Pod の脆弱性診断(スキャン)結果を確認できる
Day 3 まとめ
Day 3 では、プラットフォームエンジニアリングにおける "ガードレール" にフォーカスした内容を学びました。 プラットフォームエンジニアはゴールデンパスに加え、開発者やサービス開発を安全に保護するためのガードレールも整備する必要があります。
昨今では、OSS に依存したサプライチェーンが形成されていることから、これらの脆弱性を突いた攻撃も著しく増加しています。 Google Cloud では、他のマネージドサービスと一環したソリューションの中で、セキュリティリスクの検出や通知、具体的な対策案の提示等、非常に高度な機能を提供してくれています。 既に GCP を活用して開発プラットフォームを展開しているのであれば、これらのセキュリティ検出機構群を用いることで、開発環境の安全性を高めることが可能になるかと思います。
セミナーに参加してみて
これまで何となくで理解していた Platform Engineering に対する解像度を上げることができ、非常に濃い 3 日間となりました。
中でも、Platform as a Product というワードは非常にしっくりきました。 Platform as a Product の文脈では、ユーザは開発者、プロダクトはプラットフォームとなり、開発者が開発と運用のサイクルを滞りなく回すためのゴールデンパスとガードレールを整備 します。 以前から開発者を支えるエンジニアリング手法やプラットフォームの整備に興味があったため、今回のセミナーを通じて、それらをより具体的に学ぶことができ、改めて自分の目指す世界を言語化できるようになりました。
プラットフォームエンジニアには、アプリケーションレイヤからインフラレイヤまで高度な技術力と知見が要求される上、ドキュメンテーション能力や開発組織全体を俯瞰して見れる視野の広さ、浸透力が必要になります。 今後の業務を通じてこれらの要素を身に付けられるように、日々励んでいきたいと思いました。