GKE のアップグレード戦略を考える
- Authors
- Name
- ごとれん
- X
- @ren510dev


目次
- 目次
- はじめに
- Google Kubernetes Engine
- 運用モード
- バージョン体系
- Kubernetes アップグレードの課題
- アップグレードタスク
- 安全なアップグレードを実現するため機能
- 1. 変更内容・影響範囲の把握
- 2. クラスタの安全なアップグレード
- 3. アップグレードタイミングの制御
- アップグレード戦略を考える
- In-place アップグレード
- ノードプール Blue/Green アップグレード
- クラスタ Blue/Green アップグレード
- アップグレードに付随する推奨設定
- まとめ
- 参考・引用
はじめに
Google Kubernetes Engine(GKE)は Google Cloud が提供するマネージド Kubernetes サービスで、クラウドネイティブなアプリケーションの実行基盤として広く利用されています。 Kubernetes クラスタの運用において、アップグレード作業はセキュリティの確保や新機能の利用のために不可欠なプロセスです。
一方、Kubernetes のマイナーリリースは 通常 3 - 4 ヶ月に 1 回のペースで実施される上、アップグレード作業にはいくつもの考慮事項があるため、メンテナンスコストが高くなりがちです。
また、マネージド Kubernetes の場合、サポートを受けられる期間も限られているため、継続的なクラスタバージョン追従が必要になります。
このような GKE のメンテナンスに関する課題に対して、Google Cloud は作業負荷を下げるための仕組みを用意してくれています。
このブログでは、GKE の効果的なアップグレード戦略について Google Cloud の内間さんが出している こちらのスライド を参考にまとめてみます。
Speaker Deck - GKE のアップグレード戦略を考える
Google Kubernetes Engine
Google Kubernetes Engine(GKE) は Google Cloud が提供しているマネージド Kubernetes です。
運用モード
GKE は、Standard と Autopilot の 2 種類の運用モードを選択することができます。 前者の Standard モードでは、主に Control-Plane がフルマネージドになっており、Data-Plane および、ワーカーノード(ノードプール)は利用者側で管理します。 後者の Autopilot モードでは、Control-Plane に加え、Data-Plane の管理もマネージドに提供されています。
Autopilot は、利用者がアプリケーション開発に集中できるよう、ノードの管理やクラスタのメンテナンス作業を Google Cloud 側が集約的に管理してくれます。
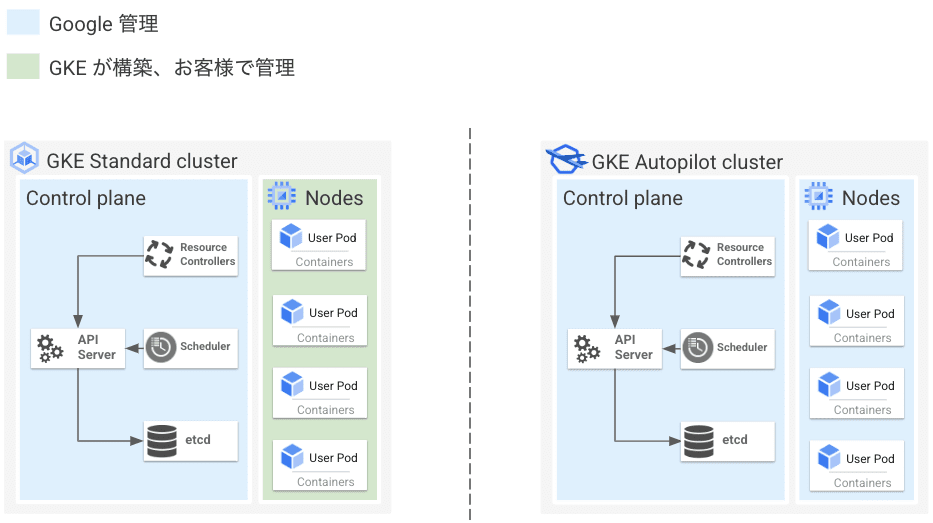
下記の管理範囲からも分かる通り、GKE はセルフホスティングされた Kubernetes に比べて、多くの機能がマネージドに提供されていることが分かります。
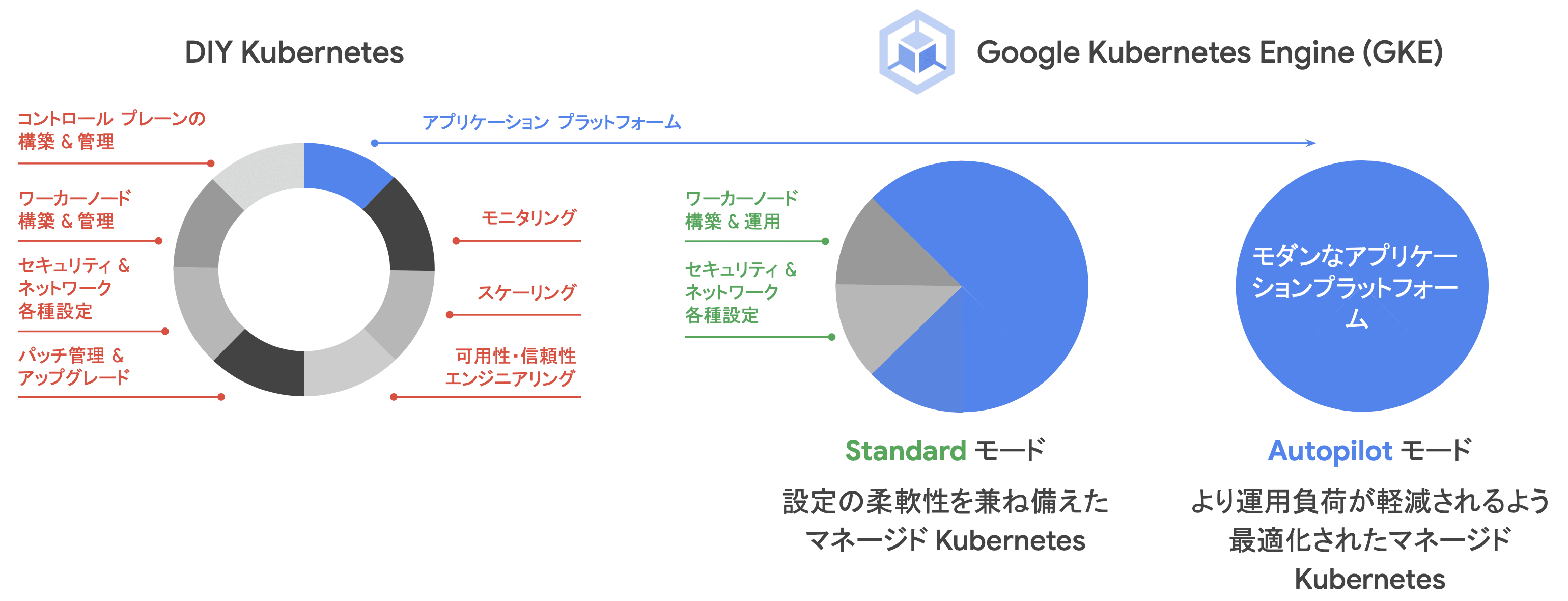
バージョン体系
GKE のバージョンには以下の 3 つのセクションがあります。
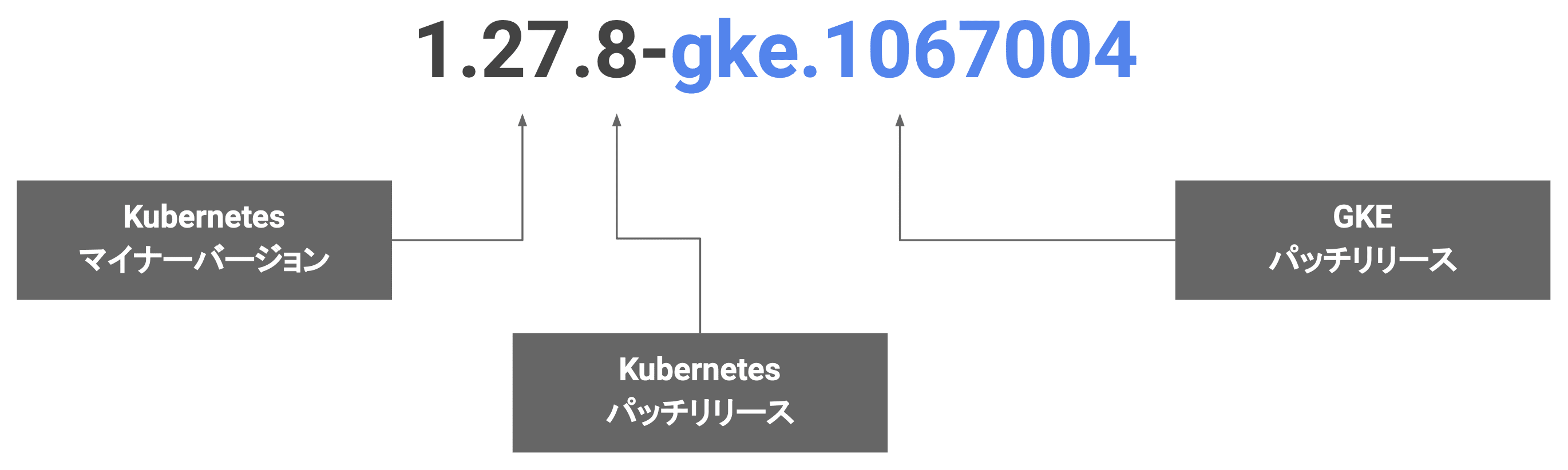
| セクション | 例 | 更新内容 | 更新頻度 |
|---|---|---|---|
| マイナーバージョン | 1.26 → 1.27 | 新機能・仕様変更 | 約 3 ヶ月毎 |
| Kubernetes パッチリリース | 1.27.1 → 1.27.2 | バグ修正・セキュリティパッチ | 不定期 |
| GKE パッチリリース | 1.27.3-gke.100 → 1.27.3-gke.200 | GKE 独自の修正 | 不定期 |
マイナーバージョン
例:1.26 / 1.27 / 1.28
Kubernetes のバージョンは 「MAJOR.MINOR.PATCH」 の形式で管理されます。
Kubernetes のマイナーバージョンのリリースは約 3 ヶ月毎に実施され、新機能の追加や改善が含まれます。 GKE は Kubernetes のリリースに追従し、新しいマイナーバージョンを提供します。
GKE では、N-2 に基づき、通常 3 つのマイナーバージョンがサポートされます。 新しいバージョンがリリースされると最も古いバージョンのサポートが終了します。
Kubernetes パッチリリース
例:1.27.1 / 1.27.2 / 1.27.3
Kubernetes は、各マイナーバージョンに対してパッチリリースを提供します。 パッチリリースは、バグ修正やセキュリティパッチを含み、フォーマットは 「1.MINOR.PATCH」 となります。
GKE は新しい Kubernetes のパッチリリースが提供されると、GKE 向けに検証を行い、適用可能なパッチを反映します。
GKE パッチリリース
例:1.27.3-gke.100 / 1.27.3-gke.200
GKE は、Kubernetes のパッチリリースに加えて、Google Cloud による独自の修正や強化を含んだ GKE 専用のパッチリリースを提供します。 GKE のパッチバージョンは 「Kubernetes バージョン + GKE 固有の修正番号」 で構成されます。
上の例において、「gke.XXX」の部分が GKE パッチリリースに該当し、Google Cloud が GKE に特化した修正・最適化を適用したものになります。
GKE パッチリリースは、クラスタの安定性やパフォーマンス向上を目的として提供され、GKE クラスタの自動更新設定によって適用される場合もあります。
Kubernetes アップグレードの課題
Kubernetes はオープンソースとして進化を続け、頻繁に新しいバージョンがリリースされています。 これにより、脆弱性の修正、新機能の導入、既知の不具合への対応が可能になります。
しかし、クラスタアップグレードの作業はタスクが多く、いくつもの障壁が存在するため、運用負荷が高いことが課題となっています。
アップデート内容や影響範囲特定
アプリケーションマニフェストやエコシステムのアップグレード
クラスタアップグレード(各環境毎に実施)
アプリケーション動作確認
... 他にも。
無理なく継続的にアップグレードを行うためには、自動化された仕組みが必要となります。
アップグレードタスク
GKE のクラスタアップグレードは、大まかに以下の流れで実施していきます。
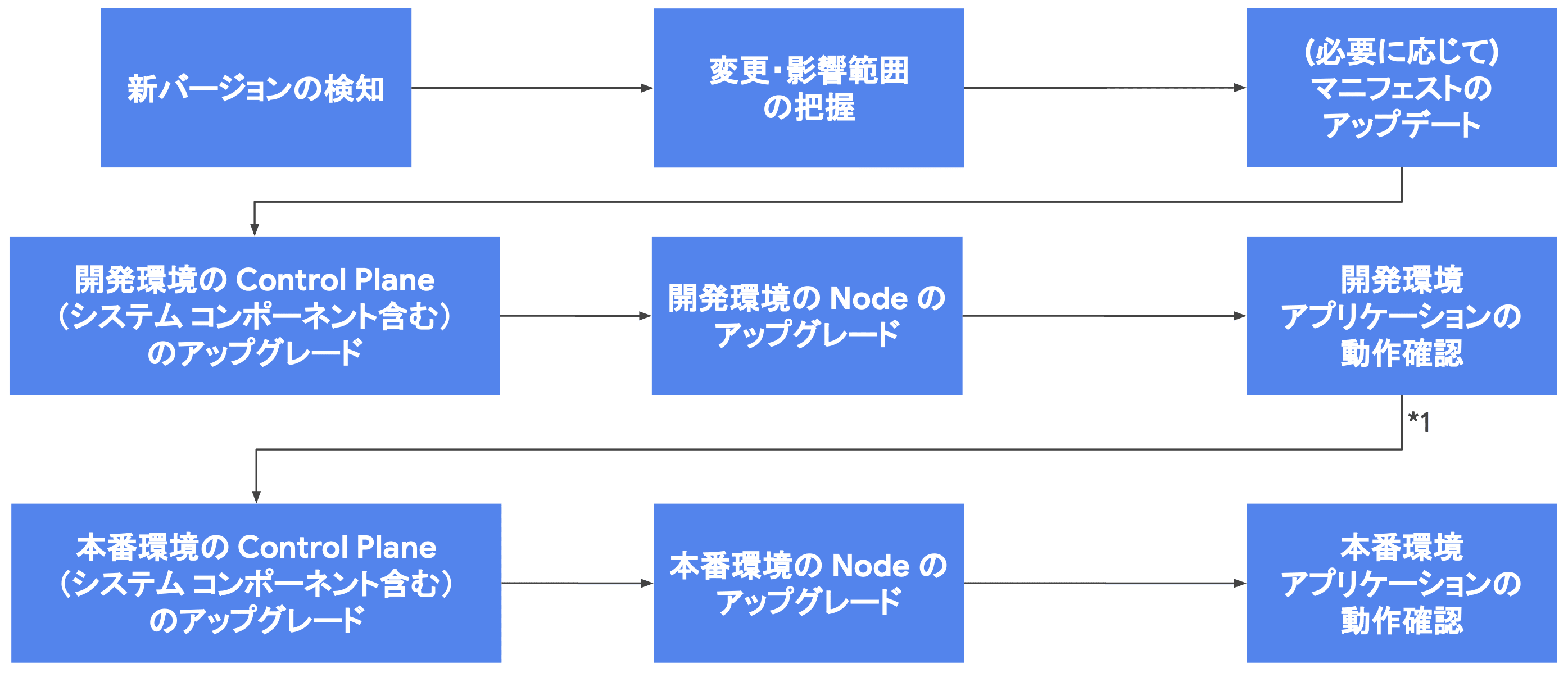
アップデート内容の把握と影響範囲の特定
アップグレードを実施する前には、リリースノートやセキュリティ情報を詳細に確認し、どのような変更が行われ、どの部分に影響が出る可能性があるかを把握する必要があります。 これにより、必要な準備を事前に行い、トラブルを未然に防ぐことができます。
GKE のアップグレードによる変更内容は、公式の リリースノート に詳細が記載されています。 リリースノートは Kubernetes 本体だけでなく、GKE 固有の変更点についても触れられています。
また、Security bulletins では、クラスタに影響を与える可能性のある脆弱性情報が集約されています。 これらの情報を定期的に確認し、必要な対策を迅速に講じることが推奨されます。
非推奨 API と構成の検出
GKE では、将来的に削除される予定の Kubernetes API や構成を自動的に検出し、利用者に通知する仕組みが用意されています。 これにより、自動アップグレード時の互換性問題を事前に回避できます。
また、手動での確認も必要となるため、CNCF の FairwindsOps/Pluto 等を利用し、非推奨 API を事前に洗い出して適切な対策を講じることが必要です。
アプリケーションマニフェストのアップデート
マニフェストファイルの内容が古いバージョンの API に依存している場合、アップグレードに伴い動作しなくなる可能性があります。 kubectl-convert を利用することで、古いマニフェストを自動的に最新バージョンに変換することができます。
安全なアップグレードを実現するため機能
Google Cloud は、GKE のアップグレードタスクにおいて、主に以下の 3 つの点でアップグレードをサポートする機能を提供しています。
- 変更内容・影響範囲の把握
- クラスタの安全なアップグレード
- アップグレードタイミングの制御
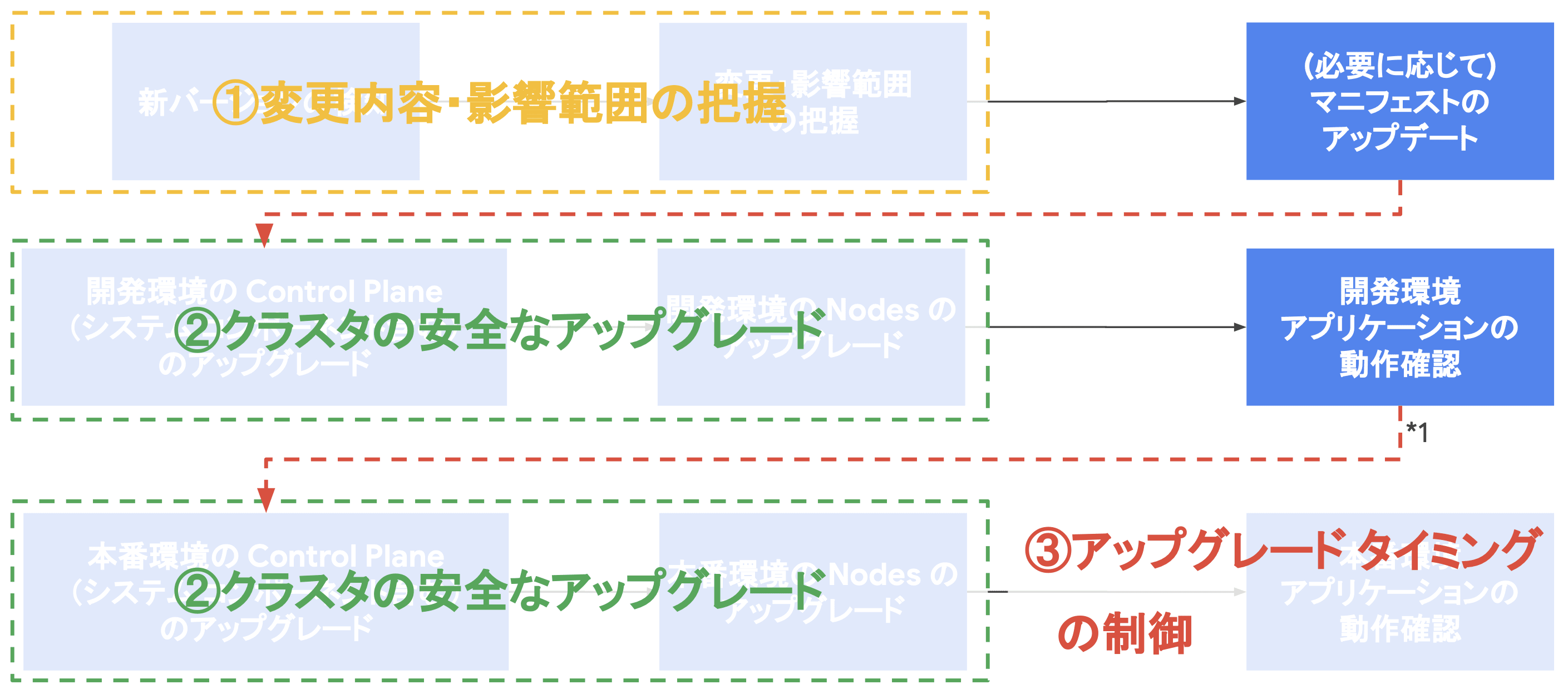
1. 変更内容・影響範囲の把握
第一にクラスタアップグレードに伴う変更内容や運用サービスへの影響範囲を適切に把握することが重要になります。
クラスタアップグレード / 脆弱性情報自動通知
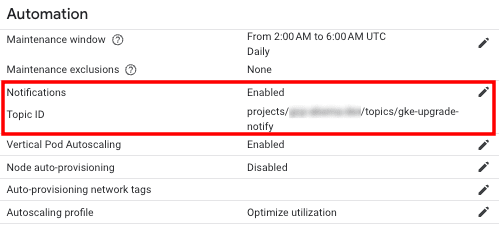
GKE は、アップグレードや脆弱性情報を報告する Pub/Sub ベースの通知機能を提供しています。
- SecurityBulletinEvent
- クラスタに影響のある脆弱性情報をタイムリーに通知
- UpgradeAvailableEvent
- 新しいバージョンが利用可能になったタイミングで通知
- マイナーバージョン:2-4 週間前
- パッチバージョン:1 週間前
- UpgradeEvent
- 実際にアップグレードが開始された際に通知(自動・手動問わず)
- UpgradeInfoEvent
- アップグレードが完了した際にステータスを通知(自動・手動問わず)
SUCCEEDED:アップグレードは正常に完了FAILED:アップグレードは失敗CANCELED:アップグレードのキャンセル操作が発生
これらの情報は、GKE クラスタの Notification Filter を活用して任意の Pub/Sub Topic へ送信することができます。 ただし、2024 年 10 月時点で、UpgradeInfoEvent は日本語版ドキュメントには反映されておらず、GKE 側での Notification Filter を適用できない 状況となっているようです。 そのため、必要に応じて、Pub/Sub もしくは、Subscriber 側でのフィルタリングを検討すると良いと思います。
Pub/Sub に送信されたイベント情報は、Subsciption を登録することで、Slack や Email 等、任意の宛先にメッセージを配信することができます。
以下は GKE のイベント通知を Pub/Sub 経由で Cloud Run Functions へ流し、Slack に通知する例です。


GKE のイベント通知を活用することで、適切なタイミングで対応を行うことが可能になります。
変更内容の確認
GKE アップグレードによる変更内容および影響については リリースノート から確認できます。
また、脆弱性情報は Security bulletins に集約されています。

日本語版ドキュメントは反映が遅れている可能性があるため、基本的に英語版で読むことを推奨します。
非推奨 API / 構成自動検出 と 移行
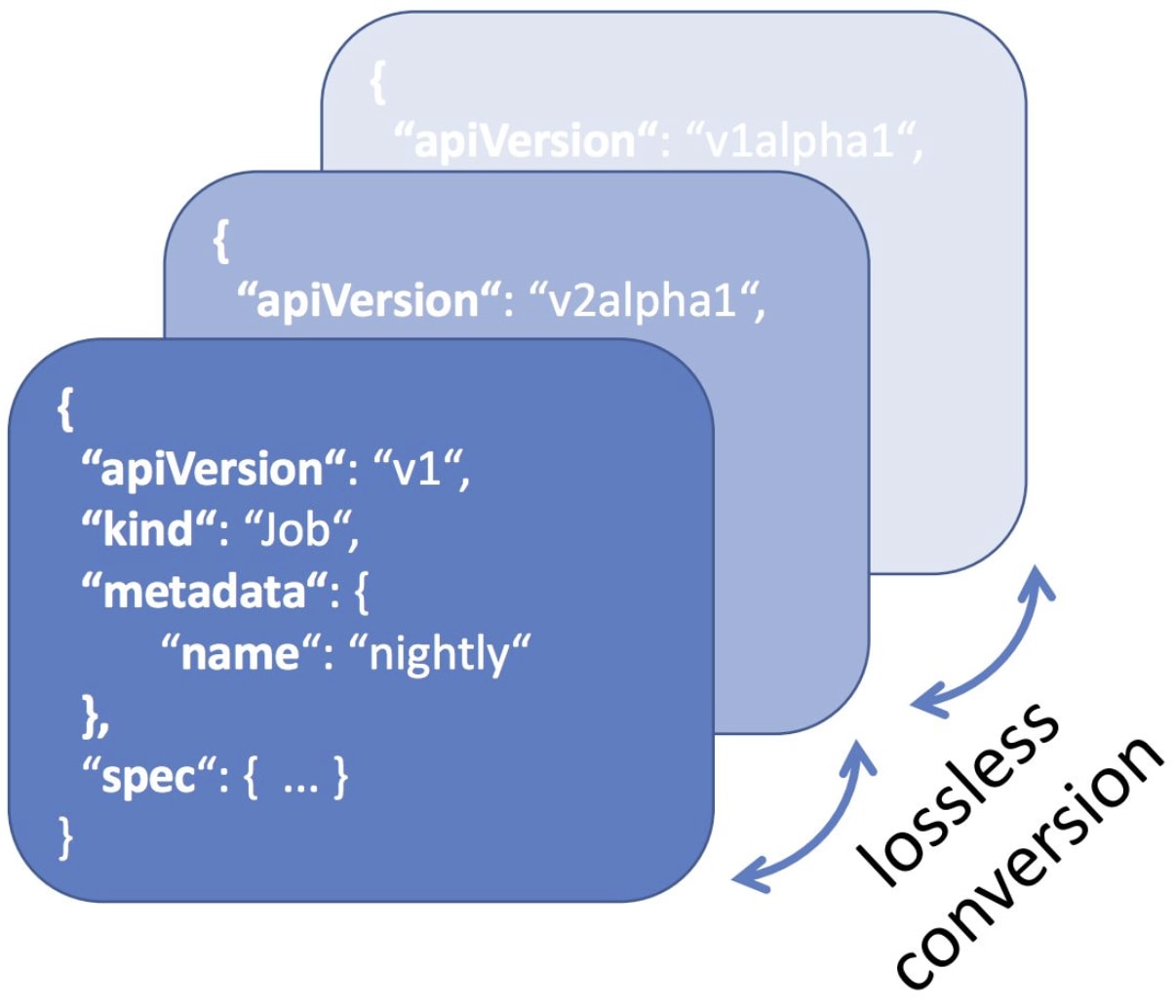
Kubernetes の API にはバージョンの概念があり、例えば、v1alpha1 → v1beta1 → v1 といった具合にアップグレードされます。 新しい API バージョンがリリースされると一定の併存期間を経た後、古い API バージョンは利用できなくなります。 API のバージョンニングは、成熟度の進展に応じて「Alpha」「Beta」「Stable」の 3 種類に分類されます。
| API バージョン | 例 |
|---|---|
| Alpha | v1alpha1 |
| Beta | v2beta3 |
| Stable | v1 |
また、API は Group/Version の形式で、マニフェストの apiVersion に指定されます。
apiVersion: apps/v1
この例では、v1 が apps グループのバージョンを示します。
GKE には、今後のマイナーバージョンで削除される Kubernetes API や構成がクラスタで使用されていることを自動的に検出して通知する機能が備わっています。 これにより、削除予定の API や構成利用が検出されると、GKE のオートアップグレードが中断されるため、互換性に起因する問題を回避できます。
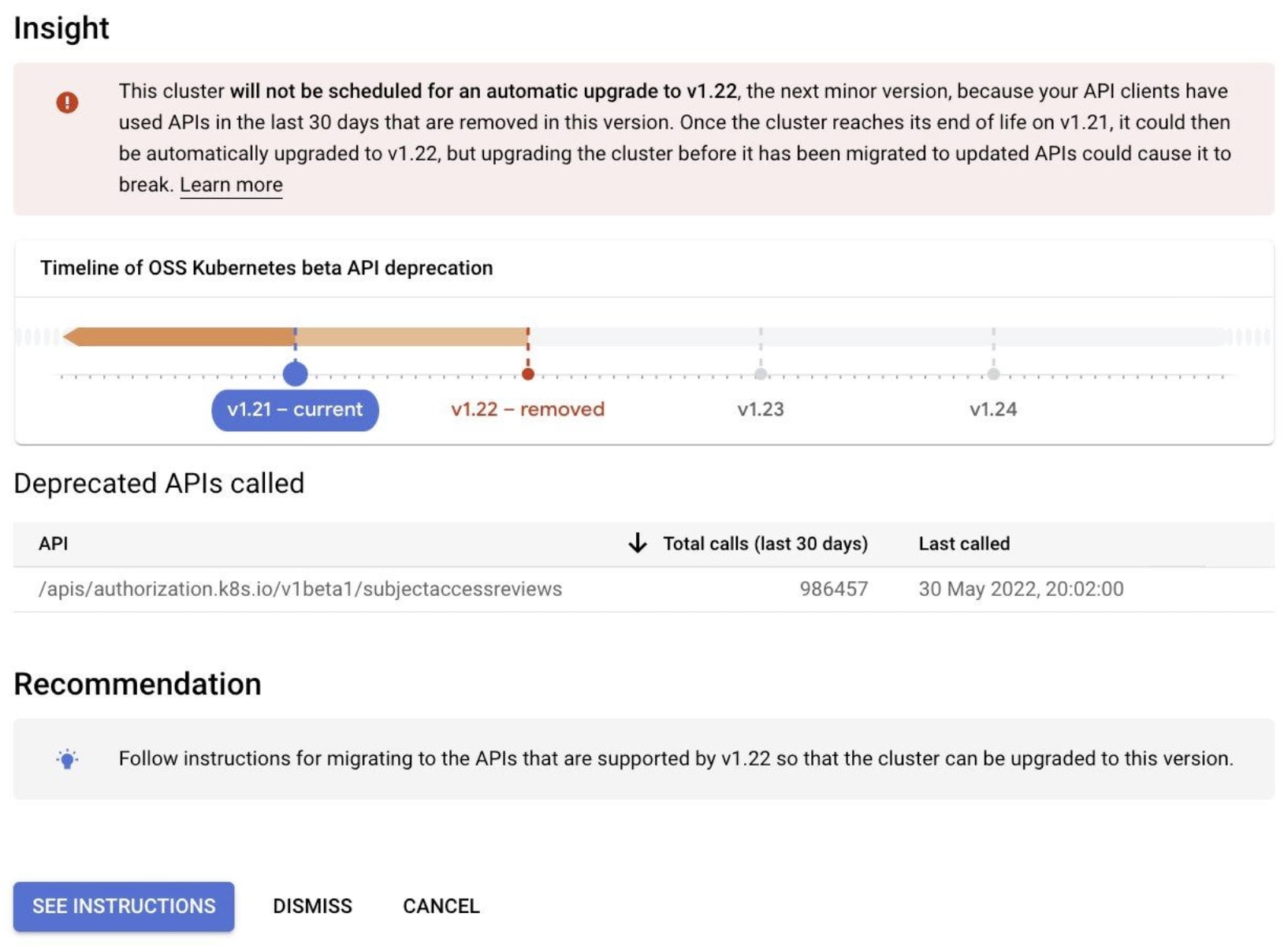
一方で、GKE の自動検出機能で検知できないケースも存在するため、別途 CNCF FairwindsOps/Pluto 等の導入が推奨されています。
また、Kubernetes マニフェストは、kubectl-convert により機械的にアップグレードすることも可能です。 ただし、影響範囲に関しては十分に精査した上で、実行する必要があります。
$ kubectl-convert -f pod.yaml --output-version apps/v1
Kubernetes API Deprecation の詳細は公式ドキュメントから確認可能で、GKE の非推奨事項は こちら に、Kubernetes の非推奨事項は こちら にあります。
2. クラスタの安全なアップグレード
GKE は Control-Plane を Google Cloud が管理しており、自動的にパッチ適用・アップグレードされます。
一方で、Data-Plane およびノードに関しては、利用者側で自動もしくは手動でのアップグレードを選択することができます。 ただし、Autopilot を利用している場合は、ノードも Control-Plane に追従する形で自動的にアップグレードされます。
- リリースチャネルを指定したクラスタ
- Control-Plane:自動
- Data-Plane:自動
- GKE Autopilot はリリースチャネルに登録される
- 静的にバージョンを指定したクラスタ
- Control-Plane: 自動
- Data-Plane:自動 または 手動
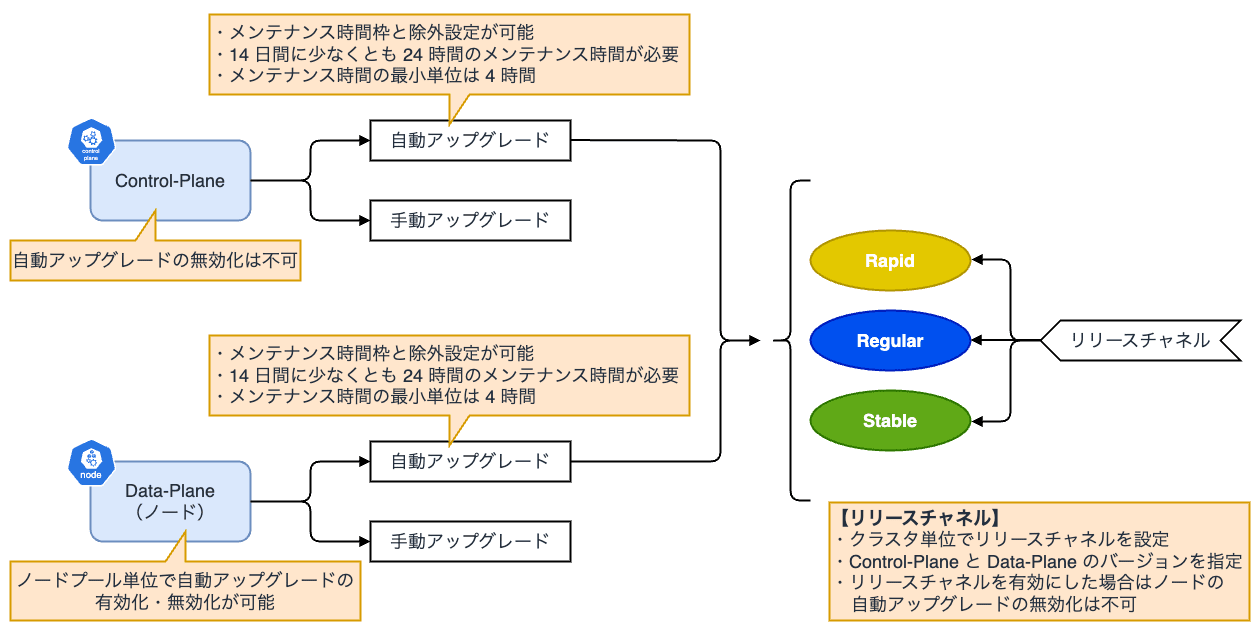
リリースチャネル
リリースチャネルはクラスタのバージョニングとアップグレードを行う際のベストプラクティスを提供する仕組みです。 リリースチャネルに新しいクラスタを登録すると、Google Cloud により、Control-Plane とノードのバージョンおよびアップグレードサイクルが自動的に管理されます。
利用できる機能と更新頻度の異なる以下 3 つのチャネルがあります。

- Rapid
- 最新バージョンが利用可能
- 検証目的で利用を推奨(SLA 対象外)
- Regular
- 機能可用性とリリース安定性バランス
- Stable
- 新機能よりも安定性を優先する場合
ノードプールのアップグレード方式
GKE はノードをノードプールという単位で管理します。 ノードプールのアップグレードは以下 2 種類の方式から選択することができます。
サージアップグレード
サージアップグレードは、ノードを順次新しいバージョンにローリングアップグレードする方式で、デフォルトのアップグレード方式となっています。
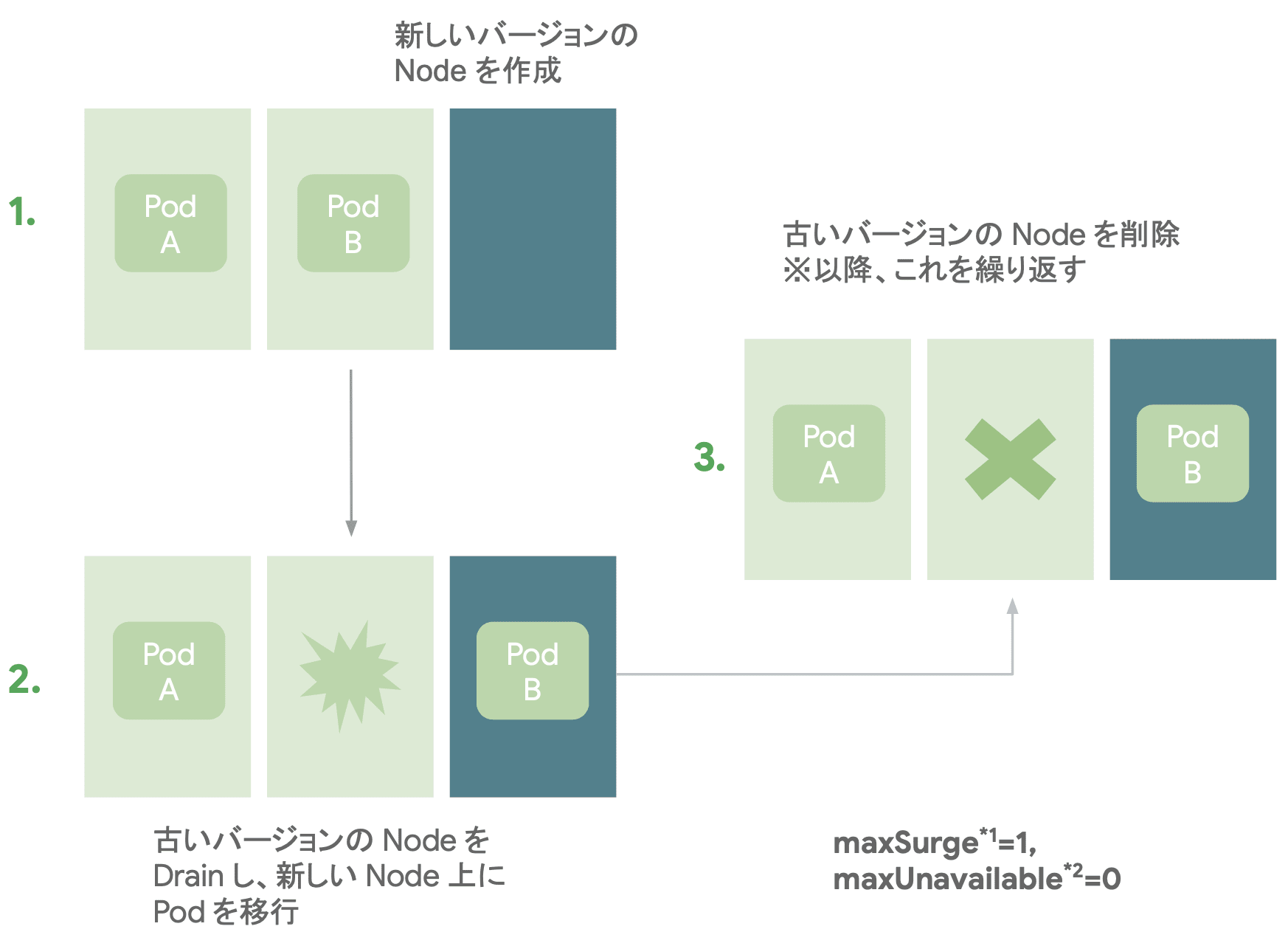
サージアップグレードでは、新しいノードを追加し、ローリング方式でアップグレードしていきます。 Blue/Green 方式に比べて、アップグレード時の追加リソースを少なく構成することが可能です。
また、max-surge-upgrade(アップグレード中に追加可能なノード数)や max-unavailable-upgrade(アップグレード中に使用不可になるノード数)を指定することで、アップグレード時のノードの同時実行数等を調整することができます。
なお、Autopilot の場合は、強制的にサージ方式によるアップグレードが行われます。
Blue/Green アップグレード
Blue/Green アップグレードは、新旧 2 つのバージョンノードを維持したままアップグレードを行う方式です。
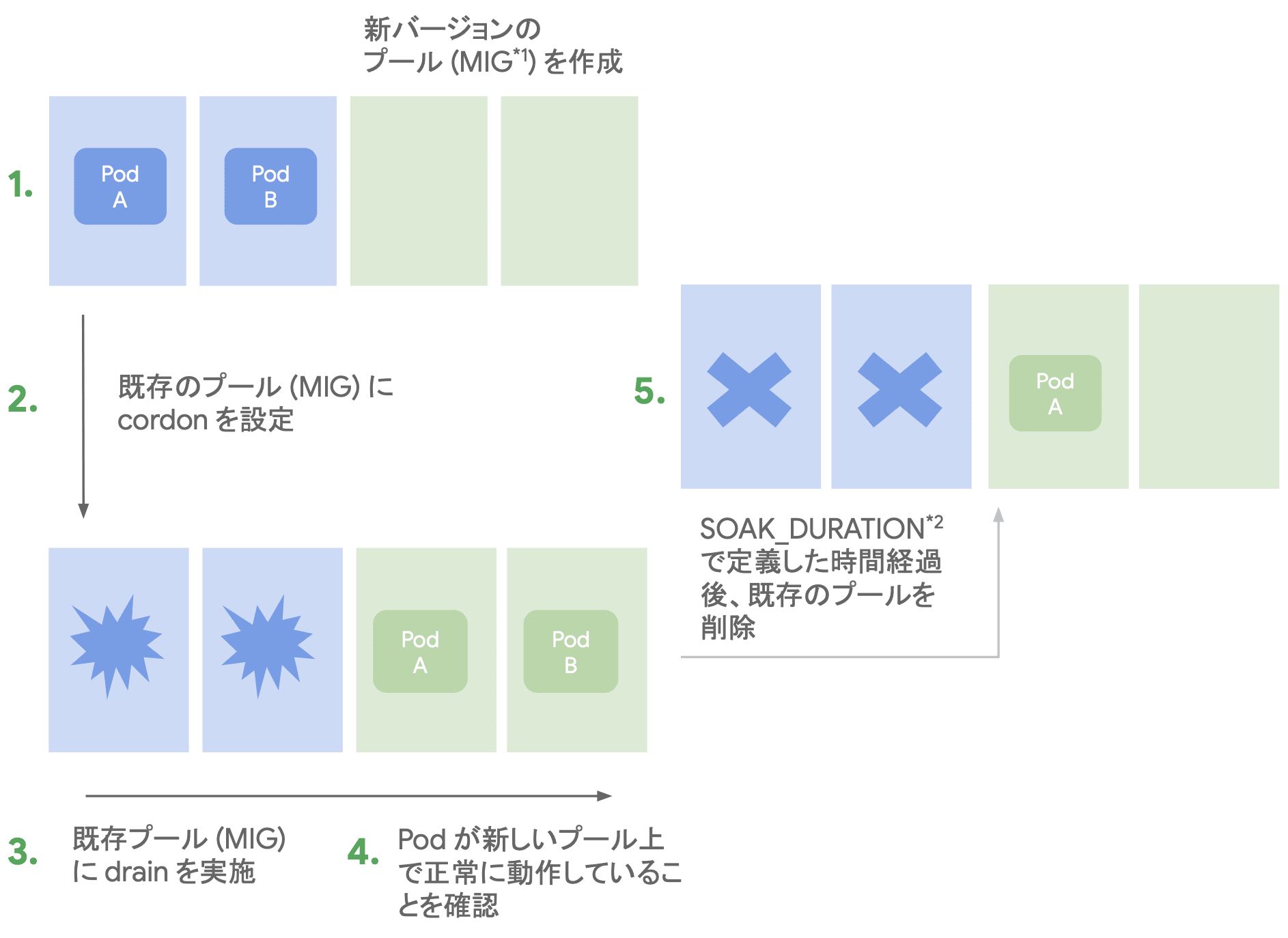
Blue/Green アップグレードでは、ノードレベルの Blue/Green アップグレードの一連の手順を自動的に実行します。 サージ方式に比べて、トラブル発生時のロールバックを迅速に行うことが可能です。
ただし、一時的にノード数が 2 倍に増加するため、事前のクォータ引き上げや、十分なリソース確保が必要になります。
3. アップグレードタイミングの制御
クラスタ管理者の意図しないタイミングでアップグレードが開始されると、思わぬサービスダウンを招いたり、アプリケーションの要求に対応できなくなる可能性があります。 GKE にはこのような事態を避けるべく、自動化されたクラスタアップグレードのタイミングを制御したり、実行順序を管理したりする機能が用意されています。
メンテナンス時間枠と除外
GKE では、アップグレードが実行される時間帯をメンテナンスウィンドウとして設定でき、運用サービスの重要なイベント時のアップグレードを避けることができます。
また、特定の期間にアップグレードを除外する設定も可能で、最大 180 日間アップグレードを停止することができます。
これにより、業務やサービスに影響を与えることなく、計画的なアップグレードを実現できます。
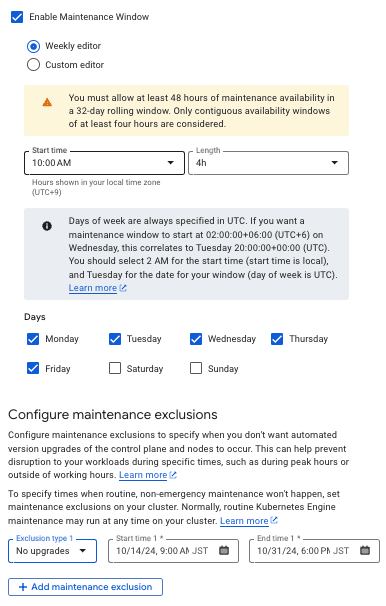
- メンテナンス時間枠
- 自動メンテナンスを 許可する 時間枠
- 32 日周期で最低 48 時間必要
- 各時間枠 4 時間以上連続した時間
- メンテナンス除外
- 自動メンテナンスを 禁止する 時間枠
メンテナンスの除外設定では、自動アップグレードを禁止する期間を制御できます。
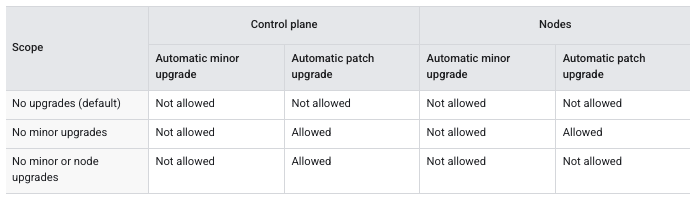
"No upgrades" を指定すると、完全にアップグレードを停止させることができます。 メンテナンスの除外期間は 最大 30 日間 まで設定することが可能ですが、クラスタマイナーバージョンの EOL を超過することはできません。
また、"No minor upgrades" や "minor or node upgrades" を指定すると、Control-Plane や Data-Plane のマイナーバージョンのアップグレードを停止させることができます。 こちらは、メンテナンスの除外期間が 最大 180 日間 まで設定可能ですが、クラスタがリリースチャネルに登録されている必要があります。
ロールアウトシーケンス
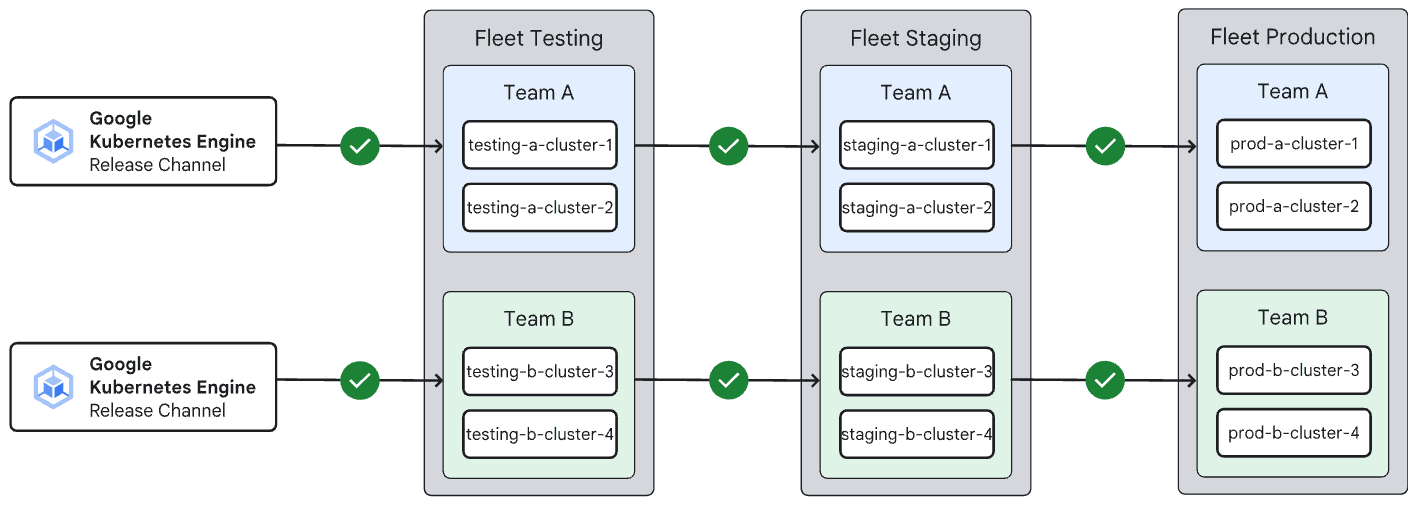
ロールアウトシーケンスは、クラスタ間のアップグレード順序を制御する機能です。 アップグレードするクラスタを環境毎にグルーピングし、依存関係を持たせることで段階的なオートアップグレードが可能になります。
例えば、開発環境 → ステージング環境 → 本番環境の順でクラスタをアップグレードするといった順序管理ができます。

GKE クラスタをアップグレードする場合、最初に Control-Plane がアップグレードされ、次に Data-Plane およびノードがアップグレードされます。 ロールアウトシーケンスを使用すると、Fleet 等のクラスタ内の特定グループのアップグレード順序も管理できます。
例えば、あるグループから次のグループにアップグレードが進む前に GKE が一時停止する時間(ソーク時間) を指定できます。
アップグレード戦略を考える
GKE の実践的なクラスタアップグレード戦略としては、システムの規模や運用方針に応じて以下の 3 つのアップグレード方式を選択できます。
In-place アップグレード
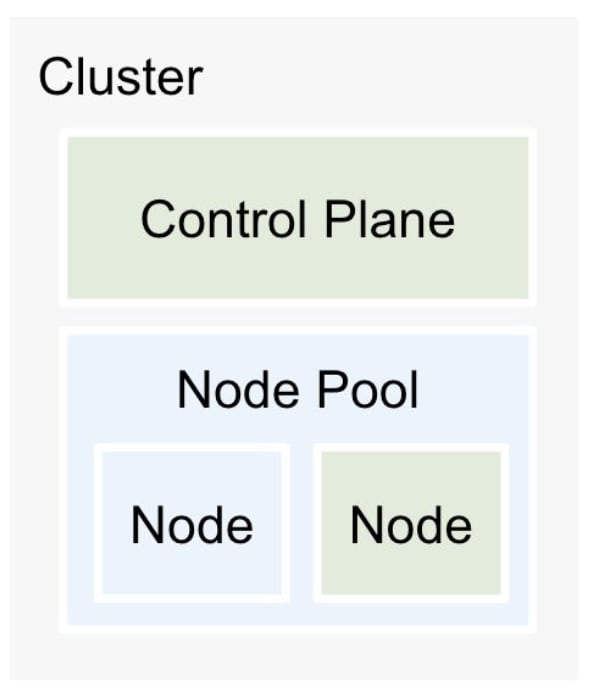
サージアップグレードによって ノード単位でのローリングアップデート を実施します。 In-place 方式は、特に大量のクラスタを運用するケースや、Autopilot を利用している場合に向いています。
また、ロールアウトシーケンスでクラスタ間の依存関係を設定することで、複数クラスタのアップグレードを自動化することができます。
In-place 方式は、他のアップグレード方式と比較して、アップグレードに要する時間が短く、コストも最小限に抑えることができます。
一方で、ノードを一つずつアップグレードするため、トラブル発生時のロールバックに時間が掛かるという懸念点もあります。
ノードプール Blue/Green アップグレード
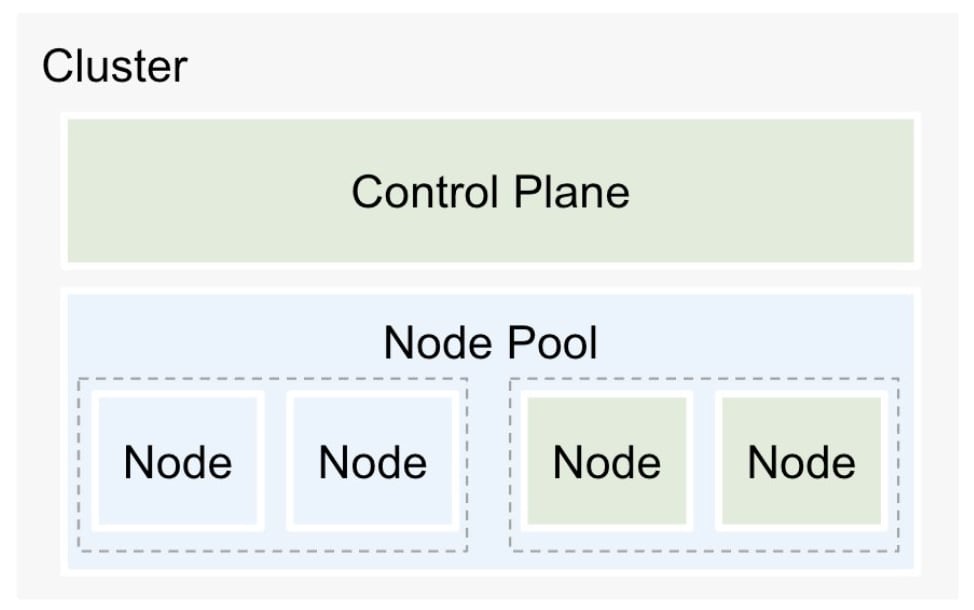
アップグレードを開始すると、新バージョンを利用するノードを追加して正常稼働を確認するまで、古いバージョンを利用するノードを維持します。 ノードプール単位での Blue/Green アップグレード は、安定性とコストのバランスが程よく取れた方式となっており、特に GKE Standard を利用している場合に向いています。
また、Blue/Green アップグレードにおいて、手動で新規のノードプールを作成してワークロードを移行することも可能です。
Blue/Green アップグレードは、一時的に新旧両方のバージョンで併存稼働させるため、問題が発生した場合は即座にロールバックすることが可能です。
一方で、ノードプールはアップグレードのタイミングで最大 2 倍になるため、In-place 方式と比較すると、コストが高く、アップグレードに掛かる時間も長くなります。
クラスタ Blue/Green アップグレード
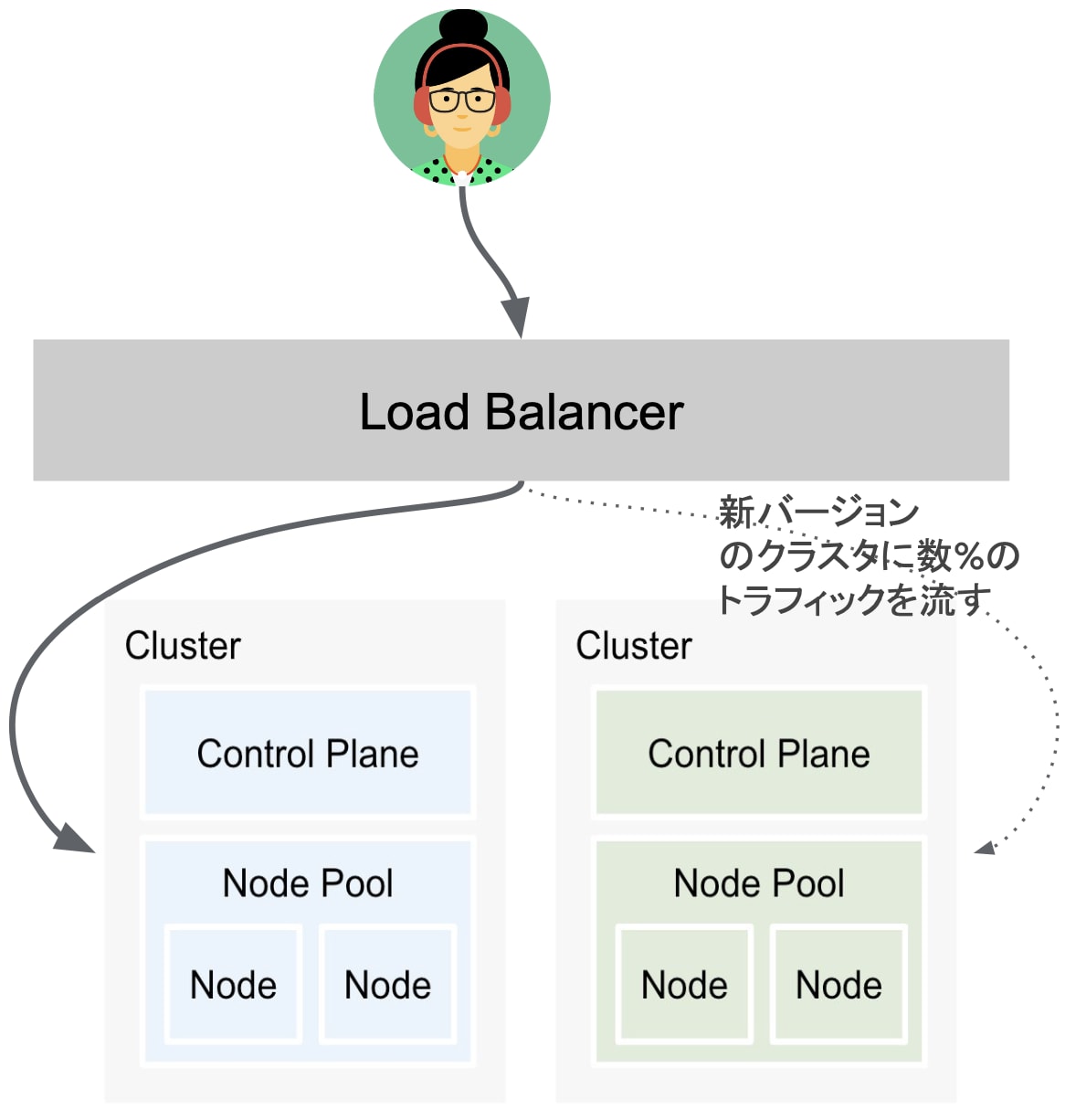
新しいクラスタを準備して段階的にトラフィックを切り替えるアップグレード方式です。
クラスタ単位での Blue/Green アップグレード は、Control-Plane も含めたロールバックやカナリアアップグレードの実現等、最も安全面に特化した方法で、特に大規模なアップグレードやリスク回避が必要な場面で効果的です。 複数クラスタ間のトラフィックを Multi-cluster Gateway 等で制御し、重み付けや、リクエストヘッダに基づいたトラフィックルーティングが可能です。
例えば、クラスタ作成時点でしか変更ができないパラメータを使用したい場合や、特定のマイナーバージョンをスキップしたい場合に有効な手法です。
クラスタレベルの Blue/Green アップグレードは、クラスタ自体を 2 つ用意するため最もコストが高く最も複雑な方法となります。
アップグレードに付随する推奨設定
クラスタアップグレードに関連して以下の戦略・設定を講じることで、アップグレードの影響を受けにくい環境を構築できます。
リリースチャネルへの登録
前述の通り、アップグレードの自動化に伴い、リリースチャネルにクラスタを登録しておくことが推奨されています。 クラスタにリリースチャネルを設定しておくことで、Google Cloud が提供する安定性や機能追加に基づいた適切なバージョンが適用されます。
一定期間安定したバージョンを維持したい場合は「Stable」を選択することで、アップグレードの予測性を向上させることが可能です。
また、メンテナンスの除外設定を設けることで、最大 180 日間アップグレードを停止できるため、事前の準備期間を設けることができます。
リージョナルクラスタの利用
GKE クラスタが単一ゾーンのみで稼働している場合、ゾーン障害の影響を直接受けることになります。 そのため、Control-Plane が複数のリージョンに分散される、リージョナルクラスタとして構築することで、可用性が向上します。 加えて、リージョナルクラスタは、アップグレード中も継続して Kubernetes API へアクセスすることが可能となります。
特に高可用性が求められる環境では、リージョナルクラスタの選択が強く推奨されます。
ノードプールの分割
用途や要件に応じてノードプールを分割することで、ワークロードに対して適切なリソースを割り当てることができます。
また、ノードのアップグレードは、ノードプール単位で実施できるため、タイミングやノードアップグレード方式を柔軟に選択できます。
メンテナンスウィンドウの設定
メンテナンスウィンドウを設けることで、運用サービスのゴールデンタイム等を考慮して、最も影響が少ない時間帯にアップグレードを実施することができます。
PDB の設定
PDB(Pod Disruption Budget) は、主にマニフェストとして定義し、ワークロードに対して適用する Kubernetes ネイティブの設定項目です。 PDB を Deployment リソースに付与しておくことで、アップグレード中の Pod 数を制御し、最小限のレプリカを維持することが保証されます。
また、PDB が設定されていると、Kubernetes ポリシに沿ってノードをドレインするように構成することができます。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: example-pdb
namespace: example-namespace
spec:
maxUnavailable: 50%
selector:
matchLabels:
app: example-deployment
この PDB 設定の例では、Pod の中断がレプリカ数の最大 50% まで許可されます。
また、Pod を Graceful Shutdown するべく、preStop フックや terminationGracePeriodSeconds を設定しておくことで、アップグレード時の入れ替えのタイミングや、やむを得ず Pod が中断される際に、十分な猶予を持たせてから終了させることができます。
通常、Pod は SIGTERM を受信すると即座に Terminating 状態となります。 preStop フックを設定しておくことで、SIGTERM を受信してから許容するまでの猶予期間を設けることができます。
また、terminationGracePeriodSeconds は SIGKILL を受け入れるまでの待機時間を設けることができ、デフォルトで 30 秒に設定されています。
apiVersion: v1
kind: Pod
metadata:
name: sample-app
spec:
terminationGracePeriodSeconds: 60
containers:
- name: app-container
image: my-app-image
lifecycle:
preStop:
exec:
command: ['/bin/sh', '-c', "echo 'Shutting down...' && sleep 5"]
この例では、Pod が SIGTERM を受信すると、"Shutting down..." というメッセージを標準出力に表示して 5 秒間待機します。 アプリケーションはこの間に既存コネクションの切断といった適切な終了処理を実行します。 SIGTERM 受信後 60 秒経過すると、Pod は SIGKILL を受信して完全に削除されます。
Readiness probe / Liveness probe の設定
Readiness probe と Liveness probe はいずれもコンテナのヘルスチェックを行い、適切に処理を管理するための仕組みです。
Readiness probe はコンテナがトラフィックを受け入れる準備ができているかどうかを判断します。 Readiness probe が失敗すると、該当 Pod は Service エンドポイントから削除され、新規リクエストを受け付けなくなります。
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
Liveness probe はコンテナが正常に動作し続けているかどうかを検証します。 Liveness probe が失敗すると、Kubernetes はその Pod を強制的に再起動します。
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 10
periodSeconds: 15
| Readiness probe | Liveness probe | |
|---|---|---|
| 目的 | アプリがリクエストを受ける準備ができているか確認 | アプリが正常に動作し続けているか確認 |
| 失敗時の動作 | Service から除外(リクエストを受け付けなくなる) | コンテナを強制再起動 |
| 復帰後の動作 | Ready 状態に戻ると自動的に Service のルーティングリストに追加 | コンテナが再起動され、正常に起動すれば問題解決 |
Pod Affinity / Pod Anti-Affinity の設定
Kubernetes の Affinity とは、Pod またはノードの配置を制御するための仕組みです。 特に、安全なクラスタアップグレードを実現する上で、Pod Affinity または Pod Anti-Affinity ルールを設けておくことが推奨されます。
Pod Affinity を適用すると、特定の Pod を同一のノードやゾーン内に配置することができます。 Pod Affinity は、主に高速なデータ通信が必要なアプリケーションを同じノードに配置するために利用されます。
affinity:
podAffinity: ## Pod Affinity
requiredDuringSchedulingIgnoredDuringExecution: ## Pod スケジューリング時に強制適用
- labelSelector:
matchLabels:
app: my-app ## 一緒に配置する Pod のラベル
topologyKey: 'kubernetes.io/hostname' ## 配置先ノードの kubernetes.io/hostname ラベル
また、Pod Anti-Affinity を使用すると、特定の Pod が同一ノードやゾーンに重ならないように配置することができます。 Pod Anti-Affinity は、特に高可用性を確保するために、レプリカを異なるノードに分散配置する際に利用されます。
affinity:
podAntiAffinity: ## Pod Anti-Affinity
requiredDuringSchedulingIgnoredDuringExecution: ## Pod スケジューリング時に強制適用
- labelSelector:
matchLabels:
app: my-app ## Pod Anti-Affinity を適用する Pod のラベル
topologyKey: 'kubernetes.io/hostname' ## ノードの kubernetes.io/hostname ラベルを指定して Pod が重ならないように配置
例えば、ノードのアップグレードを実施した際に、同一ノード内に Pod が存在すると、一時的にサービスが停止する可能性があります。 このような場合に、Pod Anti-Affinity を使用すれば、異なるノードにレプリカを配置することができるため、単一のノードが停止しても残りのレプリカが稼働し続けるため、Pod の可用性を維持できます。
まとめ
今回のブログでは GKE のクラスタアップグレード戦略について、Google Cloud が推奨している機能や設定事項をざっくりとまとめてみました。
GKE のアップグレードは、運用の継続性と安定性を維持するために不可欠なプロセスとなります。 GKE が提供する自動化機能やベストプラクティスを取り入れることで、アップグレードのリスクを軽減し、安全かつ効率的に作業を進めることが期待できます。
クラスタ管理者には、運用しているサービスや組織体制等を考慮して最適なアップグレード戦略を選択することが要求されるため、豊富な関連機能をキャッチアップしておくことが重要になります。