Grafana Alert の機能を整理してみる
- Authors
- Name
- ごとれん
- X
- @ren510dev


目次
- 目次
- はじめに
- Grafana Alert
- 3 つの主要機能
- ベストプラクティス
- Alert Rule
- Alert Rule の比較
- Recording Rule
- クエリと条件
- ラベルとアノテーション
- Alert Rule Evaluation
- Evaluation Group / Evaluation Interval
- Pending Period
- Alert Instance
- Notification
- Contact Point
- Notification Policy
- ⭐️ Grouping ⭐️
- 制約・注意
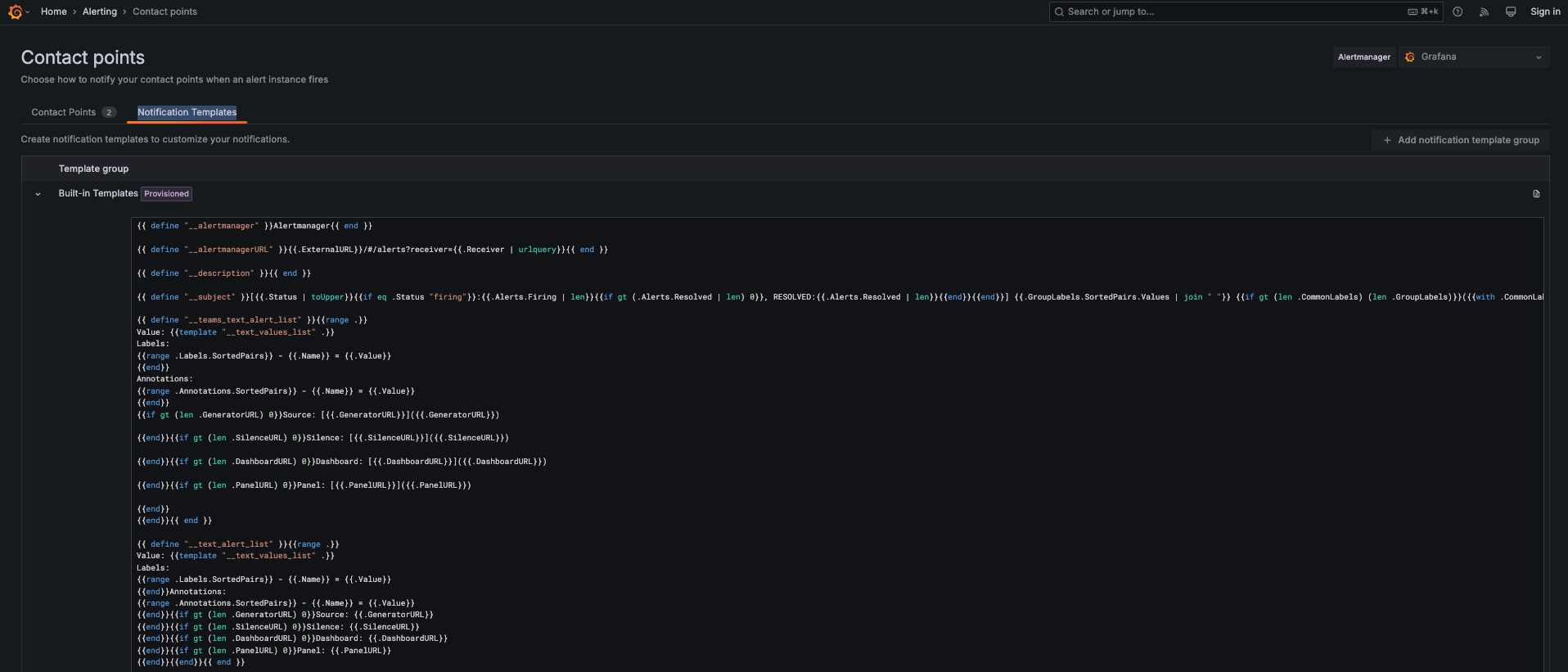
- Notification Template
- Annotations
- Labels
- Alerting History
- まとめ
- 参考・引用

はじめに
システムの監視は安定した運用を維持するために欠かせない要素です。 モニタリングの一環として「アラーティング(警告通知)」を整備することで、システムの異常を早期に検出して適切な対応を取ることでダウンタイムの回避やパフォーマンスの最適化を図ることができます。
今日、Grafana は OSS として公開されているダッシュボードツールのデファクトスタンダードとなっています。 Grafana はメトリクスの可視化やデータ分析の機能だけでなく、アラート機能を活用することでシステムの異常をリアルタイムに検出し、担当者に迅速に通知することが可能です。 最新の Grafana バージョンでは、アラート機能が大幅に強化され複雑な条件設定や通知チャネルの多様化に対応しています。
Grafana Alert は単純なクエリや閾値に加え、ポリシを設定することで通知のタイミングを柔軟に制御することができます。
今回のブログでは、Grafana Alert の機能について基本的な仕組みやアラートの制御方法について整理したいと思います。
取り上げる機能は Grafana v8.0 以降の Grafana Alert を対象としています。

Grafana Alert

Grafana Alert は Grafana に統合されている機能の一つで、監視しているデータの異常をクエリや閾値に基づいて検出し、アラートを配信する機能です。
Grafana では、ダッシュボード上のグラフやメトリクスデータを活用して特定の閾値を設定し、条件を満たした際にアラートをトリガすることができます。 Grafana Alert を活用することで、システムやパフォーマンスの異常を早期に検出して障害を未然に防ぐことが期待できます。
3 つの主要機能

Grafana Alert は定期的に Alert Rule で定義された条件を評価し、違反がある場合は Alert Instance と呼ばれるアラートそのものの実体を生成します。 Alert Instance が生成、もしくは異常状態から復帰(Resolve)した場合に、設定された Contact Point(通知先)に配信します。
また、Alert Instance には Notification Policy と呼ばれる通知に関するポリシを設定することで、アラーティングのタイミングを柔軟に制御することができます。

1. Alert Rule / Alert Instance
データリソースやメトリクスのクエリ、条件式による閾値設定等、基本的なアラーティング要素を設定・管理する機能です。 Grafana Alert は、1 つ以上のクエリ・条件式で構成される Alert Rule に基づいて、Alert Instance と呼ばれるアラートそのものの要素・実体を生成します。
Alert Instance は、Contact Point と Notification Policy に基づいて、任意の通知先およびタイミングで配信されます。
2. Contact Point
アラートの配信先を管理する機能です。 Contact Point には Email や Slack、Pagerduty 等の SaaS ソリューションの他、Webhook を用いたカスタムエンドポイントを設定することもできます。
また、Notification Template を用いることで、通知メッセージに含める項目をテンプレート化して、値を動的に変更することができます。
3. Notification Policy
アラートの通知タイミングを制御する機能です。
単一の Alert Rule で複数の Alert Instance を生成することができます。
例えば、以下のような PromQL を含む Alert Rule を定義すると、サーバの各 CPU のステータスを管理できます。
sum by(cpu) (
rate(node_cpu_seconds_total{mode!="idle"}[1m])
)

しかし、生成された Alert Instance を毎回通知しているとノイズが発生し、本当に必要な事象の把握が困難になります。
Notification Policy には、複数の Alert Instance を特定の条件でグループ化する Grouping 機能が提供されており、まとまった単位でアラーティングを制御することができます。
また、配信が不要な場合は サイレンス または ミュート の機能を用いて、通知を停止することもできます。
ベストプラクティス
Grafana Alert がこれらの機能を提供する理由については大まかに こちら で紹介されています。
効果的なアラート管理システムの設計について
- システムを適切に監視し、問題が発生する前に検知するためには適切なアラート管理システムが不可欠である
- Grafana が提唱する効果的なアラート管理の設計方法と思想に基づく実践
- 効果的なアラート管理システムを構築し、ビジネスへの影響を最小限に抑えるためには
- 監視・アラートの対象とすべき重要な指標とは?
- ビジネスにとって重要なイベントを選定する
- 頻繁すぎたり不要な通知は避け、緊急対応が必要なものに限定する
- 質を重視し、不要なアラートを減らす
- アラート・通知の整理方法
- 適切な担当者やチーム(オンコール担当者など)に適切な方法で通知を送る
- 優先度や深刻度を適切に設定する
- API や Terraform を活用し、アラート設定の自動化を進める
- 通知に含めるべき情報
- 受信者や対応者が誰なのかを考慮し、適切な情報を提供する
- 問題の特定や解決に役立つ情報を共有する
- アラートに対応するダッシュボードのリンクを提供し、迅速な問題解決を支援する
- バーンアウトを防ぐには?
- 不要なアラートを抑えるために、サイレンス / ミュート 機能や Alert Rule の評価の一時停止(Pause)機能を活用する
- Alert Rule を継続的に見直し、重複や無効なルールを削除する
- 閾値や評価ルールを定期的に見直し、調整する
Alert Rule
Alert Rule はアラーティングのタイミングを決定するルールの集合(ルールセット)です。
設定項目は大まかに 3 つあります。
- データセット(どのデータセットに対してクエリを実行するか)
- Alert Instance をトリガするための条件・閾値
- クエリがヒットしない(失敗もしくは null が返される)場合にどうするか
Grafana Alert では 2 つの Alert Rule を選択することができます。
Grafana-managed Alert Rule
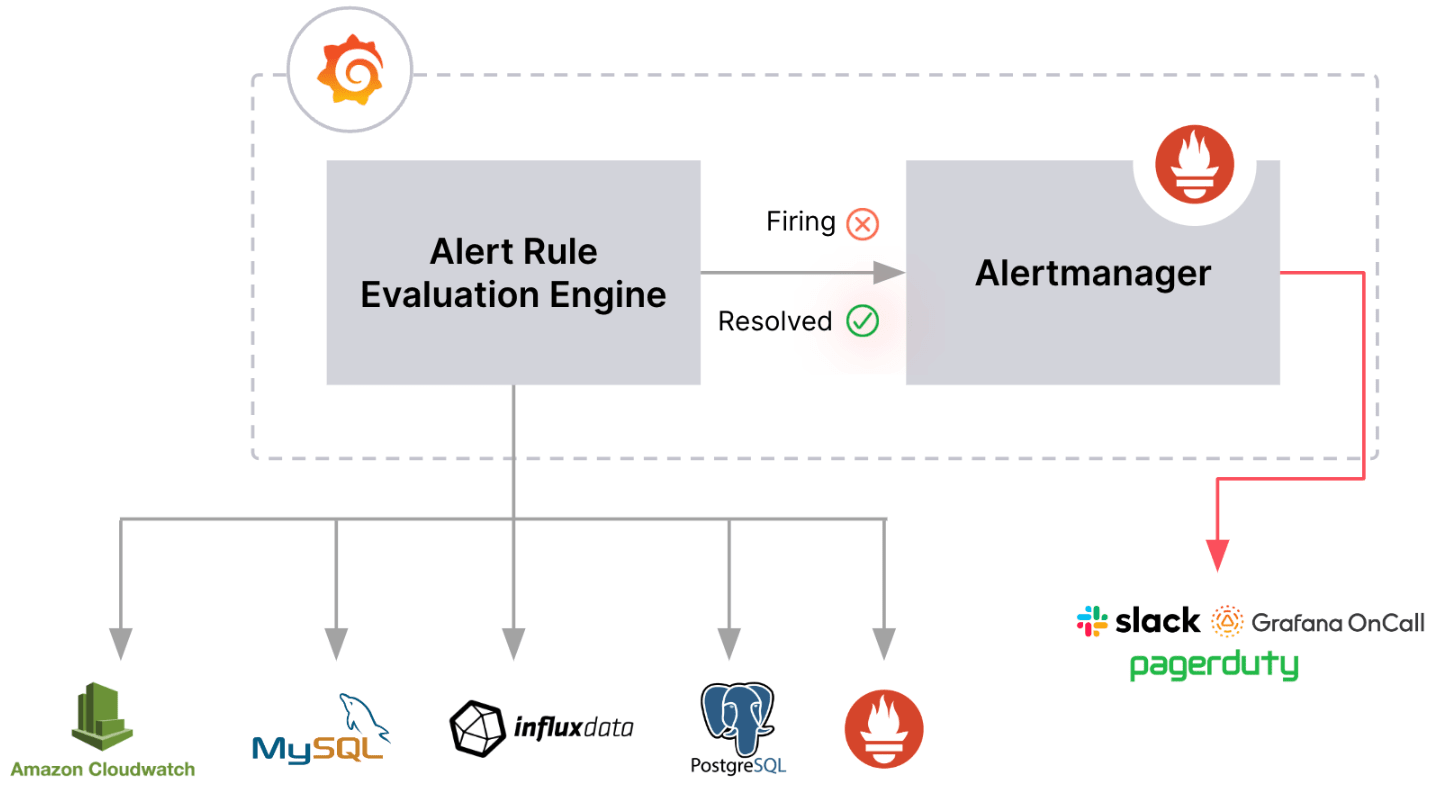
Grafana-managed Alert Rule は、Grafana Alert でサポートされる任意のデータソースに対してクエリを実行できます。 単一の Alert Rule で複数のデータリソースを参照することができます。
Data source-managed Alert Rule
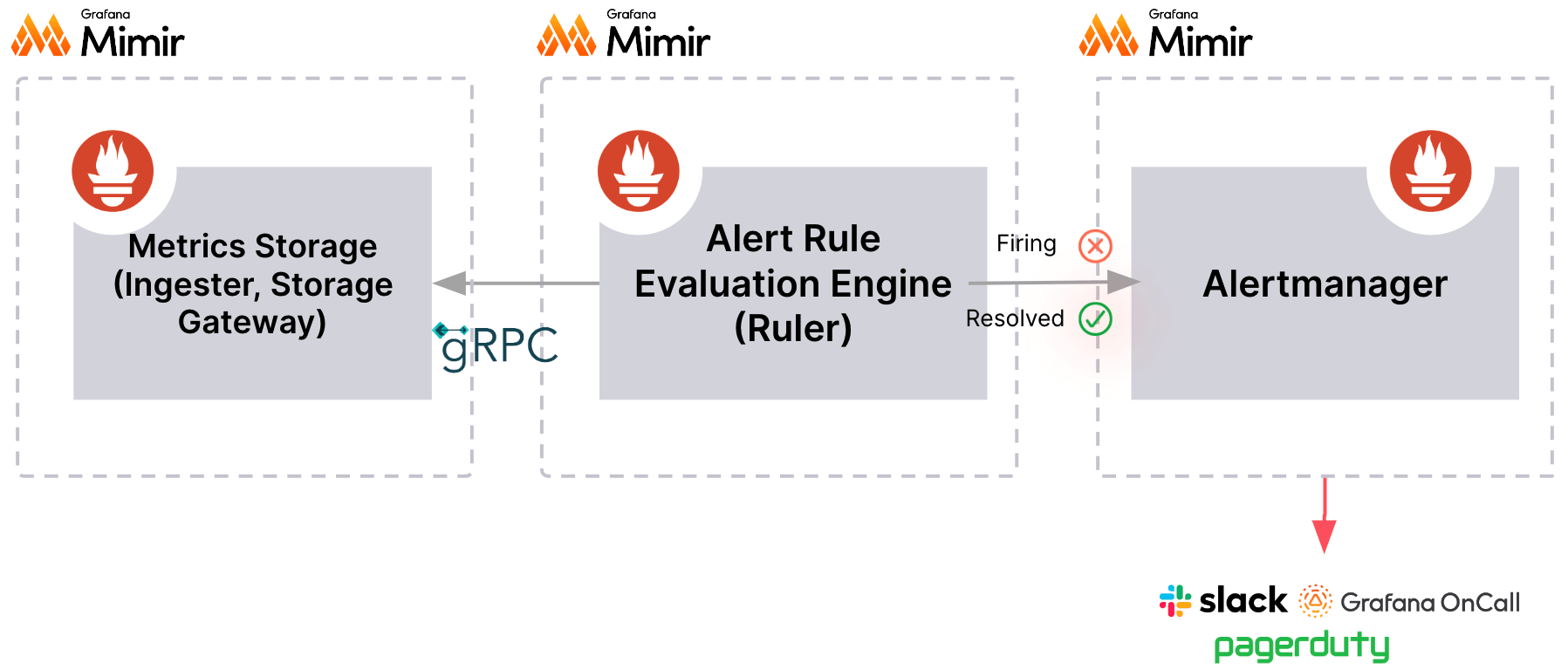
Data source-managed Alert Rule は、Prometheus、Grafana Mimir、Grafana Loki 等 Prometheus ベースのデータソースに対してのみクエリを実行できます。
こちらはアラートの評価コンポーネントが分離されているため、Grafana-managed Alert Rule と比較して、可用性や負荷に対するスケーラビリティが高いのが特徴です。
Alert Rule の比較
| 特徴 | Grafana-managed Alert Rule | Data source-managed Alert Rule |
|---|---|---|
| データソースに対するクエリ | 可 | 不可(Prometheus ベースのデータソースのみ可) |
| データソースを組み合わせる | 可 | 不可 |
| クエリでデータを変換してアラート条件(閾値)をセッっていする | 可 | 不可 |
| アラートメッセージに画像を追加する | 可 | 不可 |
| Recording Rule のサポート | 可 | 可 |
| Organization アクセス制御 | フォルダ単位で設定可能 | 名前空間を使用する |
| Alert Rule の評価と配信 | Alert Rule は Grafana で評価され、Alertmanager で配信される | Alert Rule の評価と配信は個別に設定可能 |
| スケーリング | 垂直スケールのみ(Alert Rule は Grafana 管理のデータベースに保存) | 水平スケール可能(Alert Rule は任意のデータソース内に保存) |
Recording Rule
Recording Rule は、頻繁に使用されるクエリや計算コストの高いクエリを事前に計算して、時系列メトリクスとして保存しておく機能です。
通常、Grafana ではデータソースにクエリを発行し、その結果をリアルタイムに取得して利用します。
しかし、複雑なクエリや、大量のデータを含むクエリを繰り返し実行すると、データソースへの負荷が増加し、応答速度が低下することがあります。
例えば、あるメトリクスの 1 時間単位の平均値を頻繁に表示する必要がある場合、その都度計算すると処理負荷がかかりますが、Recording Rule で事前に 1 時間毎の平均値を保存しておけば、クエリ実行時に即座に結果を取得できます。
Recording Rule は特に大規模な監視システムやクエリ負荷の高い環境で重要な役割を果たします。
Recording Rule も Alert Rule と同様に定期的に評価されます。
クエリと条件
Alert Rule ではアラートを発砲するために大まかに 3 つの設定を管理します。
- データソースに対するクエリ
- アラートを発砲する条件・閾値
- 取得したデータに対する変換処理を行うオプション式
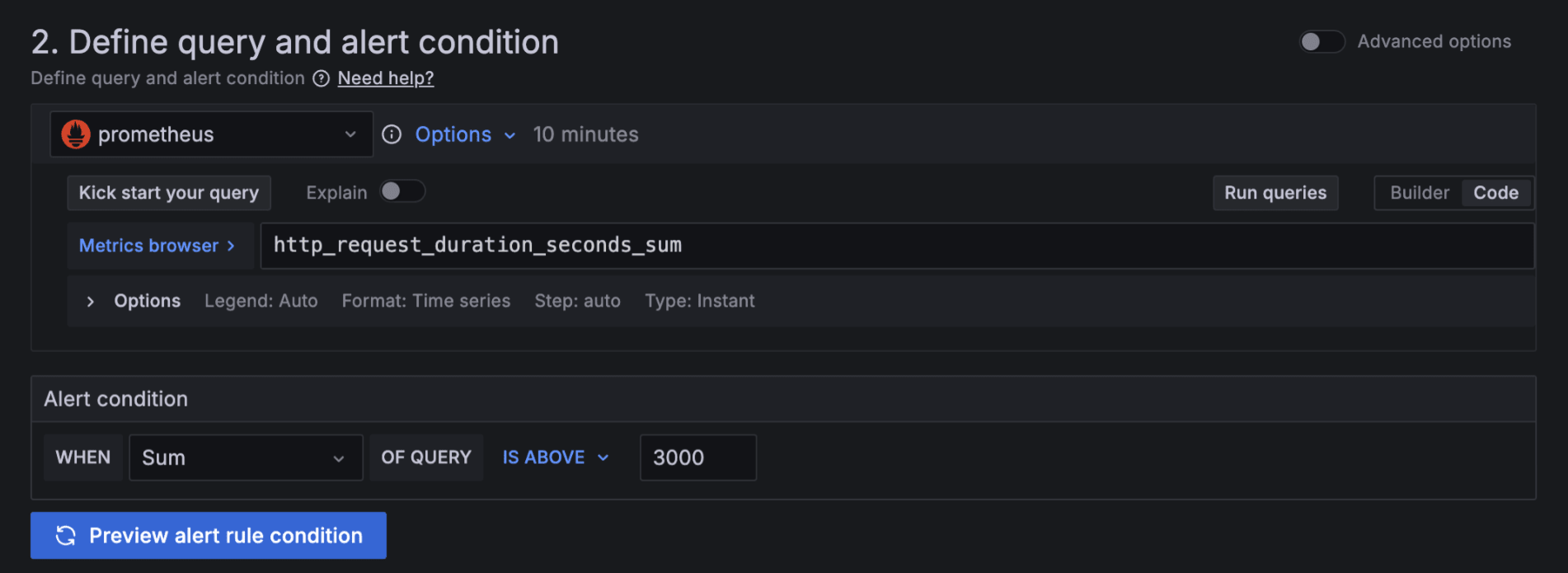
アラート条件
クエリの結果がアラートの条件を満たすかどうかを判断するための設定です。 デフォルト(WHEN)を使用すると、クエリの最終結果のみを使用して条件を定義するため、データの削減に繋がります。
オプション式
クエリされたデータセットに対して計算・変換・集計をするための設定です。 2 つのクエリ結果を使用することで、パーセンテージ計算、関数(指数・対数)の利用、特定の期間に限定したデータ集計等の条件付きロジックを柔軟に設定することができます。
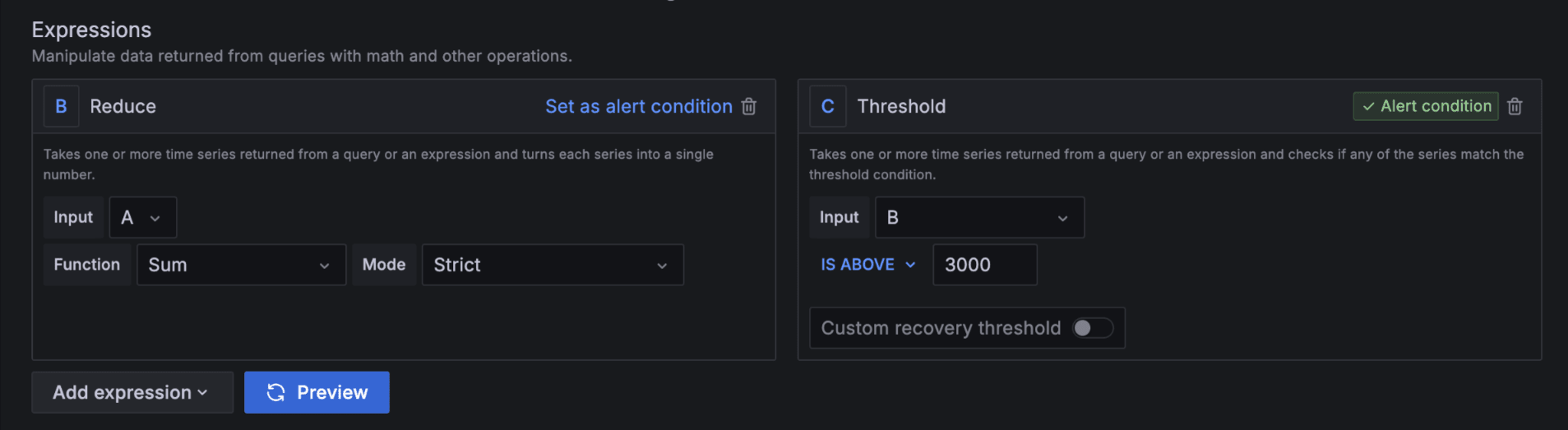
Reduce
- 選択した時間範囲内の時系列値を 1 つの数値に集計する
- 1 つ以上の時系列を取得し、各系列を 1 つの数値に変換する
- パラメータ:[
Min|Max|Mean|Mediam|Sum|Count|Last]
Math
- 時系列データと数値に対して自由形式の数学関数・演算を実行する
- 例:
$A + 1、$A * 100
- 例:
- 数式で数値のアラート条件を定義できる
$B > 70:B(クエリまたは式)の値が 70 より大きい場合にアラート条件を満たす$B < $C * 100:B の値が C の 100 倍より小さい場合にアラート条件を満たす
- 比較対象のクエリの結果に複数のシリーズがある時、両者の結果が同じラベルを持つか、一方が他方のサブセットである場合に一致する
Resample
- 時間範囲を新しいタイムスタンプのセットに再調整する
- タイムスタンプが一致しない異なるデータソースからの時系列データを比較する場合に有用
Threshold
- 以前のクエリまたは式(
$A、$B)の単一の数値を指定された条件と比較する - 閾値は 条件が偽の場合は
0を返し、真の場合は1を返す 1(真)が返されるとアラート条件を満たす- 2 つの単一な値を比較する際に有用
- Is above:
$A > 5 - Is below:
$B < 3 - Is within range:
$A > 0 AND $A < 10 - Is outside range:
$B < 0 OR $B > 100
- Is above:
回復閾値
通常のアラート(フラッピングアラート)閾値だけでは、頻繁に閾値を上回ったり、下回ったりすることでノイズが発生する可能性があります。 例えば、閾値が 1000ms のレイテンシアラートがあり、値が 1000ms 前後で変動している場合に 980 -> 1010 -> 990 -> 1020 となると、常にアラートがトリガされることになります。
回復閾値を設定することで、2 つの閾値でノイズを制御・削減することが可能になります。 例えば、980 -> 1010 は閾値超過だが、1010 -> 990 は Resolve(アラートから復帰した状態)として扱うことができます。
これにより、1000ms を超えた場合のみアラートがトリガされるようになり、アラートノイズの削減に繋がります。
ラベルとアノテーション
ラベル
ラベルは、Alert Instance を識別するために付与されます。 Alert Rule にラベルを設定することで、アラートを検索したりアラート同士を区別したりすることができます。
また、各 Alert Rule には複数のラベルを設定することができ、アラート自体の管理方針や Notification Policy(後述)のラベルマッチ機構でも利用されます。
例えば、{alertname="High CPU usage", server="server1"} と {alertname="High CPU usage", server="server2"} のようにラベルが異なる場合は、別々の Alert Instance として扱われます。
ラベルの種類は大きく以下の 3 つに分類されます。
ユーザ定義ラベル
ユーザ定義ラベルは、ユーザが独自に付与できるカスタムラベルです。 例えば、severity、priority、team、service のようなラベルを付与できます。
また、Notification Template(後述)でラベルをカスタマイズしたり、クエリ結果を元に動的にラベルの値を変更したりすることもできます。
クエリラベル
クエリラベルは、データソースクエリによって返されるラベルです。 同じ Alert Rule から複数の Alert Instance を生成した際に、それらを区別する目的で付与されます。
例えば、instance ラベルを付与することで、単一の Alert Rule からサーバ毎に Alert Instance を生成できます。
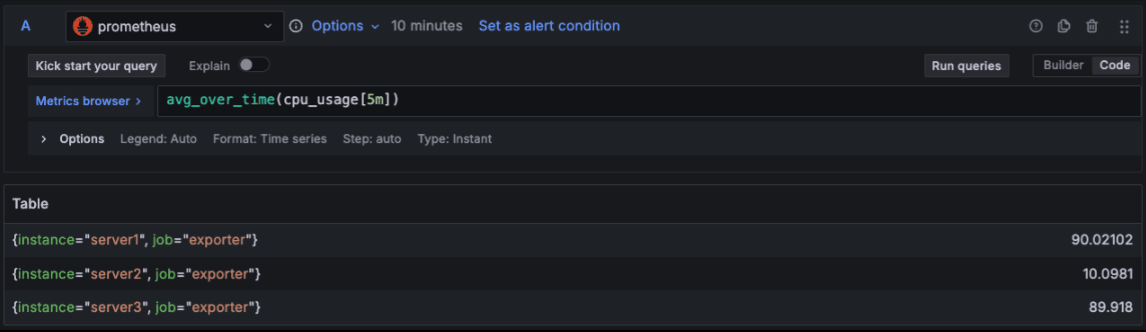
予約ラベル
予約ラベルは、Grafana 側で Alert Instance に対して自動的に付与されるラベルで、以下の 2 つがあります。
alertname:Alert Rule の名前grafana_folder:アラートが所属するフォルダ名
予約ラベルは、unified_alerting.reserved_labels を追加することで無効にすることもできます。参考
アノテーション
アノテーションは、担当者がアラートの問題を理解し、対処するための情報を提供するために付与されます。
summary:アラートが検出した内容とその理由の簡単な概要
### 例
CPU usage has exceeded 80% for the last 5 minutes.
description:何が起こったか、アラートが何を行うかについての詳細な説明
### 例
The web server's CPU has exceeded 80% for more than 5 minutes.
This indicates that the system is under heavy load and may result in an outage.
Consider scaling the server's resources and investigating bottlenecks.
runbook_url:アラートに対する対処ガイドリンクdashboardUId / panelId:アラートを調査するダッシュボードとパネルのリンク
Alert Rule Evaluation
Grafana Alert は Evaluation Group と Pending Period に基づき、条件を満たした Alert Instance のみを配信します。
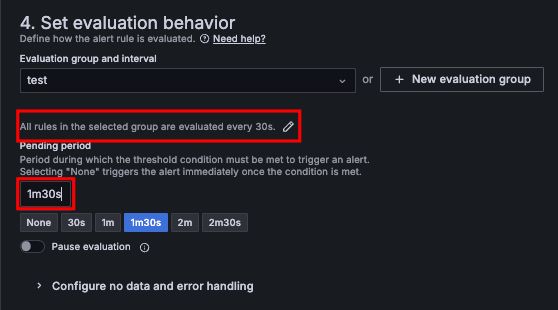
Evaluation Group / Evaluation Interval
Evaluation Group は Alert Rule のグループです。 Evaluation Group は Evaluation Interval で設定された頻度に基づいて定期的に評価されます。
全ての Alert Rule はいずれかの Evaluation Group に所属します。 Alert Rule は、既存の Evaluation Group に追加することも、新規に作成することもできます。
同じ Evaluation Group 内の Alert Rule は、設定された Evaluation Inteval に基づいて同時に評価されます。
また、同じ Evaluation Group 内の Alert Rule は上から順に評価されます。
Pending Period
Pending Period は、一時的な問題(何らかの理由により Alert Rule を正しく評価されない等)による不要なアラートを防ぐための機能で、アラートを送信するための条件を満たす必要がある期間 を管理します。 Pending Period によって、連続した期間に亘って条件が一貫して満たされることを保証します。
Pending Period が 0s に設定されている場合は、条件が満たされたら即座にアラートを送信 します。
Alert Instance
各 Alert Rule は、複数の Alert Instance を時系列で生成できます。
Alert Instance は Evaluation Interval と Pending Period に基づいて評価され、アラーティングまでのフェーズを『Normal(正常) → Pending(待機) → Alerting / Firing(発火) → Resolve(解決)』で巡回します。
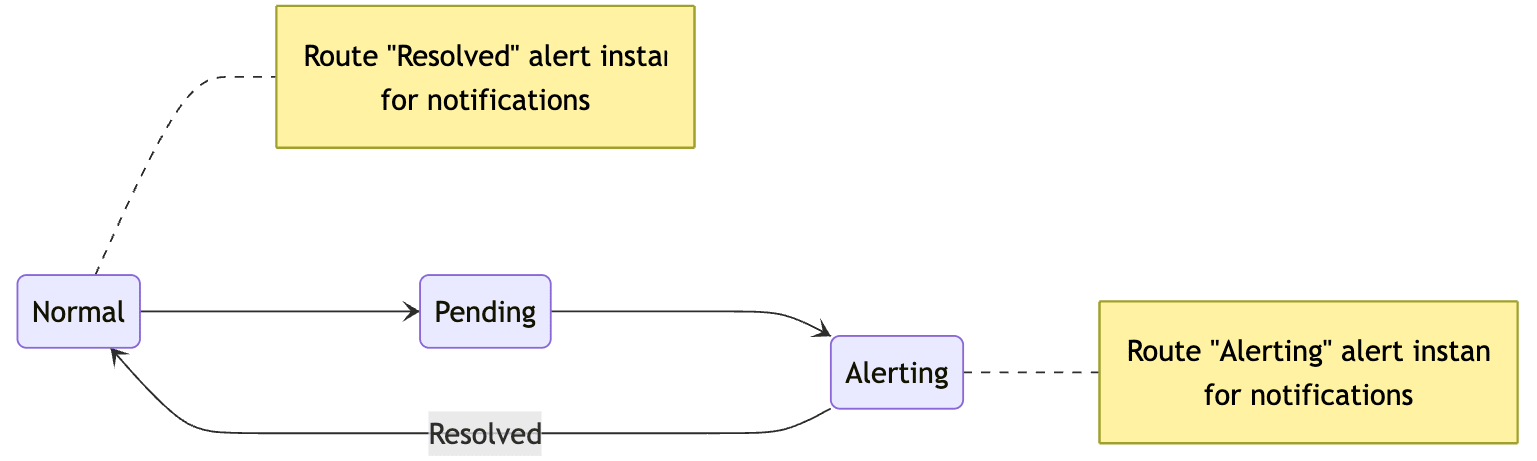
- Alert Rule に基づいて Alert Instance が生成される
- Evaluation Interval で評価されたクエリがアラートとなる場合、フェーズを Normal から Pending に遷移する
- Pending フェーズで Pending Period に基づいて待機した後、この間にアラート条件が満たされ続けた場合、Firing フェースに遷移してアラーティングする
- 一度 Firinng 状態になった Alert Instance は、正常状態に復帰する等してアラート条件から外れた場合、Resolve され、再度 Normal 状態に戻る
- 以後、Evaluation Interval と Pending Period に基づいて評価フェーズを巡回する
Alert Rule と通知タイミングの例
- Evaluation Interval 30s / Pending Period 90s に設定された Alert Rule の場合
| Time | アラートクエリ | Alert Instance の状態 | 経過時間 |
|---|---|---|---|
| 00:30(1 回目の評価) | 不成立 | Normal | - |
| 01:00(2 回目の評価) | 成立 | Pending | 0s |
| 01:30(3 回目の評価) | 成立 | Pending | 30s |
| 02:00(4 回目の評価) | 成立 | Pending | 60s |
| 02:30(5 回目の評価) | 成立 | Firing | 90s |
異常状態から復帰して、アラート条件が満たされなくなると、Firing 状態から Noraml 状態に遷移(Resolve)される。
| Time | アラートクエリ | Alert Instance の状態 | 経過時間 |
|---|---|---|---|
| 03:00(6 回目の評価) | 不成立 | Normal(Resolved) | 120s |
| 03:30(7 回目の評価) | 不成立 | Normal | 150s |
Alert Instance のフェーズ
| フェーズ | 概要 |
|---|---|
| Normal | 条件(閾値)が満たされていない状態 |
| Pending | 閾値を超えたが Pending Period が満たされてない状態 |
| Firing(Pending) | Pending Period を超えて閾値超過が発生した状態(アラート発砲条件の成立) |
| Node Data | クエリがデータを返さないか、全てのデータが null となっている場合 |
| Error | Alert Rule の評価中にエラーまたはタイムアウトが発生した場合 |
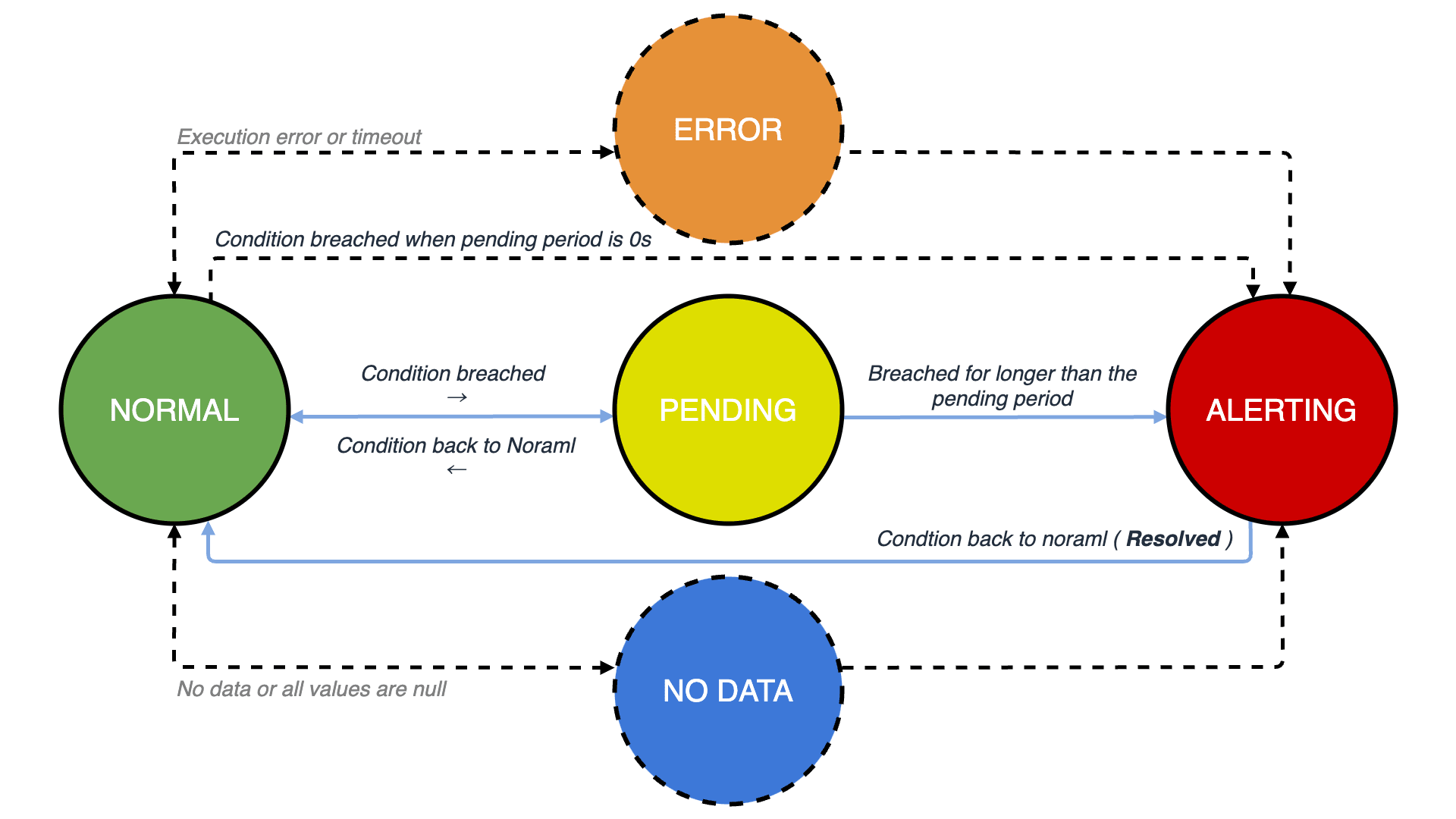
No Data と Error ステータス
Alert Rule を評価する際に No Data または Error が発生すると、Grafana Alert は以下のラベルを持つ新しい Alert Instance を生成します。
alertname:状態に応じてDatasourceNoDataまたはDatasourceErrorを付与datasource_uid:状態の原因となったデータソースの UID
No Data または Error ステータスとなった Alert Instance に対する挙動は [ Alerting | Normal | Error | Keep Last State ] を設定することができます。
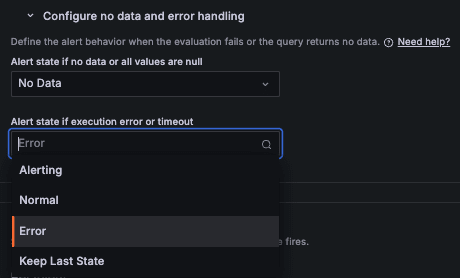
| 設定 | 挙動 | 概要 |
|---|---|---|
No Data | No Data(デフォルト) | alertname に DatasourceNoData ラベルを付与して新しい Alert Instance を生成 |
Error | Error (デフォルト) | alertname に DatasourceError ラベルを付与して新しい Alert Instance を生成 |
No Data or Error | Alerting | Alert Instance を Pending にした後、Pending Period に従って Alerting を実行(通常のフェーズを適用) |
No Data or Error | Normal | Alert Instance を Normal に設定(正常と見做す) |
No Data or Error | Keep Last State | Alert Instance の現在の状態を維持する(現在のフェーズをそのまま保持する) |
No Data と Error ステータスのハンドリング戦略
Keep Last State は Alert Instance の現在の状態を維持します。 これは、意図しないアラートの送信を回避できますが、評価の中断が長引く可能性があるため、なるべく避けた方が良いでしょう。参考
No Data を使用する場合、クエリのタイムレンジを拡張して Alert Rule を最適化できます。 ただし、拡張しすぎるとクエリがタイムアウトする可能性があり、他の Alert Rule へのパフォーマンスも懸念となるため、適切な評価タイムアウト(デフォルト 30s)を設定する必要があります。
Alert Rule のヘルスチェック
Alert Rule は次のいずれかのヘルスチェックステータスを返します。
| ステータス | 概要 |
|---|---|
Ok | Alert Rule の評価を正常に終了 |
Error | Alert Rule の評価中にエラーが発生 |
No Data | Alert Rule を評価したがデータが存在しない |
{status}, KeepLast | (Keep Last State が設定されていた場合)Alert Rule は別のステータスを受け取るはずだったが現在の状態を維持 |
Notification
アラートの通知を制御する機能です。 アラートの送信方法、タイミング、送信先を適切に設定し、システムの異常事態に即座に対応できるようにします。
Alert Rule から生成された全ての Alert Instance を送信すると、ノイズが生じるため、前述のラベルの機能を用いて、適切な単位でアラートをグルーピングします。 また、Notification Policy で通知のポリシを設定することで、アラーティングのタイミングを制御します。
Grafana Alert の Notification Policy はツリー構造になっており、柔軟にルーティングされます。
Contact Point
Contact Point は、アラートの通知先を決定します。 Contact Point を設定しない場合は、どこにも通知されません。
Contact Point には Email や Slack、Pagerduty 等の SaaS ソリューションの他、Webhook を用いたカスタムエンドポイントを設定することもできます。
サポートしている通知先は こちら をご確認ください。
Notification Policy
Notification Policy はアラートのタイミングを制御することで、ノイズを減らすための機能です。 Alert Instance はラベルマッチを使用して Notification Policy にルーティングされます。
また、複数の Alert Instance は、グループ化されて Contact Point に配信されます。

Notification Policy はツリー構造をしており、ルートにはデフォルトの Notification Policy が設定されます。 ルートの Notification Policy は、全ての Alert Instance に対して適用されます。
また、一致する他のポリシが見つからない場合も、全ての Alert Instance はルートの Notification Policy によって処理されます。
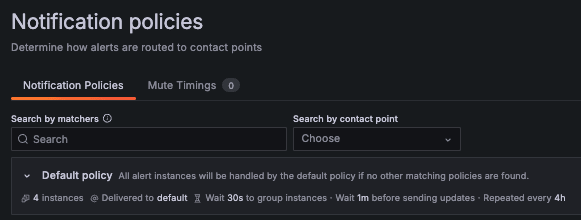
Default policy:
All alert instances will be handled by the default policy if no other matching policies are found.
各 Notification Policy には子ポリシを設定できます。
また、親と同じ階層レベルを共有する兄弟ポリシ(複数の子ポリシ)を追加できます。
. Root Notification Poilcy(Default)
└── Child Policy - 1
└── Child Policy - 2
└── Child Policy - 3
ラベルマッチ
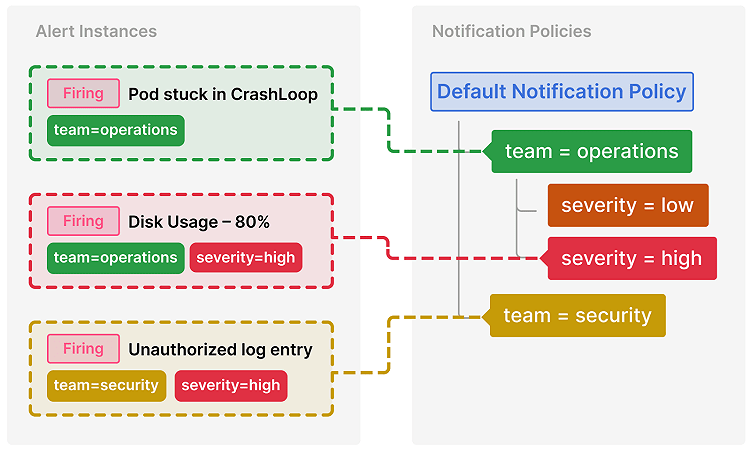
Alert Instance の評価が完了した後、同じラベルを持つ Alert Instance はグループ化されて Notification Policy にルーティングされます。 Notification Policy は設定されているポリシに基づいて Contact Point を決定します。
ポリシはルートから順番に評価され、一致するポリシが存在し続ける限り再起的に評価を行います。 階層形式でポリシの評価を終えた後、最も一致した子ポリシ(子ポリシが無い場合はルートポリシ)を使用して Alert Instance を処理します。
また、Notification Policy が一つも存在しない場合は、Alert Instance をそのまま Contact Point にルーティングします。
ラベルマッチは Notification Policy の『Instance』タブから確認できます。
ポリシの継承
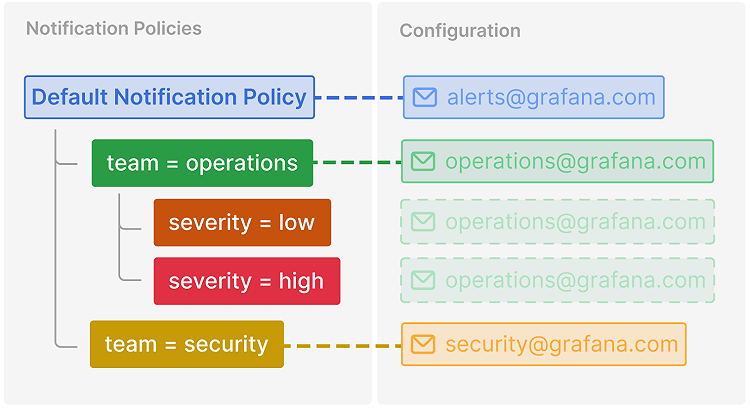
Notification Policy は、ルートポリシのプロパティを子ポリシに継承することができます。
上記画像の例では、team=operation を子ポリシに継承しており、severity=low や severity=high は、いずれも [email protected] という Contact Point へルーティングされます。
⭐️ Grouping ⭐️

Notification Policy の Grouping 機能は、通知のノイズを減らす上で最もコアとなる仕組み です。
短時間に大量の通知を受け取ると本当に必要な事象の把握が困難になります。 いわゆる、通知の爆発というやつです。
Grouping を使用すると、特定期間内の類似 Alert Instance を単一の通知に束ねることでアラートノイズを減らすことができます。
例えば、Group by オプションに team ラベルが指定されている場合、alertname:foo, team=frontend と alertname:bar, team=frontend はグルーピングされますが、alertname:foo, team=frontend と alertname:qux, team=backend はグルーピングされません。
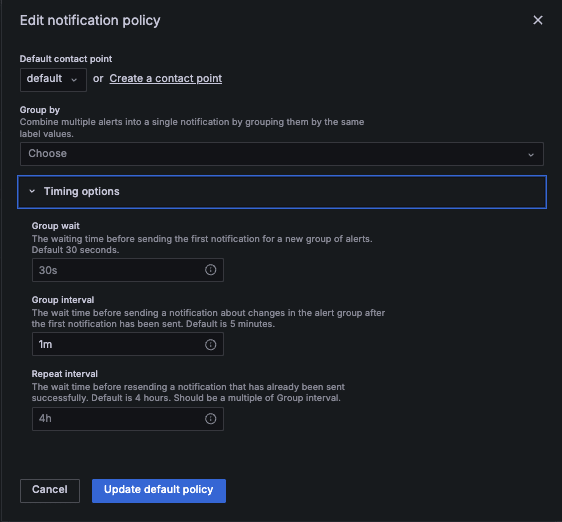
- Default Contact Point
- Notification Policy を適用する Contact Point を指定
- 指定しない場合はデフォルトの Contact Point が適用される
- Group by
- Notification Policy 内で受信アラートをグループ化する基準を指定
- 指定しない場合はデフォルトの Alert Rule 別となる
- Timing options
- アラートの各グループの通知ポリシに対して、3 つのタイマ を設定できる
- タイマを使用することでアラートの送信数をさらに削減できる
グループ通知
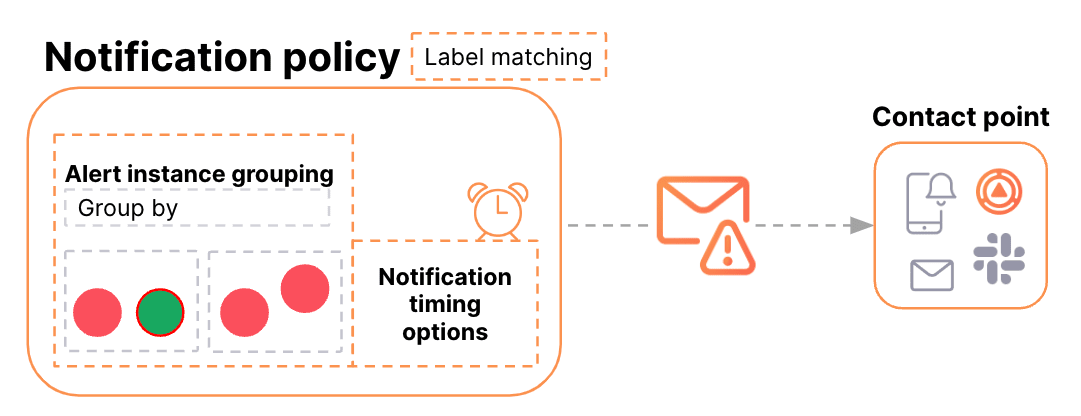
Alert Rule またはラベルによるグルーピング
デフォルトの Notification Policy を使用する場合、Alert Rule 毎にグルーピングされます。 Alert Rule はフォルダ間で一意ではないため、デフォルトの場合 grafana_folder と alertnameの予約ラベルでグルーピングされます。
Alert Rule 以外のラベルでグルーピングする場合は、Group by オプションを使用して他のラベルを含めます。
全てのアラートを単一のグループに統合
Group by オプションを指定しない(空にする)場合は、全てのアラートが単一のグループとして扱われます。
グループピングの無効化
全てのアラートを個別に扱う(グルーピングしない)場合、Group by オプションに "..." を指定することで、いずれのラベルも含めないようにすることができます。
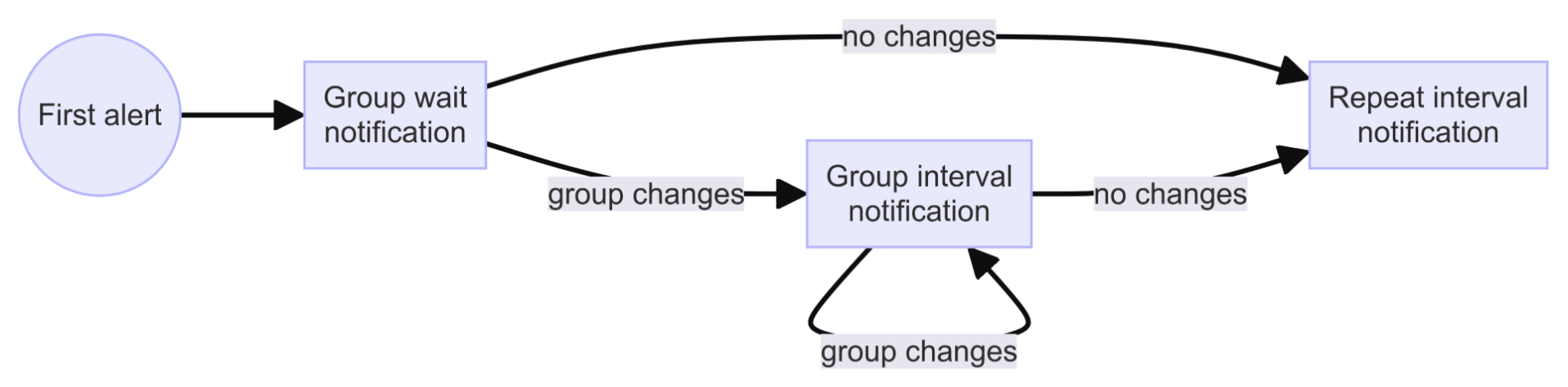
タイミングオプション
タイミングオプションには 3 つのタイマを設定できます。
Group Wait
- デフォルト 30s(0 や null の場合はデフォルト値が適用される)
- 新しいアラートグループの最初の通知を送信する前に待機する時間
- Alert Instance(グループ)に対して最初の 1 回のみ適用される
- グルーピングの重要度に応じて設定する
- 待機時間が長く設定すると、新しいアラートグループに他のアラートが含まれる可能性がある
- 待機時間が短く設定すると、新しいアラートグループは即座に配信されるが、他のアラートは含まれない可能性がある
- 例:Group Wait 30s /
teamラベルでグルーピングした場合
| 経過時間 | 受信する Alert Instance | Notification Policy Group | Alert Instance の数 | 挙動 |
|---|---|---|---|---|
| 00:00 | alertname=f1 team=frontend | frontend | 1 | frontend グループの Group Wait タイマを開始 |
| 00:10 | alertname=f2 team=frontend | frontend | 2 | |
| 00:20 | alertname=b1 team=backend | backend | 1 | backend グループの Group Wait タイマを開始 |
| 00:30 | frontend | 2 | frontend グループの Group Wait を停止して 2 件新規アラートを束ねて通知を 1 件送信 | |
| 00:35 | alertname=b2 team=backend | backend | 2 | |
| 00:40 | alertname=b3 team=backend | backend | 3 | |
| 00:50 | backend | 3 | backend グループの Group Wait を停止して 3 件新規アラートを束ねて通知を 1 件送信 |
Group Interval
- デフォルト 5m(0 や null の場合はデフォルト値が適用される)
- アラートグループの変更に関する通知を送信する前に待機する時間
- この間に Alert Instance の状態が変化した場合(アラートの追加または Resolve)は、アラート発砲を一時待機する
- 例:Group Interval 5m /
teamラベルでグルーピングした場合
| 経過時間 | 受信する Alert Instance | Notification Policy Group | Alert Instance の数 | 挙動 |
|---|---|---|---|---|
| 00:30 | frontend | 2 | frontend グループの Group Wait を停止して 2 件新規アラートを束ねて通知を 1 件送信した後、Group Interval タイマを開始 | |
| 00:50 | backend | 3 | backend グループの Group Wait を停止して 3 件新規アラートを束ねて通知を 1 件送信した後、Group Interval タイマを開始 | |
| 01:30 | alertname=f3 team=frontend | frontend | 3 | |
| 02:30 | alertname=f4 team=frontend | frontend | 4 | |
| 05:30 | frontend | 4 | frontend グループの Group Interval が経過するとタイマがリセットされ、4 件のアラートを束ねて通知を 1 件送信 | |
| 05:50 | backend | 3 | backend グループの Group Interval が経過してタイマがリセットされるが、アラートは送信されない(前回の通知から Alert Instance が変更されていないため) | |
| 08:00 | alertname=f4 team=backend | backend | 4 | |
| 10:30 | frontend | 4 | frontend グループの Group Interval が経過してタイマがリセットされるが、アラートは送信されない(前回の通知から Alert Instance が変更されていないため) | |
| 10:50 | backend | 4 | backend グループの Group Interval が経過するとタイマがリセットされ、4 件のアラートを束ねて通知を 1 件送信 |
Repeat Interval
- デフォルト 4h(0 や null の場合はデフォルト値が適用される)
- 前回の通知以降にグループが変更されていない場合に通知を送信する、もしくは繰り返す頻度を指定する
- グループ内の アラートが継続していることを通知する ために使用される
- Repeat Interval 期間中に復帰(アラートの削除または Resolve)した場合は、通知を発砲しない
- Repeat Interval は Group Interval がリセットされる度に評価される
- 前回の通知から Repeat Interval 経過後に、アラートグループが変更されていない場合、再通知を行う
- Repeat Interval は Group Interval 以上 かつ Group Interval の倍数で指定 する
- 倍数でない場合、Repeat Interval は切り上げた値が適用される
- Group Interval 5m の時、Repeat Interval を 9m としていた場合は、10m が適用される
- 例:Repeat Interval 5m /
teamラベルでグルーピングした場合
| 経過時間 | 受信する Alert Instance | Notification Policy Group | Alert Instance の数 | 挙動 |
|---|---|---|---|---|
| 05:30 | frontend | 4 | frontend グループの Group Interval が経過するとタイマがリセットされ、4 件のアラートを束ねて通知を 1 件送信 | |
| 10:50 | backend | 4 | backend グループの Group Interval が経過するとタイマがリセットされ、4 件のアラートを束ねて通知を 1 件送信 | |
| 04:05:30 | frontend | 4 | frontend グループの Group Interval タイマがリセットされるが、通知は送信されない(Repeat Interval + Group Interval が経過していないため) | |
| 04:10:30 | frontend | 4 | frontend グループの Group Interval タイマがリセットされ、4 件のアラートを束ねて通知を 1 件送信 (Repeat Interval + Group Interval が経過したため) | |
| 04:10:50 | backend | 4 | backend グループの Group Interval タイマがリセットされるが、通知は送信されない(Repeat Interval + Group Interval が経過していないため) | |
| 04:15:50 | backend | 4 | backend グループの Group Interval タイマがリセットされ、4 件のアラートを束ねて通知を 1 件送信 (Repeat Interval + Group Interval が経過したため) |
制約・注意
Timing options に設定できる値
Group Interval / Repeat Interval は、いずれも 1s 以上の値を設定する 必要があります。 未設定の場合は、それぞれのデフォルト値が適用されます。
- #86561: Alerting: Prevent simplified routing zero duration GroupInterval and RepeatInterval
- pkg/services/ngalert/models/notifications.go#L78-L96
// Validate checks if the NotificationSettings object is valid.
// It returns an error if any of the validation checks fail.
// The receiver must be specified.
// GroupWait, GroupInterval, RepeatInterval must be positive durations.
func (s *NotificationSettings) Validate() error {
if s.Receiver == "" {
return errors.New("receiver must be specified")
}
if s.GroupWait != nil && *s.GroupWait < 0 {
return errors.New("group wait must be a positive duration")
}
if s.GroupInterval != nil && *s.GroupInterval <= 0 {
return errors.New("group interval must be greater than zero")
}
if s.RepeatInterval != nil && *s.RepeatInterval <= 0 {
return errors.New("repeat interval must be greater than zero")
}
return nil
}
Repeat Interval の値
Repeat Interval は、Group Interval の倍数で設定 する必要があります。 倍数でない場合は、設定値を切り上げた値が適用されます。
また、Repeat Interval の値を Group Interval より小さくすることはできません。
// Override how long to wait before sending a notification again if it has already been sent successfully for an
// alert. (Usually ~3h or more).
// Note that this parameter is implicitly bound by Alertmanager's `--data.retention` configuration flag.
// Notifications will be resent after either repeat_interval or the data retention period have passed, whichever
// occurs first. `repeat_interval` should not be less than `group_interval`.
// example: 4h
RepeatInterval *model.Duration `json:"repeat_interval,omitempty"`
if interval < 0 || int64(interval.Seconds())%int64(limits.BaseInterval.Seconds()) != 0 {
return nil, fmt.Errorf("rule evaluation interval (%d second) should be positive number that is multiple of the base interval of %d seconds", int64(interval.Seconds()), int64(limits.BaseInterval.Seconds()))
}
- public/app/features/alerting/unified/components/notification-policies/EditDefaultPolicyForm.tsx#L143
<Field
label="Repeat interval"
description="The wait time before resending a notification that has already been sent successfully. Default is 4 hours. Should be a multiple of Group interval."
invalid={!!errors.repeatIntervalValue}
error={errors.repeatIntervalValue?.message}
data-testid="am-repeat-interval"
>
Notification Template
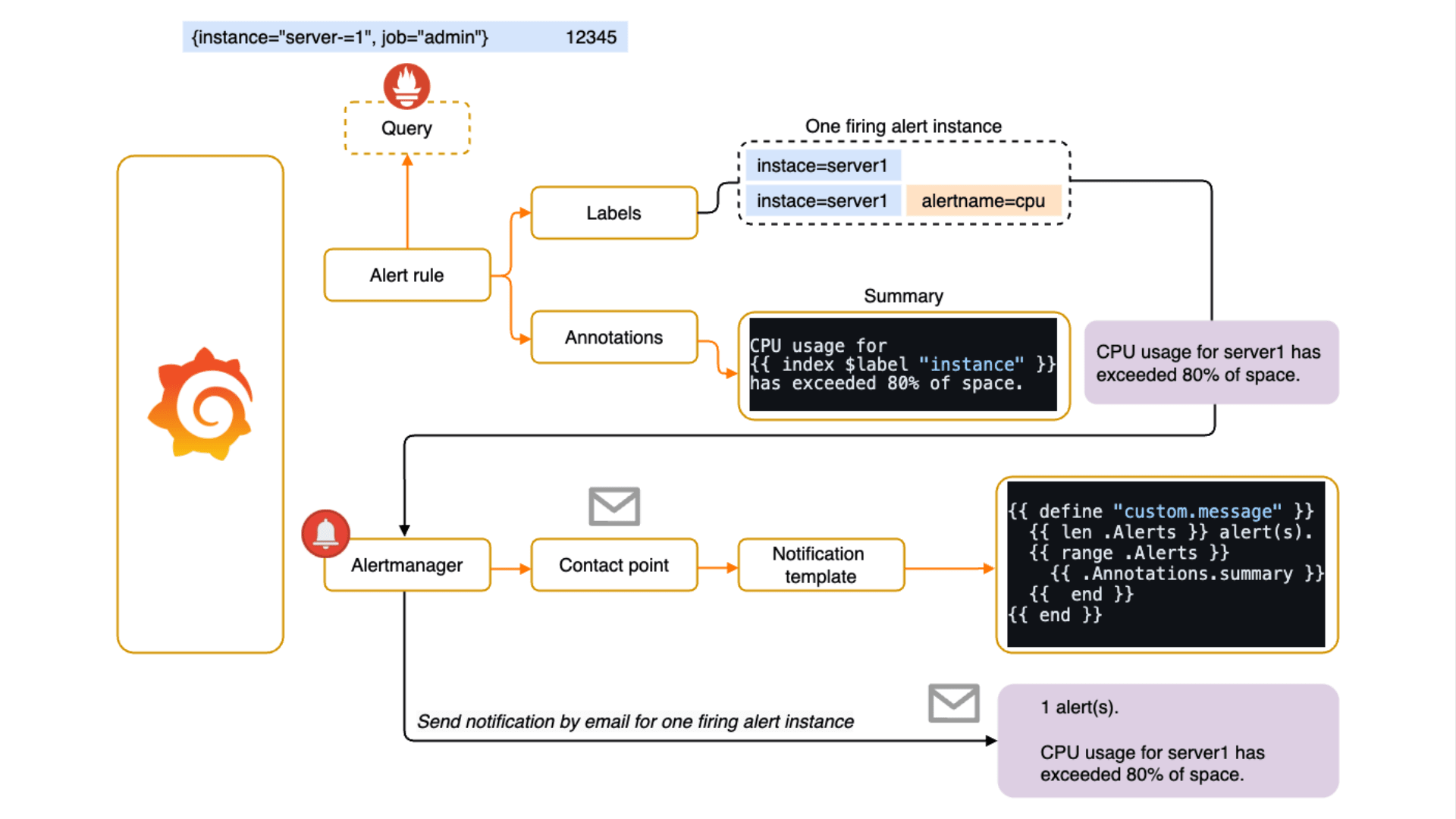
Notification Template は、アラートの通知メッセージをフォーマット、再利用するために使用します。 メトリクス、ラベル、その他コンテキスト情報等、動的なコンテンツをテンプレートに適用することで、統一したメッセージ内容を配信できます。
Annotations
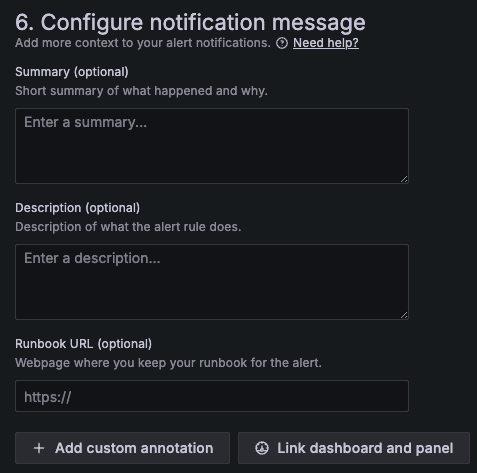
- Summary
- 通知メッセージのタイトルを付与
- サーバ名や閾値等、アラートの内容をざっくりと把握するための内容を含める
- Description
- アラートの詳細情報について
- Runbook URL
- アラートが発生した際の対応手順(ランブック)の提示
アラートがトリガされた場所と理由を説明する Annotations の例
CPU 使用率が閾値を超えるとアラートがトリガされて、Summary に関連する詳細が追加されます。
CPU usage for {{ $labels.instance }} has exceeded 80% ({{ $values.A.Value }}) for the last 5 minutes.
### 出力例
CPU usage for Instance 1 has exceeded 80% (81.2345) for the last 5 minutes.
Labels
前述で記載している通り、Alert Instance を区別するために使用されます。
クエリ結果をラベルに付与することもできます。
ただし、タイムスタンプ等、時系列データをラベルに含めると、ラベルマッチが有効に機能しなくなる可能性がある ため、Grouping も考慮して付与する必要があります。
severity クエリ値に基づいてラベルをテンプレート化する例
{{ if (gt $values.A.Value 90.0) -}}
critical
{{ else if (gt $values.A.Value 80.0) -}}
high
{{ else if (gt $values.A.Value 60.0) -}}
medium
{{ else -}}
low
{{- end }}
通知グループ内の全てのアラートと解決済みアラートをまとめた Notification Template の例
{{ define "alerts.message" -}}
{{ if .Alerts.Firing -}}
{{ len .Alerts.Firing }} firing alert(s)
{{ template "alerts.summarize" .Alerts.Firing }}
{{- end }}
{{- if .Alerts.Resolved -}}
{{ len .Alerts.Resolved }} resolved alert(s)
{{ template "alerts.summarize" .Alerts.Resolved }}
{{- end }}
{{- end }}
{{ define "alerts.summarize" -}}
{{ range . -}}
- {{ index .Annotations "summary" }}
{{ end }}
{{ end }}
### 出力例
1 firing alert(s)
- The database server db1 has exceeded 75% of available disk space. Disk space used is 76%, please resize the disk size within the next 24 hours.
1 resolved alert(s)
- The web server web1 has been responding to 5% of HTTP requests with 5xx errors for the last 5 minutes.
Alerting History
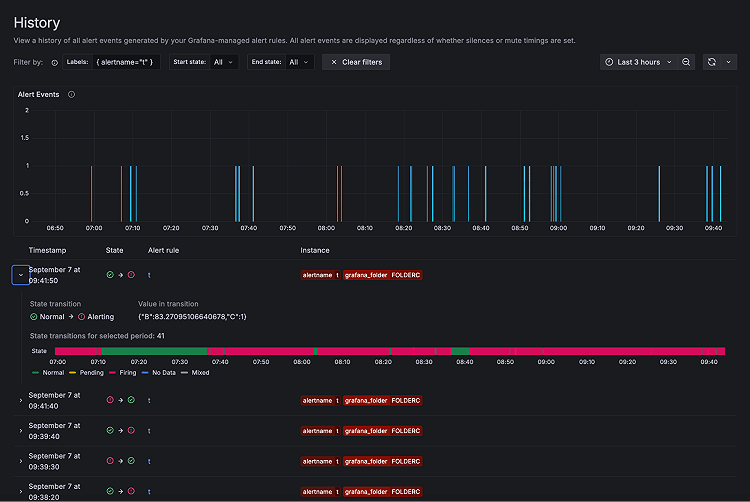
History では、Alert Rule で生成された全てのアラートイベントの履歴を確認できます。 History を活用することで、アラートのパターンや、発生したタイミングを時系列で追ったり、傾向を把握したりすることができます。
アラートイベントは一定期間内に Alert Instance の状態が変化する度に表示されます。 サインレンスやミュートが有効になっている場合も、Alert Rule が評価され続ける限り History に残ります。
ただし、Alert Rule を 一時停止(Pause)している場合は、評価自体がされないため History にも残りません。
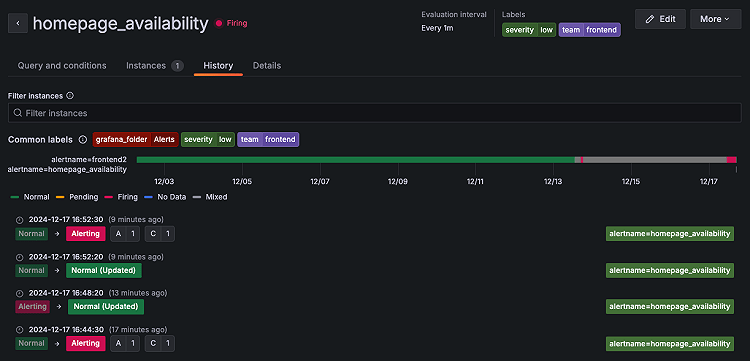
各 Alert Rule の『History』タブから Alert Instance の状態が時系列でどのように変化したかも確認できます。
まとめ
今回のブログでは Grafana Alert の仕組みと、アラートのタイミングを制御する機能について整理してみました。
モニタリングでは、如何に不必要な情報を排除してノイズを減らせるかが重要になります。 特に、アラーティングでは、短時間に大量の通知を受け取ると本当に必要な事象の把握が困難になります。
Grafana Alert では、単純なクエリや条件の設定に加え、通知のタイミングを制御する Notification Policy の機能群を活用することで、より柔軟なアラーティングを整備できます。